feat: merge develop (#123)
* Support hybrid vector retrieval * Enable figures and table reading in Azure DI * Retrieve with multi-modal * Fix mixing up table * Add txt loader * Add Anthropic Chat * Raising error when retrieving help file * Allow same filename for different people if private is True * Allow declaring extra LLM vendors * Show chunks on the File page * Allow elasticsearch to get more docs * Fix Cohere response (#86) * Fix Cohere response * Remove Adobe pdfservice from dependency kotaemon doesn't rely more pdfservice for its core functionality, and pdfservice uses very out-dated dependency that causes conflict. --------- Co-authored-by: trducng <trungduc1992@gmail.com> * Add confidence score (#87) * Save question answering data as a log file * Save the original information besides the rewritten info * Export Cohere relevance score as confidence score * Fix style check * Upgrade the confidence score appearance (#90) * Highlight the relevance score * Round relevance score. Get key from config instead of env * Cohere return all scores * Display relevance score for image * Remove columns and rows in Excel loader which contains all NaN (#91) * remove columns and rows which contains all NaN * back to multiple joiner options * Fix style --------- Co-authored-by: linhnguyen-cinnamon <cinmc0019@CINMC0019-LinhNguyen.local> Co-authored-by: trducng <trungduc1992@gmail.com> * Track retriever state * Bump llama-index version 0.10 * feat/save-azuredi-mhtml-to-markdown (#93) * feat/save-azuredi-mhtml-to-markdown * fix: replace os.path to pathlib change theflow.settings * refactor: base on pre-commit * chore: move the func of saving content markdown above removed_spans --------- Co-authored-by: jacky0218 <jacky0218@github.com> * fix: losing first chunk (#94) * fix: losing first chunk. * fix: update the method of preventing losing chunks --------- Co-authored-by: jacky0218 <jacky0218@github.com> * fix: adding the base64 image in markdown (#95) * feat: more chunk info on UI * fix: error when reindexing files * refactor: allow more information exception trace when using gpt4v * feat: add excel reader that treats each worksheet as a document * Persist loader information when indexing file * feat: allow hiding unneeded setting panels * feat: allow specific timezone when creating conversation * feat: add more confidence score (#96) * Allow a list of rerankers * Export llm reranking score instead of filter with boolean * Get logprobs from LLMs * Rename cohere reranking score * Call 2 rerankers at once * Run QA pipeline for each chunk to get qa_score * Display more relevance scores * Define another LLMScoring instead of editing the original one * Export logprobs instead of probs * Call LLMScoring * Get qa_score only in the final answer * feat: replace text length with token in file list * ui: show index name instead of id in the settings * feat(ai): restrict the vision temperature * fix(ui): remove the misleading message about non-retrieved evidences * feat(ui): show the reasoning name and description in the reasoning setting page * feat(ui): show version on the main windows * feat(ui): show default llm name in the setting page * fix(conf): append the result of doc in llm_scoring (#97) * fix: constraint maximum number of images * feat(ui): allow filter file by name in file list page * Fix exceeding token length error for OpenAI embeddings by chunking then averaging (#99) * Average embeddings in case the text exceeds max size * Add docstring * fix: Allow empty string when calling embedding * fix: update trulens LLM ranking score for retrieval confidence, improve citation (#98) * Round when displaying not by default * Add LLMTrulens reranking model * Use llmtrulensscoring in pipeline * fix: update UI display for trulen score --------- Co-authored-by: taprosoft <tadashi@cinnamon.is> * feat: add question decomposition & few-shot rewrite pipeline (#89) * Create few-shot query-rewriting. Run and display the result in info_panel * Fix style check * Put the functions to separate modules * Add zero-shot question decomposition * Fix fewshot rewriting * Add default few-shot examples * Fix decompose question * Fix importing rewriting pipelines * fix: update decompose logic in fullQA pipeline --------- Co-authored-by: taprosoft <tadashi@cinnamon.is> * fix: add encoding utf-8 when save temporal markdown in vectorIndex (#101) * fix: improve retrieval pipeline and relevant score display (#102) * fix: improve retrieval pipeline by extending first round top_k with multiplier * fix: minor fix * feat: improve UI default settings and add quick switch option for pipeline * fix: improve agent logics (#103) * fix: improve agent progres display * fix: update retrieval logic * fix: UI display * fix: less verbose debug log * feat: add warning message for low confidence * fix: LLM scoring enabled by default * fix: minor update logics * fix: hotfix image citation * feat: update docx loader for handle merged table cells + handle zip file upload (#104) * feat: update docx loader for handle merged table cells * feat: handle zip file * refactor: pre-commit * fix: escape text in download UI * feat: optimize vector store query db (#105) * feat: optimize vector store query db * feat: add file_id to chroma metadatas * feat: remove unnecessary logs and update migrate script * feat: iterate through file index * fix: remove unused code --------- Co-authored-by: taprosoft <tadashi@cinnamon.is> * fix: add openai embedidng exponential back-off * fix: update import download_loader * refactor: codespell * fix: update some default settings * fix: update installation instruction * fix: default chunk length in simple QA * feat: add share converstation feature and enable retrieval history (#108) * feat: add share converstation feature and enable retrieval history * fix: update share conversation UI --------- Co-authored-by: taprosoft <tadashi@cinnamon.is> * fix: allow exponential backoff for failed OCR call (#109) * fix: update default prompt when no retrieval is used * fix: create embedding for long image chunks * fix: add exception handling for additional table retriever * fix: clean conversation & file selection UI * fix: elastic search with empty doc_ids * feat: add thumbnail PDF reader for quick multimodal QA * feat: add thumbnail handling logic in indexing * fix: UI text update * fix: PDF thumb loader page number logic * feat: add quick indexing pipeline and update UI * feat: add conv name suggestion * fix: minor UI change * feat: citation in thread * fix: add conv name suggestion in regen * chore: add assets for usage doc * chore: update usage doc * feat: pdf viewer (#110) * feat: update pdfviewer * feat: update missing files * fix: update rendering logic of infor panel * fix: improve thumbnail retrieval logic * fix: update PDF evidence rendering logic * fix: remove pdfjs built dist * fix: reduce thumbnail evidence count * chore: update gitignore * fix: add js event on chat msg select * fix: update css for viewer * fix: add env var for PDFJS prebuilt * fix: move language setting to reasoning utils --------- Co-authored-by: phv2312 <kat87yb@gmail.com> Co-authored-by: trducng <trungduc1992@gmail.com> * feat: graph rag (#116) * fix: reload server when add/delete index * fix: rework indexing pipeline to be able to disable vectorstore and splitter if needed * feat: add graphRAG index with plot view * fix: update requirement for graphRAG and lighten unnecessary packages * feat: add knowledge network index (#118) * feat: add Knowledge Network index * fix: update reader mode setting for knet * fix: update init knet * fix: update collection name to index pipeline * fix: missing req --------- Co-authored-by: jeff52415 <jeff.yang@cinnamon.is> * fix: update info panel return for graphrag * fix: retriever setting graphrag * feat: local llm settings (#122) * feat: expose context length as reasoning setting to better fit local models * fix: update context length setting for agents * fix: rework threadpool llm call * fix: fix improve indexing logic * fix: fix improve UI * feat: add lancedb * fix: improve lancedb logic * feat: add lancedb vectorstore * fix: lighten requirement * fix: improve lanceDB vs * fix: improve UI * fix: openai retry * fix: update reqs * fix: update launch command * feat: update Dockerfile * feat: add plot history * fix: update default config * fix: remove verbose print * fix: update default setting * fix: update gradio plot return * fix: default gradio tmp * fix: improve lancedb docstore * fix: fix question decompose pipeline * feat: add multimodal reader in UI * fix: udpate docs * fix: update default settings & docker build * fix: update app startup * chore: update documentation * chore: update README * chore: update README --------- Co-authored-by: trducng <trungduc1992@gmail.com> * chore: update README * chore: update README --------- Co-authored-by: trducng <trungduc1992@gmail.com> Co-authored-by: cin-ace <ace@cinnamon.is> Co-authored-by: Linh Nguyen <70562198+linhnguyen-cinnamon@users.noreply.github.com> Co-authored-by: linhnguyen-cinnamon <cinmc0019@CINMC0019-LinhNguyen.local> Co-authored-by: cin-jacky <101088014+jacky0218@users.noreply.github.com> Co-authored-by: jacky0218 <jacky0218@github.com> Co-authored-by: kan_cin <kan@cinnamon.is> Co-authored-by: phv2312 <kat87yb@gmail.com> Co-authored-by: jeff52415 <jeff.yang@cinnamon.is>
13
.dockerignore
Normal file
|
|
@ -0,0 +1,13 @@
|
|||
.github/
|
||||
.git/
|
||||
.mypy_cache/
|
||||
__pycache__/
|
||||
ktem_app_data/
|
||||
env/
|
||||
.pre-commit-config.yaml
|
||||
.commitlintrc
|
||||
.gitignore
|
||||
.gitattributes
|
||||
README.md
|
||||
*.zip
|
||||
*.sh
|
||||
25
.env
|
|
@ -1,8 +1,8 @@
|
|||
# settings for OpenAI
|
||||
OPENAI_API_BASE=https://api.openai.com/v1
|
||||
OPENAI_API_KEY=
|
||||
OPENAI_CHAT_MODEL=gpt-3.5-turbo
|
||||
OPENAI_EMBEDDINGS_MODEL=text-embedding-ada-002
|
||||
OPENAI_API_KEY=openai_key
|
||||
OPENAI_CHAT_MODEL=gpt-4o
|
||||
OPENAI_EMBEDDINGS_MODEL=text-embedding-3-small
|
||||
|
||||
# settings for Azure OpenAI
|
||||
AZURE_OPENAI_ENDPOINT=
|
||||
|
|
@ -15,4 +15,21 @@ AZURE_OPENAI_EMBEDDINGS_DEPLOYMENT=text-embedding-ada-002
|
|||
COHERE_API_KEY=
|
||||
|
||||
# settings for local models
|
||||
LOCAL_MODEL=
|
||||
LOCAL_MODEL=llama3.1:8b
|
||||
LOCAL_MODEL_EMBEDDINGS=nomic-embed-text
|
||||
|
||||
# settings for GraphRAG
|
||||
GRAPHRAG_API_KEY=openai_key
|
||||
GRAPHRAG_LLM_MODEL=gpt-4o-mini
|
||||
GRAPHRAG_EMBEDDING_MODEL=text-embedding-3-small
|
||||
|
||||
# settings for Azure DI
|
||||
AZURE_DI_ENDPOINT=
|
||||
AZURE_DI_CREDENTIAL=
|
||||
|
||||
# settings for Adobe API
|
||||
PDF_SERVICES_CLIENT_ID=
|
||||
PDF_SERVICES_CLIENT_SECRET=
|
||||
|
||||
# settings for PDF.js
|
||||
PDFJS_VERSION_DIST="pdfjs-4.0.379-dist"
|
||||
|
|
|
|||
1
.gitignore
vendored
|
|
@ -471,3 +471,4 @@ doc_env/
|
|||
|
||||
# application data
|
||||
ktem_app_data/
|
||||
gradio_tmp/
|
||||
|
|
|
|||
37
Dockerfile
Normal file
|
|
@ -0,0 +1,37 @@
|
|||
# syntax=docker/dockerfile:1.0.0-experimental
|
||||
FROM python:3.10-slim as base_image
|
||||
|
||||
# for additional file parsers
|
||||
|
||||
# tesseract-ocr \
|
||||
# tesseract-ocr-jpn \
|
||||
# libsm6 \
|
||||
# libxext6 \
|
||||
# ffmpeg \
|
||||
|
||||
RUN apt update -qqy \
|
||||
&& apt install -y \
|
||||
ssh git \
|
||||
gcc g++ \
|
||||
poppler-utils \
|
||||
libpoppler-dev \
|
||||
&& \
|
||||
apt-get clean && \
|
||||
apt-get autoremove
|
||||
|
||||
ENV PYTHONDONTWRITEBYTECODE=1
|
||||
ENV PYTHONUNBUFFERED=1
|
||||
ENV PYTHONIOENCODING=UTF-8
|
||||
|
||||
WORKDIR /app
|
||||
|
||||
|
||||
FROM base_image as dev
|
||||
|
||||
COPY . /app
|
||||
RUN --mount=type=ssh pip install -e "libs/kotaemon[all]"
|
||||
RUN --mount=type=ssh pip install -e "libs/ktem"
|
||||
RUN pip install graphrag future
|
||||
RUN pip install "pdfservices-sdk@git+https://github.com/niallcm/pdfservices-python-sdk.git@bump-and-unfreeze-requirements"
|
||||
|
||||
ENTRYPOINT ["gradio", "app.py"]
|
||||
206
README.md
|
|
@ -1,12 +1,12 @@
|
|||
# kotaemon
|
||||
|
||||
An open-source tool for chatting with your documents. Built with both end users and
|
||||
An open-source clean & customizable RAG UI for chatting with your documents. Built with both end users and
|
||||
developers in mind.
|
||||
|
||||
https://github.com/Cinnamon/kotaemon/assets/25688648/815ecf68-3a02-4914-a0dd-3f8ec7e75cd9
|
||||

|
||||
|
||||
[Source Code](https://github.com/Cinnamon/kotaemon) |
|
||||
[Live Demo](https://huggingface.co/spaces/cin-model/kotaemon-public)
|
||||
[Live Demo](https://huggingface.co/spaces/taprosoft/kotaemon) |
|
||||
[Source Code](https://github.com/Cinnamon/kotaemon)
|
||||
|
||||
[User Guide](https://cinnamon.github.io/kotaemon/) |
|
||||
[Developer Guide](https://cinnamon.github.io/kotaemon/development/) |
|
||||
|
|
@ -14,20 +14,23 @@ https://github.com/Cinnamon/kotaemon/assets/25688648/815ecf68-3a02-4914-a0dd-3f8
|
|||
|
||||
[](https://www.python.org/downloads/release/python-31013/)
|
||||
[](https://github.com/psf/black)
|
||||
<a href="https://hub.docker.com/r/taprosoft/kotaemon" target="_blank">
|
||||
<img src="https://img.shields.io/badge/docker_pull-kotaemon:v1.0-brightgreen" alt="docker pull taprosoft/kotaemon:v1.0"></a>
|
||||
[](https://codeium.com)
|
||||
|
||||
This project would like to appeal to both end users who want to do QA on their
|
||||
documents and developers who want to build their own QA pipeline.
|
||||
## Introduction
|
||||
|
||||
This project serves as a functional RAG UI for both end users who want to do QA on their
|
||||
documents and developers who want to build their own RAG pipeline.
|
||||
|
||||
- For end users:
|
||||
- A local Question Answering UI for RAG-based QA.
|
||||
- A clean & minimalistic UI for RAG-based QA.
|
||||
- Supports LLM API providers (OpenAI, AzureOpenAI, Cohere, etc) and local LLMs
|
||||
(currently only GGUF format is supported via `llama-cpp-python`).
|
||||
- Easy installation scripts, no environment setup required.
|
||||
(via `ollama` and `llama-cpp-python`).
|
||||
- Easy installation scripts.
|
||||
- For developers:
|
||||
- A framework for building your own RAG-based QA pipeline.
|
||||
- See your RAG pipeline in action with the provided UI (built with Gradio).
|
||||
- Share your pipeline so that others can use it.
|
||||
- A framework for building your own RAG-based document QA pipeline.
|
||||
- Customize and see your RAG pipeline in action with the provided UI (built with Gradio).
|
||||
|
||||
```yml
|
||||
+----------------------------------------------------------------------------+
|
||||
|
|
@ -45,78 +48,128 @@ documents and developers who want to build their own QA pipeline.
|
|||
```
|
||||
|
||||
This repository is under active development. Feedback, issues, and PRs are highly
|
||||
appreciated. Your input is valuable as it helps us persuade our business guys to support
|
||||
open source.
|
||||
appreciated.
|
||||
|
||||
## Key Features
|
||||
|
||||
- **Host your own document QA (RAG) web-UI**. Support multi-user login, organize your files in private / public collections, collaborate and share your favorite chat with others.
|
||||
|
||||
- **Organize your LLM & Embedding models**. Support both local LLMs & popular API providers (OpenAI, Azure, Ollama, Groq).
|
||||
|
||||
- **Hybrid RAG pipeline**. Sane default RAG pipeline with hybrid (full-text & vector) retriever + re-ranking to ensure best retrieval quality.
|
||||
|
||||
- **Multi-modal QA support**. Perform Question Answering on multiple documents with figures & tables support. Support multi-modal document parsing (selectable options on UI).
|
||||
|
||||
- **Advance citations with document preview**. By default the system will provide detailed citations to ensure the correctness of LLM answers. View your citations (incl. relevant score) directly in the _in-browser PDF viewer_ with highlights. Warning when retrieval pipeline return low relevant articles.
|
||||
|
||||
- **Support complex reasoning methods**. Use question decomposition to answer your complex / multi-hop question. Support agent-based reasoning with ReAct, ReWOO and other agents.
|
||||
|
||||
- **Configurable settings UI**. You can adjust most important aspects of retrieval & generation process on the UI (incl. prompts).
|
||||
|
||||
- **Extensible**. Being built on Gradio, you are free to customize / add any UI elements as you like. Also, we aim to support multiple strategies for document indexing & retrieval. `GraphRAG` indexing pipeline is provided as an example.
|
||||
|
||||

|
||||
|
||||
## Installation
|
||||
|
||||
### For end users
|
||||
|
||||
This document is intended for developers. If you just want to install and use the app as
|
||||
it, please follow the [User Guide](https://cinnamon.github.io/kotaemon/).
|
||||
it is, please follow the non-technical [User Guide](https://cinnamon.github.io/kotaemon/) (WIP).
|
||||
|
||||
### For developers
|
||||
|
||||
```shell
|
||||
# Create a environment
|
||||
python -m venv kotaemon-env
|
||||
#### With Docker (recommended)
|
||||
|
||||
# Activate the environment
|
||||
source kotaemon-env/bin/activate
|
||||
- Use this command to launch the server
|
||||
|
||||
# Install the package
|
||||
pip install git+https://github.com/Cinnamon/kotaemon.git
|
||||
```
|
||||
docker run \
|
||||
-e GRADIO_SERVER_NAME=0.0.0.0 \
|
||||
-e GRADIO_SERVER_PORT=7860 \
|
||||
-p 7860:7860 -it --rm \
|
||||
taprosoft/kotaemon:v1.0
|
||||
```
|
||||
|
||||
### For Contributors
|
||||
Navigate to `http://localhost:7860/` to access the web UI.
|
||||
|
||||
#### Without Docker
|
||||
|
||||
- Clone and install required packages on a fresh python environment.
|
||||
|
||||
```shell
|
||||
# Clone the repo
|
||||
git clone git@github.com:Cinnamon/kotaemon.git
|
||||
# optional (setup env)
|
||||
conda create -n kotaemon python=3.10
|
||||
conda activate kotaemon
|
||||
|
||||
# Create a environment
|
||||
python -m venv kotaemon-env
|
||||
|
||||
# Activate the environment
|
||||
source kotaemon-env/bin/activate
|
||||
# clone this repo
|
||||
git clone https://github.com/Cinnamon/kotaemon
|
||||
cd kotaemon
|
||||
|
||||
# Install the package in editable mode
|
||||
pip install -e "libs/kotaemon[all]"
|
||||
pip install -e "libs/ktem"
|
||||
pip install -e "."
|
||||
|
||||
# Setup pre-commit
|
||||
pre-commit install
|
||||
```
|
||||
|
||||
## Creating your application
|
||||
- View and edit your environment variables (API keys, end-points) in `.env`.
|
||||
|
||||
In order to create your own application, you need to prepare these files:
|
||||
- (Optional) To enable in-browser PDF_JS viewer, download [PDF_JS_DIST](https://github.com/mozilla/pdf.js/releases/download/v4.0.379/pdfjs-4.0.379-dist.zip) and extract it to `libs/ktem/ktem/assets/prebuilt`
|
||||
|
||||
<img src="docs/images/pdf-viewer-setup.png" alt="pdf-setup" width="300">
|
||||
|
||||
- Start the web server:
|
||||
|
||||
```shell
|
||||
python app.py
|
||||
```
|
||||
|
||||
The app will be automatically launched in your browser.
|
||||
|
||||
Default username / password are: `admin` / `admin`. You can setup additional users directly on the UI.
|
||||
|
||||

|
||||
|
||||
## Customize your application
|
||||
|
||||
By default, all application data are stored in `./ktem_app_data` folder. You can backup or copy this folder to move your installation to a new machine.
|
||||
|
||||
For advance users or specific use-cases, you can customize those files:
|
||||
|
||||
- `flowsettings.py`
|
||||
- `app.py`
|
||||
- `.env` (Optional)
|
||||
- `.env`
|
||||
|
||||
### `flowsettings.py`
|
||||
|
||||
This file contains the configuration of your application. You can use the example
|
||||
[here](https://github.com/Cinnamon/kotaemon/blob/main/libs/ktem/flowsettings.py) as the
|
||||
[here](flowsettings.py) as the
|
||||
starting point.
|
||||
|
||||
### `app.py`
|
||||
<details>
|
||||
|
||||
This file is where you create your Gradio app object. This can be as simple as:
|
||||
<summary>Notable settings</summary>
|
||||
|
||||
```python
|
||||
from ktem.main import App
|
||||
```
|
||||
# setup your preferred document store (with full-text search capabilities)
|
||||
KH_DOCSTORE=(Elasticsearch | LanceDB | SimpleFileDocumentStore)
|
||||
|
||||
app = App()
|
||||
demo = app.make()
|
||||
demo.launch()
|
||||
# setup your preferred vectorstore (for vector-based search)
|
||||
KH_VECTORSTORE=(ChromaDB | LanceDB
|
||||
|
||||
# Enable / disable multimodal QA
|
||||
KH_REASONINGS_USE_MULTIMODAL=True
|
||||
|
||||
# Setup your new reasoning pipeline or modify existing one.
|
||||
KH_REASONINGS = [
|
||||
"ktem.reasoning.simple.FullQAPipeline",
|
||||
"ktem.reasoning.simple.FullDecomposeQAPipeline",
|
||||
"ktem.reasoning.react.ReactAgentPipeline",
|
||||
"ktem.reasoning.rewoo.RewooAgentPipeline",
|
||||
]
|
||||
)
|
||||
```
|
||||
|
||||
### `.env` (Optional)
|
||||
</details>
|
||||
|
||||
### `.env`
|
||||
|
||||
This file provides another way to configure your models and credentials.
|
||||
|
||||
|
|
@ -159,18 +212,22 @@ AZURE_OPENAI_EMBEDDINGS_DEPLOYMENT=text-embedding-ada-002
|
|||
|
||||
#### Local models
|
||||
|
||||
- Pros:
|
||||
- Privacy. Your documents will be stored and process locally.
|
||||
- Choices. There are a wide range of LLMs in terms of size, domain, language to choose
|
||||
from.
|
||||
- Cost. It's free.
|
||||
- Cons:
|
||||
- Quality. Local models are much smaller and thus have lower generative quality than
|
||||
paid APIs.
|
||||
- Speed. Local models are deployed using your machine so the processing speed is
|
||||
limited by your hardware.
|
||||
##### Using ollama OpenAI compatible server
|
||||
|
||||
##### Find and download a LLM
|
||||
Install [ollama](https://github.com/ollama/ollama) and start the application.
|
||||
|
||||
Pull your model (e.g):
|
||||
|
||||
```
|
||||
ollama pull llama3.1:8b
|
||||
ollama pull nomic-embed-text
|
||||
```
|
||||
|
||||
Set the model names on web UI and make it as default.
|
||||
|
||||

|
||||
|
||||
##### Using GGUF with llama-cpp-python
|
||||
|
||||
You can search and download a LLM to be ran locally from the [Hugging Face
|
||||
Hub](https://huggingface.co/models). Currently, these model formats are supported:
|
||||
|
|
@ -187,33 +244,26 @@ Here are some recommendations and their size in memory:
|
|||
- [Qwen1.5-1.8B-Chat-GGUF](https://huggingface.co/Qwen/Qwen1.5-1.8B-Chat-GGUF/resolve/main/qwen1_5-1_8b-chat-q8_0.gguf?download=true):
|
||||
around 2 GB
|
||||
|
||||
##### Enable local models
|
||||
Add a new LlamaCpp model with the provided model name on the web uI.
|
||||
|
||||
To add a local model to the model pool, set the `LOCAL_MODEL` variable in the `.env`
|
||||
file to the path of the model file.
|
||||
|
||||
```shell
|
||||
LOCAL_MODEL=<full path to your model file>
|
||||
```
|
||||
|
||||
Here is how to get the full path of your model file:
|
||||
|
||||
- On Windows 11: right click the file and select `Copy as Path`.
|
||||
</details>
|
||||
|
||||
## Start your application
|
||||
## Adding your own RAG pipeline
|
||||
|
||||
Simply run the following command:
|
||||
#### Custom reasoning pipeline
|
||||
|
||||
```shell
|
||||
python app.py
|
||||
```
|
||||
First, check the default pipeline implementation in
|
||||
[here](libs/ktem/ktem/reasoning/simple.py). You can make quick adjustment to how the default QA pipeline work.
|
||||
|
||||
The app will be automatically launched in your browser.
|
||||
Next, if you feel comfortable adding new pipeline, add new `.py` implementation in `libs/ktem/ktem/reasoning/` and later include it in `flowssettings` to enable it on the UI.
|
||||
|
||||

|
||||
#### Custom indexing pipeline
|
||||
|
||||
## Customize your application
|
||||
Check sample implementation in `libs/ktem/ktem/index/file/graph`
|
||||
|
||||
(more instruction WIP).
|
||||
|
||||
## Developer guide
|
||||
|
||||
Please refer to the [Developer Guide](https://cinnamon.github.io/kotaemon/development/)
|
||||
for more details.
|
||||
|
|
|
|||
23
app.py
|
|
@ -1,5 +1,24 @@
|
|||
from ktem.main import App
|
||||
import os
|
||||
|
||||
from theflow.settings import settings as flowsettings
|
||||
|
||||
KH_APP_DATA_DIR = getattr(flowsettings, "KH_APP_DATA_DIR", ".")
|
||||
GRADIO_TEMP_DIR = os.getenv("GRADIO_TEMP_DIR", None)
|
||||
# override GRADIO_TEMP_DIR if it's not set
|
||||
if GRADIO_TEMP_DIR is None:
|
||||
GRADIO_TEMP_DIR = os.path.join(KH_APP_DATA_DIR, "gradio_tmp")
|
||||
os.environ["GRADIO_TEMP_DIR"] = GRADIO_TEMP_DIR
|
||||
|
||||
|
||||
from ktem.main import App # noqa
|
||||
|
||||
app = App()
|
||||
demo = app.make()
|
||||
demo.queue().launch(favicon_path=app._favicon, inbrowser=True)
|
||||
demo.queue().launch(
|
||||
favicon_path=app._favicon,
|
||||
inbrowser=True,
|
||||
allowed_paths=[
|
||||
"libs/ktem/ktem/assets",
|
||||
GRADIO_TEMP_DIR,
|
||||
],
|
||||
)
|
||||
|
|
|
|||
|
|
@ -9,3 +9,6 @@ developers in mind.
|
|||
[User Guide](https://cinnamon.github.io/kotaemon/) |
|
||||
[Developer Guide](https://cinnamon.github.io/kotaemon/development/) |
|
||||
[Feedback](https://github.com/Cinnamon/kotaemon/issues)
|
||||
|
||||
[Dark Mode](?__theme=dark) |
|
||||
[Light Mode](?__theme=light)
|
||||
|
|
|
|||
BIN
docs/images/info-panel-scores.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 545 KiB |
BIN
docs/images/models.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 136 KiB |
BIN
docs/images/pdf-viewer-setup.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 38 KiB |
BIN
docs/images/preview-graph.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 288 KiB |
BIN
docs/images/preview.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 566 KiB |
|
|
@ -108,8 +108,8 @@ string rather than a string.
|
|||
## Software infrastructure
|
||||
|
||||
| Infra | Access | Schema | Ref |
|
||||
| ---------------- | ------------- | -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | ---------------------------------------------------------- |
|
||||
| SQL table Source | self.\_Source | - id (int): id of the source (auto)<br>- name (str): the name of the file<br>- path (str): the path of the file<br>- size (int): the file size in bytes<br>- text_length (int): the number of characters in the file (default 0)<br>- date_created (datetime): the time the file is created (auto) | This is SQLALchemy ORM class. Can consult |
|
||||
| ---------------- | ------------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | ---------------------------------------------------------- |
|
||||
| SQL table Source | self.\_Source | - id (int): id of the source (auto)<br>- name (str): the name of the file<br>- path (str): the path of the file<br>- size (int): the file size in bytes<br>- note (dict): allow extra optional information about the file<br>- date_created (datetime): the time the file is created (auto) | This is SQLALchemy ORM class. Can consult |
|
||||
| SQL table Index | self.\_Index | - id (int): id of the index entry (auto)<br>- source_id (int): the id of a file in the Source table<br>- target_id: the id of the segment in docstore or vector store<br>- relation_type (str): if the link is "document" or "vector" | This is SQLAlchemy ORM class |
|
||||
| Vector store | self.\_VS | - self.\_VS.add: add the list of embeddings to the vector store (optionally associate metadata and ids)<br>- self.\_VS.delete: delete vector entries based on ids<br>- self.\_VS.query: get embeddings based on embeddings. | kotaemon > storages > vectorstores > BaseVectorStore |
|
||||
| Doc store | self.\_DS | - self.\_DS.add: add the segments to document stores<br>- self.\_DS.get: get the segments based on id<br>- self.\_DS.get_all: get all segments<br>- self.\_DS.delete: delete segments based on id | kotaemon > storages > docstores > base > BaseDocumentStore |
|
||||
|
|
|
|||
|
|
@ -1,5 +1,3 @@
|
|||
# Basic Usage
|
||||
|
||||
## 1. Add your AI models
|
||||
|
||||
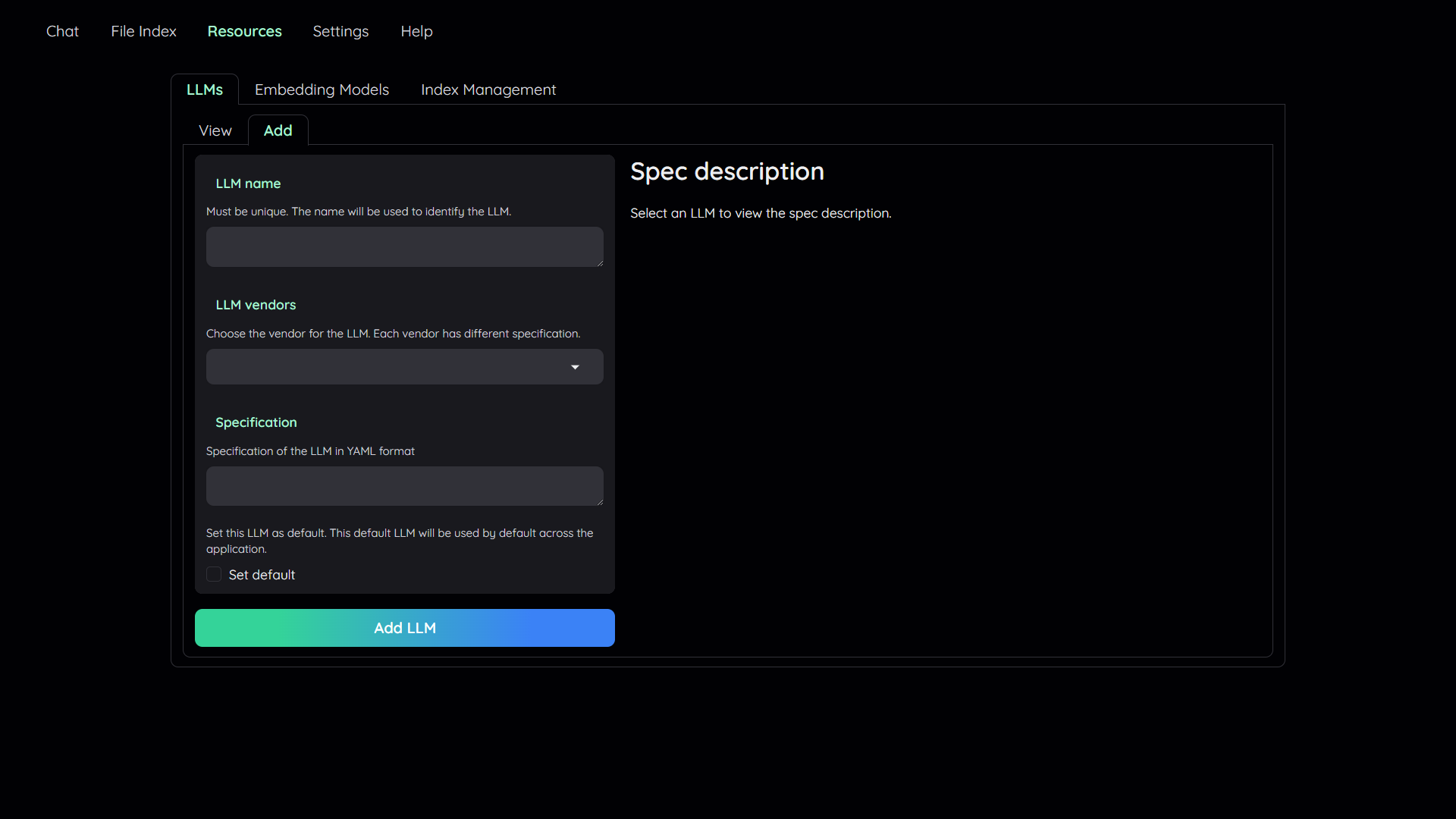
|
||||
|
|
@ -63,12 +61,15 @@ AZURE_OPENAI_EMBEDDINGS_DEPLOYMENT=text-embedding-ada-002 # change to your deplo
|
|||
|
||||
### Local models
|
||||
|
||||
- Pros:
|
||||
Pros:
|
||||
|
||||
- Privacy. Your documents will be stored and process locally.
|
||||
- Choices. There are a wide range of LLMs in terms of size, domain, language to choose
|
||||
from.
|
||||
- Cost. It's free.
|
||||
- Cons:
|
||||
|
||||
Cons:
|
||||
|
||||
- Quality. Local models are much smaller and thus have lower generative quality than
|
||||
paid APIs.
|
||||
- Speed. Local models are deployed using your machine so the processing speed is
|
||||
|
|
@ -136,6 +137,21 @@ Now navigate back to the `Chat` tab. The chat tab is divided into 3 regions:
|
|||
files will be considered during chat.
|
||||
2. Chat Panel
|
||||
- This is where you can chat with the chatbot.
|
||||
3. Information panel
|
||||
- Supporting information such as the retrieved evidence and reference will be
|
||||
3. Information Panel
|
||||
|
||||
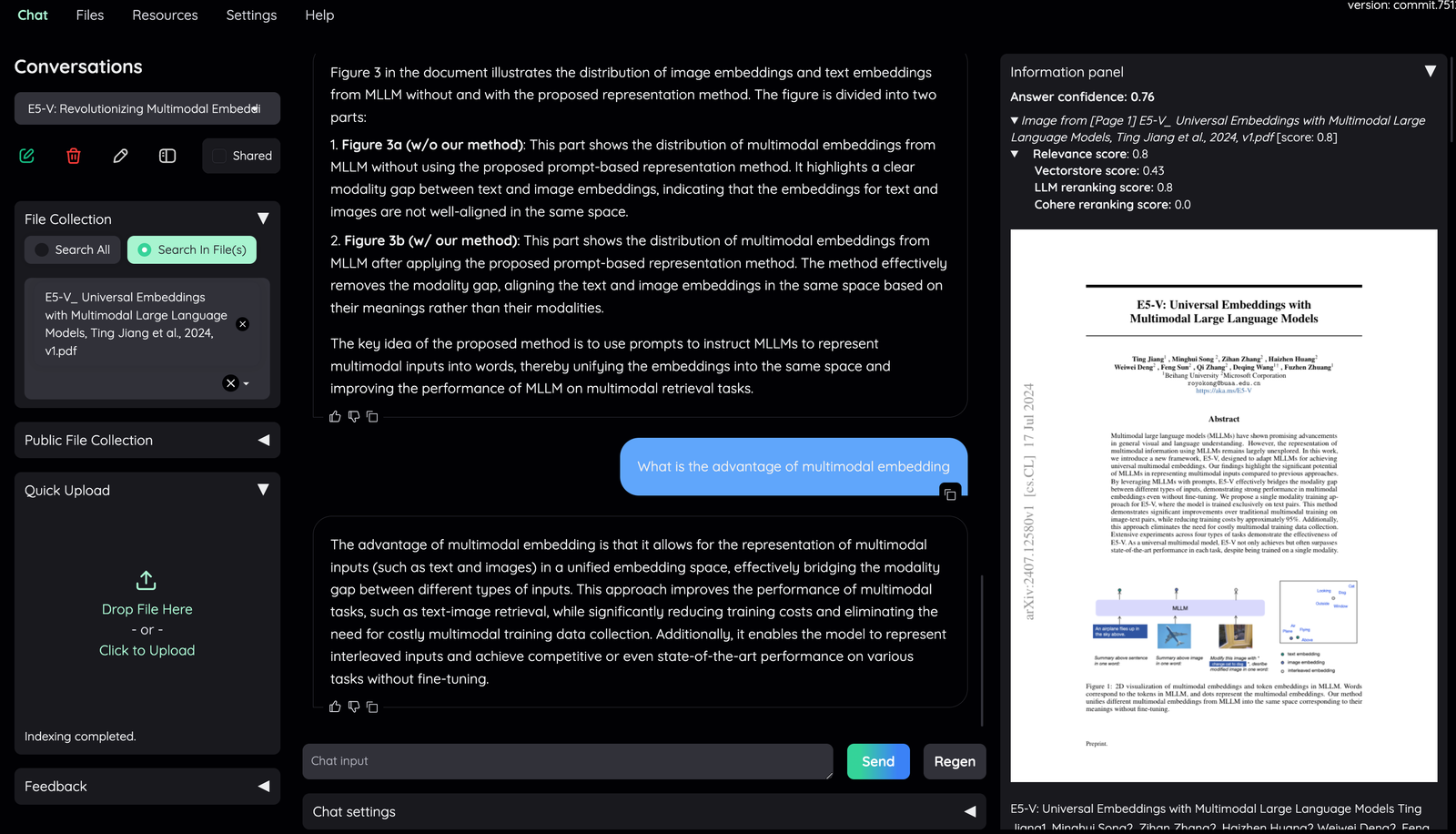
|
||||
|
||||
- Supporting information such as the retrieved evidence and reference will be
|
||||
displayed here.
|
||||
- Direct citation for the answer produced by the LLM is highlighted.
|
||||
- The confidence score of the answer and relevant scores of evidences are displayed to quickly assess the quality of the answer and retrieved content.
|
||||
|
||||
- Meaning of the score displayed:
|
||||
- **Answer confidence**: answer confidence level from the LLM model.
|
||||
- **Relevance score**: overall relevant score between evidence and user question.
|
||||
- **Vectorstore score**: relevant score from vector embedding similarity calculation (show `full-text search` if retrieved from full-text search DB).
|
||||
- **LLM relevant score**: relevant score from LLM model (which judge relevancy between question and evidence using specific prompt).
|
||||
- **Reranking score**: relevant score from Cohere [reranking model](https://cohere.com/rerank).
|
||||
|
||||
Generally, the score quality is `LLM relevant score` > `Reranking score` > `Vectorscore`.
|
||||
By default, overall relevance score is taken directly from LLM relevant score. Evidences are sorted based on their overall relevance score and whether they have citation or not.
|
||||
|
|
|
|||
153
flowsettings.py
|
|
@ -15,7 +15,7 @@ this_dir = Path(this_file).parent
|
|||
# change this if your app use a different name
|
||||
KH_PACKAGE_NAME = "kotaemon_app"
|
||||
|
||||
KH_APP_VERSION = os.environ.get("KH_APP_VERSION", None)
|
||||
KH_APP_VERSION = config("KH_APP_VERSION", "local")
|
||||
if not KH_APP_VERSION:
|
||||
try:
|
||||
# Caution: This might produce the wrong version
|
||||
|
|
@ -33,8 +33,21 @@ KH_APP_DATA_DIR.mkdir(parents=True, exist_ok=True)
|
|||
KH_USER_DATA_DIR = KH_APP_DATA_DIR / "user_data"
|
||||
KH_USER_DATA_DIR.mkdir(parents=True, exist_ok=True)
|
||||
|
||||
# doc directory
|
||||
KH_DOC_DIR = this_dir / "docs"
|
||||
# markdown output directory
|
||||
KH_MARKDOWN_OUTPUT_DIR = KH_APP_DATA_DIR / "markdown_cache_dir"
|
||||
KH_MARKDOWN_OUTPUT_DIR.mkdir(parents=True, exist_ok=True)
|
||||
|
||||
# chunks output directory
|
||||
KH_CHUNKS_OUTPUT_DIR = KH_APP_DATA_DIR / "chunks_cache_dir"
|
||||
KH_CHUNKS_OUTPUT_DIR.mkdir(parents=True, exist_ok=True)
|
||||
|
||||
# zip output directory
|
||||
KH_ZIP_OUTPUT_DIR = KH_APP_DATA_DIR / "zip_cache_dir"
|
||||
KH_ZIP_OUTPUT_DIR.mkdir(parents=True, exist_ok=True)
|
||||
|
||||
# zip input directory
|
||||
KH_ZIP_INPUT_DIR = KH_APP_DATA_DIR / "zip_cache_dir_in"
|
||||
KH_ZIP_INPUT_DIR.mkdir(parents=True, exist_ok=True)
|
||||
|
||||
# HF models can be big, let's store them in the app data directory so that it's easier
|
||||
# for users to manage their storage.
|
||||
|
|
@ -42,24 +55,30 @@ KH_DOC_DIR = this_dir / "docs"
|
|||
os.environ["HF_HOME"] = str(KH_APP_DATA_DIR / "huggingface")
|
||||
os.environ["HF_HUB_CACHE"] = str(KH_APP_DATA_DIR / "huggingface")
|
||||
|
||||
COHERE_API_KEY = config("COHERE_API_KEY", default="")
|
||||
# doc directory
|
||||
KH_DOC_DIR = this_dir / "docs"
|
||||
|
||||
KH_MODE = "dev"
|
||||
KH_FEATURE_USER_MANAGEMENT = False
|
||||
KH_FEATURE_USER_MANAGEMENT = True
|
||||
KH_USER_CAN_SEE_PUBLIC = None
|
||||
KH_FEATURE_USER_MANAGEMENT_ADMIN = str(
|
||||
config("KH_FEATURE_USER_MANAGEMENT_ADMIN", default="admin")
|
||||
)
|
||||
KH_FEATURE_USER_MANAGEMENT_PASSWORD = str(
|
||||
config("KH_FEATURE_USER_MANAGEMENT_PASSWORD", default="XsdMbe8zKP8KdeE@")
|
||||
config("KH_FEATURE_USER_MANAGEMENT_PASSWORD", default="admin")
|
||||
)
|
||||
KH_ENABLE_ALEMBIC = False
|
||||
KH_DATABASE = f"sqlite:///{KH_USER_DATA_DIR / 'sql.db'}"
|
||||
KH_FILESTORAGE_PATH = str(KH_USER_DATA_DIR / "files")
|
||||
|
||||
KH_DOCSTORE = {
|
||||
"__type__": "kotaemon.storages.SimpleFileDocumentStore",
|
||||
# "__type__": "kotaemon.storages.ElasticsearchDocumentStore",
|
||||
# "__type__": "kotaemon.storages.SimpleFileDocumentStore",
|
||||
"__type__": "kotaemon.storages.LanceDBDocumentStore",
|
||||
"path": str(KH_USER_DATA_DIR / "docstore"),
|
||||
}
|
||||
KH_VECTORSTORE = {
|
||||
# "__type__": "kotaemon.storages.LanceDBVectorStore",
|
||||
"__type__": "kotaemon.storages.ChromaVectorStore",
|
||||
"path": str(KH_USER_DATA_DIR / "vectorstore"),
|
||||
}
|
||||
|
|
@ -83,8 +102,6 @@ if config("AZURE_OPENAI_API_KEY", default="") and config(
|
|||
"timeout": 20,
|
||||
},
|
||||
"default": False,
|
||||
"accuracy": 5,
|
||||
"cost": 5,
|
||||
}
|
||||
if config("AZURE_OPENAI_EMBEDDINGS_DEPLOYMENT", default=""):
|
||||
KH_EMBEDDINGS["azure"] = {
|
||||
|
|
@ -110,71 +127,66 @@ if config("OPENAI_API_KEY", default=""):
|
|||
"base_url": config("OPENAI_API_BASE", default="")
|
||||
or "https://api.openai.com/v1",
|
||||
"api_key": config("OPENAI_API_KEY", default=""),
|
||||
"model": config("OPENAI_CHAT_MODEL", default="") or "gpt-3.5-turbo",
|
||||
"timeout": 10,
|
||||
"model": config("OPENAI_CHAT_MODEL", default="gpt-3.5-turbo"),
|
||||
"timeout": 20,
|
||||
},
|
||||
"default": False,
|
||||
"default": True,
|
||||
}
|
||||
if len(KH_EMBEDDINGS) < 1:
|
||||
KH_EMBEDDINGS["openai"] = {
|
||||
"spec": {
|
||||
"__type__": "kotaemon.embeddings.OpenAIEmbeddings",
|
||||
"base_url": config("OPENAI_API_BASE", default="")
|
||||
or "https://api.openai.com/v1",
|
||||
"base_url": config("OPENAI_API_BASE", default="https://api.openai.com/v1"),
|
||||
"api_key": config("OPENAI_API_KEY", default=""),
|
||||
"model": config(
|
||||
"OPENAI_EMBEDDINGS_MODEL", default="text-embedding-ada-002"
|
||||
)
|
||||
or "text-embedding-ada-002",
|
||||
),
|
||||
"timeout": 10,
|
||||
},
|
||||
"default": False,
|
||||
}
|
||||
|
||||
if config("LOCAL_MODEL", default=""):
|
||||
KH_LLMS["local"] = {
|
||||
"spec": {
|
||||
"__type__": "kotaemon.llms.EndpointChatLLM",
|
||||
"endpoint_url": "http://localhost:31415/v1/chat/completions",
|
||||
},
|
||||
"default": False,
|
||||
"cost": 0,
|
||||
}
|
||||
if len(KH_EMBEDDINGS) < 1:
|
||||
KH_EMBEDDINGS["local"] = {
|
||||
"spec": {
|
||||
"__type__": "kotaemon.embeddings.EndpointEmbeddings",
|
||||
"endpoint_url": "http://localhost:31415/v1/embeddings",
|
||||
},
|
||||
"default": False,
|
||||
"cost": 0,
|
||||
}
|
||||
|
||||
if len(KH_EMBEDDINGS) < 1:
|
||||
KH_EMBEDDINGS["local-bge-base-en-v1.5"] = {
|
||||
"spec": {
|
||||
"__type__": "kotaemon.embeddings.FastEmbedEmbeddings",
|
||||
"model_name": "BAAI/bge-base-en-v1.5",
|
||||
"context_length": 8191,
|
||||
},
|
||||
"default": True,
|
||||
}
|
||||
|
||||
KH_REASONINGS = ["ktem.reasoning.simple.FullQAPipeline"]
|
||||
if config("LOCAL_MODEL", default=""):
|
||||
KH_LLMS["ollama"] = {
|
||||
"spec": {
|
||||
"__type__": "kotaemon.llms.ChatOpenAI",
|
||||
"base_url": "http://localhost:11434/v1/",
|
||||
"model": config("LOCAL_MODEL", default="llama3.1:8b"),
|
||||
},
|
||||
"default": False,
|
||||
}
|
||||
KH_EMBEDDINGS["ollama"] = {
|
||||
"spec": {
|
||||
"__type__": "kotaemon.embeddings.OpenAIEmbeddings",
|
||||
"base_url": "http://localhost:11434/v1/",
|
||||
"model": config("LOCAL_MODEL_EMBEDDINGS", default="nomic-embed-text"),
|
||||
},
|
||||
"default": False,
|
||||
}
|
||||
|
||||
KH_EMBEDDINGS["local-bge-en"] = {
|
||||
"spec": {
|
||||
"__type__": "kotaemon.embeddings.FastEmbedEmbeddings",
|
||||
"model_name": "BAAI/bge-base-en-v1.5",
|
||||
},
|
||||
"default": False,
|
||||
}
|
||||
|
||||
KH_REASONINGS = [
|
||||
"ktem.reasoning.simple.FullQAPipeline",
|
||||
"ktem.reasoning.simple.FullDecomposeQAPipeline",
|
||||
"ktem.reasoning.react.ReactAgentPipeline",
|
||||
"ktem.reasoning.rewoo.RewooAgentPipeline",
|
||||
]
|
||||
KH_REASONINGS_USE_MULTIMODAL = False
|
||||
KH_VLM_ENDPOINT = "{0}/openai/deployments/{1}/chat/completions?api-version={2}".format(
|
||||
config("AZURE_OPENAI_ENDPOINT", default=""),
|
||||
config("OPENAI_VISION_DEPLOYMENT_NAME", default="gpt-4-vision"),
|
||||
config("OPENAI_VISION_DEPLOYMENT_NAME", default="gpt-4o"),
|
||||
config("OPENAI_API_VERSION", default=""),
|
||||
)
|
||||
|
||||
|
||||
SETTINGS_APP = {
|
||||
"lang": {
|
||||
"name": "Language",
|
||||
"value": "en",
|
||||
"choices": [("English", "en"), ("Japanese", "ja")],
|
||||
"component": "dropdown",
|
||||
}
|
||||
}
|
||||
SETTINGS_APP: dict[str, dict] = {}
|
||||
|
||||
|
||||
SETTINGS_REASONING = {
|
||||
|
|
@ -187,17 +199,42 @@ SETTINGS_REASONING = {
|
|||
"lang": {
|
||||
"name": "Language",
|
||||
"value": "en",
|
||||
"choices": [("English", "en"), ("Japanese", "ja")],
|
||||
"choices": [("English", "en"), ("Japanese", "ja"), ("Vietnamese", "vi")],
|
||||
"component": "dropdown",
|
||||
},
|
||||
"max_context_length": {
|
||||
"name": "Max context length (LLM)",
|
||||
"value": 32000,
|
||||
"component": "number",
|
||||
},
|
||||
}
|
||||
|
||||
|
||||
KH_INDEX_TYPES = ["ktem.index.file.FileIndex"]
|
||||
KH_INDEX_TYPES = [
|
||||
"ktem.index.file.FileIndex",
|
||||
"ktem.index.file.graph.GraphRAGIndex",
|
||||
]
|
||||
KH_INDICES = [
|
||||
{
|
||||
"name": "File",
|
||||
"config": {},
|
||||
"config": {
|
||||
"supported_file_types": (
|
||||
".png, .jpeg, .jpg, .tiff, .tif, .pdf, .xls, .xlsx, .doc, .docx, "
|
||||
".pptx, .csv, .html, .mhtml, .txt, .zip"
|
||||
),
|
||||
"private": False,
|
||||
},
|
||||
"index_type": "ktem.index.file.FileIndex",
|
||||
},
|
||||
{
|
||||
"name": "GraphRAG",
|
||||
"config": {
|
||||
"supported_file_types": (
|
||||
".png, .jpeg, .jpg, .tiff, .tif, .pdf, .xls, .xlsx, .doc, .docx, "
|
||||
".pptx, .csv, .html, .mhtml, .txt, .zip"
|
||||
),
|
||||
"private": False,
|
||||
},
|
||||
"index_type": "ktem.index.file.graph.GraphRAGIndex",
|
||||
},
|
||||
]
|
||||
|
|
|
|||
|
|
@ -39,16 +39,11 @@ class ReactAgent(BaseAgent):
|
|||
)
|
||||
max_iterations: int = 5
|
||||
strict_decode: bool = False
|
||||
trim_func: TokenSplitter = TokenSplitter.withx(
|
||||
chunk_size=800,
|
||||
chunk_overlap=0,
|
||||
separator=" ",
|
||||
tokenizer=partial(
|
||||
tiktoken.encoding_for_model("gpt-3.5-turbo").encode,
|
||||
allowed_special=set(),
|
||||
disallowed_special="all",
|
||||
),
|
||||
max_context_length: int = Param(
|
||||
default=3000,
|
||||
help="Max context length for each tool output.",
|
||||
)
|
||||
trim_func: TokenSplitter | None = None
|
||||
|
||||
def _compose_plugin_description(self) -> str:
|
||||
"""
|
||||
|
|
@ -149,14 +144,28 @@ class ReactAgent(BaseAgent):
|
|||
function_map[plugin.name] = plugin
|
||||
return function_map
|
||||
|
||||
def _trim(self, text: str) -> str:
|
||||
def _trim(self, text: str | Document) -> str:
|
||||
"""
|
||||
Trim the text to the maximum token length.
|
||||
"""
|
||||
evidence_trim_func = (
|
||||
self.trim_func
|
||||
if self.trim_func
|
||||
else TokenSplitter(
|
||||
chunk_size=self.max_context_length,
|
||||
chunk_overlap=0,
|
||||
separator=" ",
|
||||
tokenizer=partial(
|
||||
tiktoken.encoding_for_model("gpt-3.5-turbo").encode,
|
||||
allowed_special=set(),
|
||||
disallowed_special="all",
|
||||
),
|
||||
)
|
||||
)
|
||||
if isinstance(text, str):
|
||||
texts = self.trim_func([Document(text=text)])
|
||||
texts = evidence_trim_func([Document(text=text)])
|
||||
elif isinstance(text, Document):
|
||||
texts = self.trim_func([text])
|
||||
texts = evidence_trim_func([text])
|
||||
else:
|
||||
raise ValueError("Invalid text type to trim")
|
||||
trim_text = texts[0].text
|
||||
|
|
|
|||
|
|
@ -39,16 +39,11 @@ class RewooAgent(BaseAgent):
|
|||
examples: dict[str, str | list[str]] = Param(
|
||||
default_callback=lambda _: {}, help="Examples to be used in the agent."
|
||||
)
|
||||
trim_func: TokenSplitter = TokenSplitter.withx(
|
||||
chunk_size=3000,
|
||||
chunk_overlap=0,
|
||||
separator=" ",
|
||||
tokenizer=partial(
|
||||
tiktoken.encoding_for_model("gpt-3.5-turbo").encode,
|
||||
allowed_special=set(),
|
||||
disallowed_special="all",
|
||||
),
|
||||
max_context_length: int = Param(
|
||||
default=3000,
|
||||
help="Max context length for each tool output.",
|
||||
)
|
||||
trim_func: TokenSplitter | None = None
|
||||
|
||||
@Node.auto(depends_on=["planner_llm", "plugins", "prompt_template", "examples"])
|
||||
def planner(self):
|
||||
|
|
@ -248,8 +243,22 @@ class RewooAgent(BaseAgent):
|
|||
return p
|
||||
|
||||
def _trim_evidence(self, evidence: str):
|
||||
evidence_trim_func = (
|
||||
self.trim_func
|
||||
if self.trim_func
|
||||
else TokenSplitter(
|
||||
chunk_size=self.max_context_length,
|
||||
chunk_overlap=0,
|
||||
separator=" ",
|
||||
tokenizer=partial(
|
||||
tiktoken.encoding_for_model("gpt-3.5-turbo").encode,
|
||||
allowed_special=set(),
|
||||
disallowed_special="all",
|
||||
),
|
||||
)
|
||||
)
|
||||
if evidence:
|
||||
texts = self.trim_func([Document(text=evidence)])
|
||||
texts = evidence_trim_func([Document(text=evidence)])
|
||||
evidence = texts[0].text
|
||||
logging.info(f"len (trimmed): {len(evidence)}")
|
||||
return evidence
|
||||
|
|
@ -317,6 +326,14 @@ class RewooAgent(BaseAgent):
|
|||
)
|
||||
|
||||
print("Planner output:", planner_text_output)
|
||||
# output planner to info panel
|
||||
yield AgentOutput(
|
||||
text="",
|
||||
agent_type=self.agent_type,
|
||||
status="thinking",
|
||||
intermediate_steps=[{"planner_log": planner_text_output}],
|
||||
)
|
||||
|
||||
# Work
|
||||
worker_evidences, plugin_cost, plugin_token = self._get_worker_evidence(
|
||||
planner_evidences, evidence_level
|
||||
|
|
@ -326,7 +343,9 @@ class RewooAgent(BaseAgent):
|
|||
worker_log += f"{plan}: {plans[plan]}\n"
|
||||
current_progress = f"{plan}: {plans[plan]}\n"
|
||||
for e in plan_to_es[plan]:
|
||||
worker_log += f"#Action: {planner_evidences.get(e, None)}\n"
|
||||
worker_log += f"{e}: {worker_evidences[e]}\n"
|
||||
current_progress += f"#Action: {planner_evidences.get(e, None)}\n"
|
||||
current_progress += f"{e}: {worker_evidences[e]}\n"
|
||||
|
||||
yield AgentOutput(
|
||||
|
|
|
|||
|
|
@ -1,7 +1,7 @@
|
|||
from typing import AnyStr, Optional, Type
|
||||
from urllib.error import HTTPError
|
||||
|
||||
from langchain.utilities import SerpAPIWrapper
|
||||
from langchain_community.utilities import SerpAPIWrapper
|
||||
from pydantic import BaseModel, Field
|
||||
|
||||
from .base import BaseTool
|
||||
|
|
|
|||
|
|
@ -22,12 +22,16 @@ class LLMTool(BaseTool):
|
|||
)
|
||||
llm: BaseLLM
|
||||
args_schema: Optional[Type[BaseModel]] = LLMArgs
|
||||
dummy_mode: bool = True
|
||||
|
||||
def _run_tool(self, query: AnyStr) -> str:
|
||||
output = None
|
||||
try:
|
||||
if not self.dummy_mode:
|
||||
response = self.llm(query)
|
||||
else:
|
||||
response = None
|
||||
except ValueError:
|
||||
raise ToolException("LLM Tool call failed")
|
||||
output = response.text
|
||||
output = response.text if response else "<->"
|
||||
return output
|
||||
|
|
|
|||
|
|
@ -5,8 +5,8 @@ from typing import TYPE_CHECKING, Any, Literal, Optional, TypeVar
|
|||
from langchain.schema.messages import AIMessage as LCAIMessage
|
||||
from langchain.schema.messages import HumanMessage as LCHumanMessage
|
||||
from langchain.schema.messages import SystemMessage as LCSystemMessage
|
||||
from llama_index.bridge.pydantic import Field
|
||||
from llama_index.schema import Document as BaseDocument
|
||||
from llama_index.core.bridge.pydantic import Field
|
||||
from llama_index.core.schema import Document as BaseDocument
|
||||
|
||||
if TYPE_CHECKING:
|
||||
from haystack.schema import Document as HaystackDocument
|
||||
|
|
@ -38,7 +38,7 @@ class Document(BaseDocument):
|
|||
|
||||
content: Any = None
|
||||
source: Optional[str] = None
|
||||
channel: Optional[Literal["chat", "info", "index", "debug"]] = None
|
||||
channel: Optional[Literal["chat", "info", "index", "debug", "plot"]] = None
|
||||
|
||||
def __init__(self, content: Optional[Any] = None, *args, **kwargs):
|
||||
if content is None:
|
||||
|
|
@ -140,6 +140,7 @@ class LLMInterface(AIMessage):
|
|||
total_cost: float = 0
|
||||
logits: list[list[float]] = Field(default_factory=list)
|
||||
messages: list[AIMessage] = Field(default_factory=list)
|
||||
logprobs: list[float] = []
|
||||
|
||||
|
||||
class ExtractorOutput(Document):
|
||||
|
|
|
|||
|
|
@ -133,9 +133,7 @@ def construct_chat_ui(
|
|||
label="Output file", show_label=True, height=100
|
||||
)
|
||||
export_btn = gr.Button("Export")
|
||||
export_btn.click(
|
||||
func_export_to_excel, inputs=None, outputs=exported_file
|
||||
)
|
||||
export_btn.click(func_export_to_excel, inputs=[], outputs=exported_file)
|
||||
|
||||
with gr.Row():
|
||||
with gr.Column():
|
||||
|
|
|
|||
|
|
@ -91,7 +91,7 @@ def construct_pipeline_ui(
|
|||
save_btn.click(func_save, inputs=params, outputs=history_dataframe)
|
||||
load_params_btn = gr.Button("Reload params")
|
||||
load_params_btn.click(
|
||||
func_load_params, inputs=None, outputs=history_dataframe
|
||||
func_load_params, inputs=[], outputs=history_dataframe
|
||||
)
|
||||
history_dataframe.render()
|
||||
history_dataframe.select(
|
||||
|
|
@ -103,7 +103,7 @@ def construct_pipeline_ui(
|
|||
export_btn = gr.Button(
|
||||
"Export (Result will be in Exported file next to Output)"
|
||||
)
|
||||
export_btn.click(func_export, inputs=None, outputs=exported_file)
|
||||
export_btn.click(func_export, inputs=[], outputs=exported_file)
|
||||
with gr.Row():
|
||||
with gr.Column():
|
||||
if params:
|
||||
|
|
|
|||
|
|
@ -1,5 +1,15 @@
|
|||
from itertools import islice
|
||||
from typing import Optional
|
||||
|
||||
import numpy as np
|
||||
import openai
|
||||
import tiktoken
|
||||
from tenacity import (
|
||||
retry,
|
||||
retry_if_not_exception_type,
|
||||
stop_after_attempt,
|
||||
wait_random_exponential,
|
||||
)
|
||||
from theflow.utils.modules import import_dotted_string
|
||||
|
||||
from kotaemon.base import Param
|
||||
|
|
@ -7,6 +17,24 @@ from kotaemon.base import Param
|
|||
from .base import BaseEmbeddings, Document, DocumentWithEmbedding
|
||||
|
||||
|
||||
def split_text_by_chunk_size(text: str, chunk_size: int) -> list[list[int]]:
|
||||
"""Split the text into chunks of a given size
|
||||
|
||||
Args:
|
||||
text: text to split
|
||||
chunk_size: size of each chunk
|
||||
|
||||
Returns:
|
||||
list of chunks (as tokens)
|
||||
"""
|
||||
encoding = tiktoken.get_encoding("cl100k_base")
|
||||
tokens = iter(encoding.encode(text))
|
||||
result = []
|
||||
while chunk := list(islice(tokens, chunk_size)):
|
||||
result.append(chunk)
|
||||
return result
|
||||
|
||||
|
||||
class BaseOpenAIEmbeddings(BaseEmbeddings):
|
||||
"""Base interface for OpenAI embedding model, using the openai library.
|
||||
|
||||
|
|
@ -32,6 +60,9 @@ class BaseOpenAIEmbeddings(BaseEmbeddings):
|
|||
"Only supported in `text-embedding-3` and later models."
|
||||
),
|
||||
)
|
||||
context_length: Optional[int] = Param(
|
||||
None, help="The maximum context length of the embedding model"
|
||||
)
|
||||
|
||||
@Param.auto(depends_on=["max_retries"])
|
||||
def max_retries_(self):
|
||||
|
|
@ -56,16 +87,42 @@ class BaseOpenAIEmbeddings(BaseEmbeddings):
|
|||
def invoke(
|
||||
self, text: str | list[str] | Document | list[Document], *args, **kwargs
|
||||
) -> list[DocumentWithEmbedding]:
|
||||
input_ = self.prepare_input(text)
|
||||
input_doc = self.prepare_input(text)
|
||||
client = self.prepare_client(async_version=False)
|
||||
resp = self.openai_response(
|
||||
client, input=[_.text if _.text else " " for _ in input_], **kwargs
|
||||
).dict()
|
||||
output_ = sorted(resp["data"], key=lambda x: x["index"])
|
||||
return [
|
||||
DocumentWithEmbedding(embedding=o["embedding"], content=i)
|
||||
for i, o in zip(input_, output_)
|
||||
|
||||
input_: list[str | list[int]] = []
|
||||
splitted_indices = {}
|
||||
for idx, text in enumerate(input_doc):
|
||||
if self.context_length:
|
||||
chunks = split_text_by_chunk_size(text.text or " ", self.context_length)
|
||||
splitted_indices[idx] = (len(input_), len(input_) + len(chunks))
|
||||
input_.extend(chunks)
|
||||
else:
|
||||
splitted_indices[idx] = (len(input_), len(input_) + 1)
|
||||
input_.append(text.text)
|
||||
|
||||
resp = self.openai_response(client, input=input_, **kwargs).dict()
|
||||
output_ = list(sorted(resp["data"], key=lambda x: x["index"]))
|
||||
|
||||
output = []
|
||||
for idx, doc in enumerate(input_doc):
|
||||
embs = output_[splitted_indices[idx][0] : splitted_indices[idx][1]]
|
||||
if len(embs) == 1:
|
||||
output.append(
|
||||
DocumentWithEmbedding(embedding=embs[0]["embedding"], content=doc)
|
||||
)
|
||||
continue
|
||||
|
||||
chunk_lens = [
|
||||
len(_)
|
||||
for _ in input_[splitted_indices[idx][0] : splitted_indices[idx][1]]
|
||||
]
|
||||
vs: list[list[float]] = [_["embedding"] for _ in embs]
|
||||
emb = np.average(vs, axis=0, weights=chunk_lens)
|
||||
emb = emb / np.linalg.norm(emb)
|
||||
output.append(DocumentWithEmbedding(embedding=emb.tolist(), content=doc))
|
||||
|
||||
return output
|
||||
|
||||
async def ainvoke(
|
||||
self, text: str | list[str] | Document | list[Document], *args, **kwargs
|
||||
|
|
@ -118,6 +175,13 @@ class OpenAIEmbeddings(BaseOpenAIEmbeddings):
|
|||
|
||||
return OpenAI(**params)
|
||||
|
||||
@retry(
|
||||
retry=retry_if_not_exception_type(
|
||||
(openai.NotFoundError, openai.BadRequestError)
|
||||
),
|
||||
wait=wait_random_exponential(min=1, max=40),
|
||||
stop=stop_after_attempt(6),
|
||||
)
|
||||
def openai_response(self, client, **kwargs):
|
||||
"""Get the openai response"""
|
||||
params: dict = {
|
||||
|
|
@ -174,6 +238,13 @@ class AzureOpenAIEmbeddings(BaseOpenAIEmbeddings):
|
|||
|
||||
return AzureOpenAI(**params)
|
||||
|
||||
@retry(
|
||||
retry=retry_if_not_exception_type(
|
||||
(openai.NotFoundError, openai.BadRequestError)
|
||||
),
|
||||
wait=wait_random_exponential(min=1, max=40),
|
||||
stop=stop_after_attempt(6),
|
||||
)
|
||||
def openai_response(self, client, **kwargs):
|
||||
"""Get the openai response"""
|
||||
params: dict = {
|
||||
|
|
|
|||
|
|
@ -3,7 +3,7 @@ from __future__ import annotations
|
|||
from abc import abstractmethod
|
||||
from typing import Any, Type
|
||||
|
||||
from llama_index.node_parser.interface import NodeParser
|
||||
from llama_index.core.node_parser.interface import NodeParser
|
||||
|
||||
from kotaemon.base import BaseComponent, Document, RetrievedDocument
|
||||
|
||||
|
|
@ -32,7 +32,7 @@ class LlamaIndexDocTransformerMixin:
|
|||
Example:
|
||||
class TokenSplitter(LlamaIndexMixin, BaseSplitter):
|
||||
def _get_li_class(self):
|
||||
from llama_index.text_splitter import TokenTextSplitter
|
||||
from llama_index.core.text_splitter import TokenTextSplitter
|
||||
return TokenTextSplitter
|
||||
|
||||
To use this mixin, please:
|
||||
|
|
|
|||
|
|
@ -15,7 +15,7 @@ class TitleExtractor(LlamaIndexDocTransformerMixin, BaseDocParser):
|
|||
super().__init__(llm=llm, nodes=nodes, **params)
|
||||
|
||||
def _get_li_class(self):
|
||||
from llama_index.extractors import TitleExtractor
|
||||
from llama_index.core.extractors import TitleExtractor
|
||||
|
||||
return TitleExtractor
|
||||
|
||||
|
|
@ -30,6 +30,6 @@ class SummaryExtractor(LlamaIndexDocTransformerMixin, BaseDocParser):
|
|||
super().__init__(llm=llm, summaries=summaries, **params)
|
||||
|
||||
def _get_li_class(self):
|
||||
from llama_index.extractors import SummaryExtractor
|
||||
from llama_index.core.extractors import SummaryExtractor
|
||||
|
||||
return SummaryExtractor
|
||||
|
|
|
|||
|
|
@ -1,27 +1,42 @@
|
|||
from pathlib import Path
|
||||
from typing import Type
|
||||
|
||||
from llama_index.readers import PDFReader
|
||||
from llama_index.readers.base import BaseReader
|
||||
from decouple import config
|
||||
from llama_index.core.readers.base import BaseReader
|
||||
from theflow.settings import settings as flowsettings
|
||||
|
||||
from kotaemon.base import BaseComponent, Document, Param
|
||||
from kotaemon.indices.extractors import BaseDocParser
|
||||
from kotaemon.indices.splitters import BaseSplitter, TokenSplitter
|
||||
from kotaemon.loaders import (
|
||||
AdobeReader,
|
||||
AzureAIDocumentIntelligenceLoader,
|
||||
DirectoryReader,
|
||||
HtmlReader,
|
||||
MathpixPDFReader,
|
||||
MhtmlReader,
|
||||
OCRReader,
|
||||
PandasExcelReader,
|
||||
PDFThumbnailReader,
|
||||
UnstructuredReader,
|
||||
)
|
||||
|
||||
unstructured = UnstructuredReader()
|
||||
adobe_reader = AdobeReader()
|
||||
azure_reader = AzureAIDocumentIntelligenceLoader(
|
||||
endpoint=str(config("AZURE_DI_ENDPOINT", default="")),
|
||||
credential=str(config("AZURE_DI_CREDENTIAL", default="")),
|
||||
cache_dir=getattr(flowsettings, "KH_MARKDOWN_OUTPUT_DIR", None),
|
||||
)
|
||||
adobe_reader.vlm_endpoint = azure_reader.vlm_endpoint = getattr(
|
||||
flowsettings, "KH_VLM_ENDPOINT", ""
|
||||
)
|
||||
|
||||
|
||||
KH_DEFAULT_FILE_EXTRACTORS: dict[str, BaseReader] = {
|
||||
".xlsx": PandasExcelReader(),
|
||||
".docx": unstructured,
|
||||
".pptx": unstructured,
|
||||
".xls": unstructured,
|
||||
".doc": unstructured,
|
||||
".html": HtmlReader(),
|
||||
|
|
@ -31,7 +46,7 @@ KH_DEFAULT_FILE_EXTRACTORS: dict[str, BaseReader] = {
|
|||
".jpg": unstructured,
|
||||
".tiff": unstructured,
|
||||
".tif": unstructured,
|
||||
".pdf": PDFReader(),
|
||||
".pdf": PDFThumbnailReader(),
|
||||
}
|
||||
|
||||
|
||||
|
|
|
|||
|
|
@ -103,7 +103,9 @@ class CitationPipeline(BaseComponent):
|
|||
print("CitationPipeline: invoking LLM")
|
||||
llm_output = self.get_from_path("llm").invoke(messages, **llm_kwargs)
|
||||
print("CitationPipeline: finish invoking LLM")
|
||||
if not llm_output.messages:
|
||||
if not llm_output.messages or not llm_output.additional_kwargs.get(
|
||||
"tool_calls"
|
||||
):
|
||||
return None
|
||||
function_output = llm_output.additional_kwargs["tool_calls"][0]["function"][
|
||||
"arguments"
|
||||
|
|
|
|||
|
|
@ -1,5 +1,13 @@
|
|||
from .base import BaseReranking
|
||||
from .cohere import CohereReranking
|
||||
from .llm import LLMReranking
|
||||
from .llm_scoring import LLMScoring
|
||||
from .llm_trulens import LLMTrulensScoring
|
||||
|
||||
__all__ = ["CohereReranking", "LLMReranking", "BaseReranking"]
|
||||
__all__ = [
|
||||
"CohereReranking",
|
||||
"LLMReranking",
|
||||
"LLMScoring",
|
||||
"BaseReranking",
|
||||
"LLMTrulensScoring",
|
||||
]
|
||||
|
|
|
|||
|
|
@ -1,6 +1,6 @@
|
|||
from __future__ import annotations
|
||||
|
||||
import os
|
||||
from decouple import config
|
||||
|
||||
from kotaemon.base import Document
|
||||
|
||||
|
|
@ -9,8 +9,7 @@ from .base import BaseReranking
|
|||
|
||||
class CohereReranking(BaseReranking):
|
||||
model_name: str = "rerank-multilingual-v2.0"
|
||||
cohere_api_key: str = os.environ.get("COHERE_API_KEY", "")
|
||||
top_k: int = 1
|
||||
cohere_api_key: str = config("COHERE_API_KEY", "")
|
||||
|
||||
def run(self, documents: list[Document], query: str) -> list[Document]:
|
||||
"""Use Cohere Reranker model to re-order documents
|
||||
|
|
@ -22,6 +21,10 @@ class CohereReranking(BaseReranking):
|
|||
"Please install Cohere " "`pip install cohere` to use Cohere Reranking"
|
||||
)
|
||||
|
||||
if not self.cohere_api_key:
|
||||
print("Cohere API key not found. Skipping reranking.")
|
||||
return documents
|
||||
|
||||
cohere_client = cohere.Client(self.cohere_api_key)
|
||||
compressed_docs: list[Document] = []
|
||||
|
||||
|
|
@ -29,12 +32,13 @@ class CohereReranking(BaseReranking):
|
|||
return compressed_docs
|
||||
|
||||
_docs = [d.content for d in documents]
|
||||
results = cohere_client.rerank(
|
||||
model=self.model_name, query=query, documents=_docs, top_n=self.top_k
|
||||
response = cohere_client.rerank(
|
||||
model=self.model_name, query=query, documents=_docs
|
||||
)
|
||||
for r in results:
|
||||
print("Cohere score", [r.relevance_score for r in response.results])
|
||||
for r in response.results:
|
||||
doc = documents[r.index]
|
||||
doc.metadata["relevance_score"] = r.relevance_score
|
||||
doc.metadata["cohere_reranking_score"] = r.relevance_score
|
||||
compressed_docs.append(doc)
|
||||
|
||||
return compressed_docs
|
||||
|
|
|
|||
54
libs/kotaemon/kotaemon/indices/rankings/llm_scoring.py
Normal file
|
|
@ -0,0 +1,54 @@
|
|||
from __future__ import annotations
|
||||
|
||||
from concurrent.futures import ThreadPoolExecutor
|
||||
|
||||
import numpy as np
|
||||
from langchain.output_parsers.boolean import BooleanOutputParser
|
||||
|
||||
from kotaemon.base import Document
|
||||
|
||||
from .llm import LLMReranking
|
||||
|
||||
|
||||
class LLMScoring(LLMReranking):
|
||||
def run(
|
||||
self,
|
||||
documents: list[Document],
|
||||
query: str,
|
||||
) -> list[Document]:
|
||||
"""Filter down documents based on their relevance to the query."""
|
||||
filtered_docs: list[Document] = []
|
||||
output_parser = BooleanOutputParser()
|
||||
|
||||
if self.concurrent:
|
||||
with ThreadPoolExecutor() as executor:
|
||||
futures = []
|
||||
for doc in documents:
|
||||
_prompt = self.prompt_template.populate(
|
||||
question=query, context=doc.get_content()
|
||||
)
|
||||
futures.append(executor.submit(lambda: self.llm(_prompt)))
|
||||
|
||||
results = [future.result() for future in futures]
|
||||
else:
|
||||
results = []
|
||||
for doc in documents:
|
||||
_prompt = self.prompt_template.populate(
|
||||
question=query, context=doc.get_content()
|
||||
)
|
||||
results.append(self.llm(_prompt))
|
||||
|
||||
for result, doc in zip(results, documents):
|
||||
score = np.exp(np.average(result.logprobs))
|
||||
include_doc = output_parser.parse(result.text)
|
||||
if include_doc:
|
||||
doc.metadata["llm_reranking_score"] = score
|
||||
else:
|
||||
doc.metadata["llm_reranking_score"] = 1 - score
|
||||
filtered_docs.append(doc)
|
||||
|
||||
# prevent returning empty result
|
||||
if len(filtered_docs) == 0:
|
||||
filtered_docs = documents[: self.top_k]
|
||||
|
||||
return filtered_docs
|
||||
182
libs/kotaemon/kotaemon/indices/rankings/llm_trulens.py
Normal file
|
|
@ -0,0 +1,182 @@
|
|||
from __future__ import annotations
|
||||
|
||||
import re
|
||||
from concurrent.futures import ThreadPoolExecutor
|
||||
from functools import partial
|
||||
|
||||
import tiktoken
|
||||
|
||||
from kotaemon.base import Document, HumanMessage, SystemMessage
|
||||
from kotaemon.indices.splitters import TokenSplitter
|
||||
from kotaemon.llms import BaseLLM, PromptTemplate
|
||||
|
||||
from .llm import LLMReranking
|
||||
|
||||
SYSTEM_PROMPT_TEMPLATE = PromptTemplate(
|
||||
"""You are a RELEVANCE grader; providing the relevance of the given CONTEXT to the given QUESTION.
|
||||
Respond only as a number from 0 to 10 where 0 is the least relevant and 10 is the most relevant.
|
||||
|
||||
A few additional scoring guidelines:
|
||||
|
||||
- Long CONTEXTS should score equally well as short CONTEXTS.
|
||||
|
||||
- RELEVANCE score should increase as the CONTEXTS provides more RELEVANT context to the QUESTION.
|
||||
|
||||
- RELEVANCE score should increase as the CONTEXTS provides RELEVANT context to more parts of the QUESTION.
|
||||
|
||||
- CONTEXT that is RELEVANT to some of the QUESTION should score of 2, 3 or 4. Higher score indicates more RELEVANCE.
|
||||
|
||||
- CONTEXT that is RELEVANT to most of the QUESTION should get a score of 5, 6, 7 or 8. Higher score indicates more RELEVANCE.
|
||||
|
||||
- CONTEXT that is RELEVANT to the entire QUESTION should get a score of 9 or 10. Higher score indicates more RELEVANCE.
|
||||
|
||||
- CONTEXT must be relevant and helpful for answering the entire QUESTION to get a score of 10.
|
||||
|
||||
- Never elaborate.""" # noqa: E501
|
||||
)
|
||||
|
||||
USER_PROMPT_TEMPLATE = PromptTemplate(
|
||||
"""QUESTION: {question}
|
||||
|
||||
CONTEXT: {context}
|
||||
|
||||
RELEVANCE: """
|
||||
) # noqa
|
||||
|
||||
PATTERN_INTEGER: re.Pattern = re.compile(r"([+-]?[1-9][0-9]*|0)")
|
||||
"""Regex that matches integers."""
|
||||
|
||||
MAX_CONTEXT_LEN = 7500
|
||||
|
||||
|
||||
def validate_rating(rating) -> int:
|
||||
"""Validate a rating is between 0 and 10."""
|
||||
|
||||
if not 0 <= rating <= 10:
|
||||
raise ValueError("Rating must be between 0 and 10")
|
||||
|
||||
return rating
|
||||
|
||||
|
||||
def re_0_10_rating(s: str) -> int:
|
||||
"""Extract a 0-10 rating from a string.
|
||||
|
||||
If the string does not match an integer or matches an integer outside the
|
||||
0-10 range, raises an error instead. If multiple numbers are found within
|
||||
the expected 0-10 range, the smallest is returned.
|
||||
|
||||
Args:
|
||||
s: String to extract rating from.
|
||||
|
||||
Returns:
|
||||
int: Extracted rating.
|
||||
|
||||
Raises:
|
||||
ParseError: If no integers between 0 and 10 are found in the string.
|
||||
"""
|
||||
|
||||
matches = PATTERN_INTEGER.findall(s)
|
||||
if not matches:
|
||||
raise AssertionError
|
||||
|
||||
vals = set()
|
||||
for match in matches:
|
||||
try:
|
||||
vals.add(validate_rating(int(match)))
|
||||
except ValueError:
|
||||
pass
|
||||
|
||||
if not vals:
|
||||
raise AssertionError
|
||||
|
||||
# Min to handle cases like "The rating is 8 out of 10."
|
||||
return min(vals)
|
||||
|
||||
|
||||
class LLMTrulensScoring(LLMReranking):
|
||||
llm: BaseLLM
|
||||
system_prompt_template: PromptTemplate = SYSTEM_PROMPT_TEMPLATE
|
||||
user_prompt_template: PromptTemplate = USER_PROMPT_TEMPLATE
|
||||
concurrent: bool = True
|
||||
normalize: float = 10
|
||||
trim_func: TokenSplitter = TokenSplitter.withx(
|
||||
chunk_size=MAX_CONTEXT_LEN,
|
||||
chunk_overlap=0,
|
||||
separator=" ",
|
||||
tokenizer=partial(
|
||||
tiktoken.encoding_for_model("gpt-3.5-turbo").encode,
|
||||
allowed_special=set(),
|
||||
disallowed_special="all",
|
||||
),
|
||||
)
|
||||
|
||||
def run(
|
||||
self,
|
||||
documents: list[Document],
|
||||
query: str,
|
||||
) -> list[Document]:
|
||||
"""Filter down documents based on their relevance to the query."""
|
||||
filtered_docs = []
|
||||
|
||||
documents = sorted(documents, key=lambda doc: doc.get_content())
|
||||
if self.concurrent:
|
||||
with ThreadPoolExecutor() as executor:
|
||||
futures = []
|
||||
for doc in documents:
|
||||
chunked_doc_content = self.trim_func(
|
||||
[
|
||||
Document(content=doc.get_content())
|
||||
# skip metadata which cause troubles
|
||||
]
|
||||
)[0].text
|
||||
|
||||
messages = []
|
||||
messages.append(
|
||||
SystemMessage(self.system_prompt_template.populate())
|
||||
)
|
||||
messages.append(
|
||||
HumanMessage(
|
||||
self.user_prompt_template.populate(
|
||||
question=query, context=chunked_doc_content
|
||||
)
|
||||
)
|
||||
)
|
||||
|
||||
def llm_call():
|
||||
return self.llm(messages).text
|
||||
|
||||
futures.append(executor.submit(llm_call))
|
||||
|
||||
results = [future.result() for future in futures]
|
||||
else:
|
||||
results = []
|
||||
for doc in documents:
|
||||
messages = []
|
||||
messages.append(SystemMessage(self.system_prompt_template.populate()))
|
||||
messages.append(
|
||||
SystemMessage(
|
||||
self.user_prompt_template.populate(
|
||||
question=query, context=doc.get_content()
|
||||
)
|
||||
)
|
||||
)
|
||||
results.append(self.llm(messages).text)
|
||||
|
||||
# use Boolean parser to extract relevancy output from LLM
|
||||
results = [
|
||||
(r_idx, float(re_0_10_rating(result)) / self.normalize)
|
||||
for r_idx, result in enumerate(results)
|
||||
]
|
||||
results.sort(key=lambda x: x[1], reverse=True)
|
||||
|
||||
for r_idx, score in results:
|
||||
doc = documents[r_idx]
|
||||
doc.metadata["llm_trulens_score"] = score
|
||||
filtered_docs.append(doc)
|
||||
|
||||
print(
|
||||
"LLM rerank scores",
|
||||
[doc.metadata["llm_trulens_score"] for doc in filtered_docs],
|
||||
)
|
||||
|
||||
return filtered_docs
|
||||
|
|
@ -23,7 +23,7 @@ class TokenSplitter(LlamaIndexDocTransformerMixin, BaseSplitter):
|
|||
)
|
||||
|
||||
def _get_li_class(self):
|
||||
from llama_index.text_splitter import TokenTextSplitter
|
||||
from llama_index.core.text_splitter import TokenTextSplitter
|
||||
|
||||
return TokenTextSplitter
|
||||
|
||||
|
|
@ -44,6 +44,6 @@ class SentenceWindowSplitter(LlamaIndexDocTransformerMixin, BaseSplitter):
|
|||
)
|
||||
|
||||
def _get_li_class(self):
|
||||
from llama_index.node_parser import SentenceWindowNodeParser
|
||||
from llama_index.core.node_parser import SentenceWindowNodeParser
|
||||
|
||||
return SentenceWindowNodeParser
|
||||
|
|
|
|||
|
|
@ -1,14 +1,18 @@
|
|||
from __future__ import annotations
|
||||
|
||||
import threading
|
||||
import uuid
|
||||
from pathlib import Path
|
||||
from typing import Optional, Sequence, cast
|
||||
|
||||
from theflow.settings import settings as flowsettings
|
||||
|
||||
from kotaemon.base import BaseComponent, Document, RetrievedDocument
|
||||
from kotaemon.embeddings import BaseEmbeddings
|
||||
from kotaemon.storages import BaseDocumentStore, BaseVectorStore
|
||||
|
||||
from .base import BaseIndexing, BaseRetrieval
|
||||
from .rankings import BaseReranking
|
||||
from .rankings import BaseReranking, LLMReranking
|
||||
|
||||
VECTOR_STORE_FNAME = "vectorstore"
|
||||
DOC_STORE_FNAME = "docstore"
|
||||
|
|
@ -23,9 +27,11 @@ class VectorIndexing(BaseIndexing):
|
|||
- List of texts
|
||||
"""
|
||||
|
||||
cache_dir: Optional[str] = getattr(flowsettings, "KH_CHUNKS_OUTPUT_DIR", None)
|
||||
vector_store: BaseVectorStore
|
||||
doc_store: Optional[BaseDocumentStore] = None
|
||||
embedding: BaseEmbeddings
|
||||
count_: int = 0
|
||||
|
||||
def to_retrieval_pipeline(self, *args, **kwargs):
|
||||
"""Convert the indexing pipeline to a retrieval pipeline"""
|
||||
|
|
@ -44,6 +50,52 @@ class VectorIndexing(BaseIndexing):
|
|||
qa_pipeline=CitationQAPipeline(**kwargs),
|
||||
)
|
||||
|
||||
def write_chunk_to_file(self, docs: list[Document]):
|
||||
# save the chunks content into markdown format
|
||||
if self.cache_dir:
|
||||
file_name = Path(docs[0].metadata["file_name"])
|
||||
for i in range(len(docs)):
|
||||
markdown_content = ""
|
||||
if "page_label" in docs[i].metadata:
|
||||
page_label = str(docs[i].metadata["page_label"])
|
||||
markdown_content += f"Page label: {page_label}"
|
||||
if "file_name" in docs[i].metadata:
|
||||
filename = docs[i].metadata["file_name"]
|
||||
markdown_content += f"\nFile name: {filename}"
|
||||
if "section" in docs[i].metadata:
|
||||
section = docs[i].metadata["section"]
|
||||
markdown_content += f"\nSection: {section}"
|
||||
if "type" in docs[i].metadata:
|
||||
if docs[i].metadata["type"] == "image":
|
||||
image_origin = docs[i].metadata["image_origin"]
|
||||
image_origin = f'<p><img src="{image_origin}"></p>'
|
||||
markdown_content += f"\nImage origin: {image_origin}"
|
||||
if docs[i].text:
|
||||
markdown_content += f"\ntext:\n{docs[i].text}"
|
||||
|
||||
with open(
|
||||
Path(self.cache_dir) / f"{file_name.stem}_{self.count_+i}.md",
|
||||
"w",
|
||||
encoding="utf-8",
|
||||
) as f:
|
||||
f.write(markdown_content)
|
||||
|
||||
def add_to_docstore(self, docs: list[Document]):
|
||||
if self.doc_store:
|
||||
print("Adding documents to doc store")
|
||||
self.doc_store.add(docs)
|
||||
|
||||
def add_to_vectorstore(self, docs: list[Document]):
|
||||
# in case we want to skip embedding
|
||||
if self.vector_store:
|
||||
print(f"Getting embeddings for {len(docs)} nodes")
|
||||
embeddings = self.embedding(docs)
|
||||
print("Adding embeddings to vector store")
|
||||
self.vector_store.add(
|
||||
embeddings=embeddings,
|
||||
ids=[t.doc_id for t in docs],
|
||||
)
|
||||
|
||||
def run(self, text: str | list[str] | Document | list[Document]):
|
||||
input_: list[Document] = []
|
||||
if not isinstance(text, list):
|
||||
|
|
@ -59,16 +111,10 @@ class VectorIndexing(BaseIndexing):
|
|||
f"Invalid input type {type(item)}, should be str or Document"
|
||||
)
|
||||
|
||||
print(f"Getting embeddings for {len(input_)} nodes")
|
||||
embeddings = self.embedding(input_)
|
||||
print("Adding embeddings to vector store")
|
||||
self.vector_store.add(
|
||||
embeddings=embeddings,
|
||||
ids=[t.doc_id for t in input_],
|
||||
)
|
||||
if self.doc_store:
|
||||
print("Adding documents to doc store")
|
||||
self.doc_store.add(input_)
|
||||
self.add_to_vectorstore(input_)
|
||||
self.add_to_docstore(input_)
|
||||
self.write_chunk_to_file(input_)
|
||||
self.count_ += len(input_)
|
||||
|
||||
|
||||
class VectorRetrieval(BaseRetrieval):
|
||||
|
|
@ -78,7 +124,16 @@ class VectorRetrieval(BaseRetrieval):
|
|||
doc_store: Optional[BaseDocumentStore] = None
|
||||
embedding: BaseEmbeddings
|
||||
rerankers: Sequence[BaseReranking] = []
|
||||
top_k: int = 1
|
||||
top_k: int = 5
|
||||
first_round_top_k_mult: int = 10
|
||||
retrieval_mode: str = "hybrid" # vector, text, hybrid
|
||||
|
||||
def _filter_docs(
|
||||
self, documents: list[RetrievedDocument], top_k: int | None = None
|
||||
):
|
||||
if top_k:
|
||||
documents = documents[:top_k]
|
||||
return documents
|
||||
|
||||
def run(
|
||||
self, text: str | Document, top_k: Optional[int] = None, **kwargs
|
||||
|
|
@ -95,24 +150,155 @@ class VectorRetrieval(BaseRetrieval):
|
|||
if top_k is None:
|
||||
top_k = self.top_k
|
||||
|
||||
do_extend = kwargs.pop("do_extend", False)
|
||||
thumbnail_count = kwargs.pop("thumbnail_count", 3)
|
||||
|
||||
if do_extend:
|
||||
top_k_first_round = top_k * self.first_round_top_k_mult
|
||||
else:
|
||||
top_k_first_round = top_k
|
||||
|
||||
if self.doc_store is None:
|
||||
raise ValueError(
|
||||
"doc_store is not provided. Please provide a doc_store to "
|
||||
"retrieve the documents"
|
||||
)
|
||||
|
||||
emb: list[float] = self.embedding(text)[0].embedding
|
||||
_, scores, ids = self.vector_store.query(embedding=emb, top_k=top_k, **kwargs)
|
||||
result: list[RetrievedDocument] = []
|
||||
# TODO: should declare scope directly in the run params
|
||||
scope = kwargs.pop("scope", None)
|
||||
emb: list[float]
|
||||
|
||||
if self.retrieval_mode == "vector":
|
||||
emb = self.embedding(text)[0].embedding
|
||||
_, scores, ids = self.vector_store.query(
|
||||
embedding=emb, top_k=top_k_first_round, **kwargs
|
||||
)
|
||||
docs = self.doc_store.get(ids)
|
||||
result = [
|
||||
RetrievedDocument(**doc.to_dict(), score=score)
|
||||
for doc, score in zip(docs, scores)
|
||||
]
|
||||
elif self.retrieval_mode == "text":
|
||||
query = text.text if isinstance(text, Document) else text
|
||||
docs = self.doc_store.query(query, top_k=top_k_first_round, doc_ids=scope)
|
||||
result = [RetrievedDocument(**doc.to_dict(), score=-1.0) for doc in docs]
|
||||
elif self.retrieval_mode == "hybrid":
|
||||
# similarity search section
|
||||
emb = self.embedding(text)[0].embedding
|
||||
vs_docs: list[RetrievedDocument] = []
|
||||
vs_ids: list[str] = []
|
||||
vs_scores: list[float] = []
|
||||
|
||||
def query_vectorstore():
|
||||
nonlocal vs_docs
|
||||
nonlocal vs_scores
|
||||
nonlocal vs_ids
|
||||
|
||||
assert self.doc_store is not None
|
||||
_, vs_scores, vs_ids = self.vector_store.query(
|
||||
embedding=emb, top_k=top_k_first_round, **kwargs
|
||||
)
|
||||
if vs_ids:
|
||||
vs_docs = self.doc_store.get(vs_ids)
|
||||
|
||||
# full-text search section
|
||||
ds_docs: list[RetrievedDocument] = []
|
||||
|
||||
def query_docstore():
|
||||
nonlocal ds_docs
|
||||
|
||||
assert self.doc_store is not None
|
||||
query = text.text if isinstance(text, Document) else text
|
||||
ds_docs = self.doc_store.query(
|
||||
query, top_k=top_k_first_round, doc_ids=scope
|
||||
)
|
||||
|
||||
vs_query_thread = threading.Thread(target=query_vectorstore)
|
||||
ds_query_thread = threading.Thread(target=query_docstore)
|
||||
|
||||
vs_query_thread.start()
|
||||
ds_query_thread.start()
|
||||
|
||||
vs_query_thread.join()
|
||||
ds_query_thread.join()
|
||||
|
||||
result = [
|
||||
RetrievedDocument(**doc.to_dict(), score=-1.0)
|
||||
for doc in ds_docs
|
||||
if doc not in vs_ids
|
||||
]
|
||||
result += [
|
||||
RetrievedDocument(**doc.to_dict(), score=score)
|
||||
for doc, score in zip(vs_docs, vs_scores)
|
||||
]
|
||||
print(f"Got {len(vs_docs)} from vectorstore")
|
||||
print(f"Got {len(ds_docs)} from docstore")
|
||||
|
||||
# use additional reranker to re-order the document list
|
||||
if self.rerankers:
|
||||
if self.rerankers and text:
|
||||
for reranker in self.rerankers:
|
||||
# if reranker is LLMReranking, limit the document with top_k items only
|
||||
if isinstance(reranker, LLMReranking):
|
||||
result = self._filter_docs(result, top_k=top_k)
|
||||
result = reranker(documents=result, query=text)
|
||||
|
||||
result = self._filter_docs(result, top_k=top_k)
|
||||
print(f"Got raw {len(result)} retrieved documents")
|
||||
|
||||
# add page thumbnails to the result if exists
|
||||
thumbnail_doc_ids: set[str] = set()
|
||||
# we should copy the text from retrieved text chunk
|
||||
# to the thumbnail to get relevant LLM score correctly
|
||||
text_thumbnail_docs: dict[str, RetrievedDocument] = {}
|
||||
|
||||
non_thumbnail_docs = []
|
||||
raw_thumbnail_docs = []
|
||||
for doc in result:
|
||||
if doc.metadata.get("type") == "thumbnail":
|
||||
# change type to image to display on UI
|
||||
doc.metadata["type"] = "image"
|
||||
raw_thumbnail_docs.append(doc)
|
||||
continue
|
||||
if (
|
||||
"thumbnail_doc_id" in doc.metadata
|
||||
and len(thumbnail_doc_ids) < thumbnail_count
|
||||
):
|
||||
thumbnail_id = doc.metadata["thumbnail_doc_id"]
|
||||
thumbnail_doc_ids.add(thumbnail_id)
|
||||
text_thumbnail_docs[thumbnail_id] = doc
|
||||
else:
|
||||
non_thumbnail_docs.append(doc)
|
||||
|
||||
linked_thumbnail_docs = self.doc_store.get(list(thumbnail_doc_ids))
|
||||
print(
|
||||
"thumbnail docs",
|
||||
len(linked_thumbnail_docs),
|
||||
"non-thumbnail docs",
|
||||
len(non_thumbnail_docs),
|
||||
"raw-thumbnail docs",
|
||||
len(raw_thumbnail_docs),
|
||||
)
|
||||
additional_docs = []
|
||||
|
||||
for thumbnail_doc in linked_thumbnail_docs:
|
||||
text_doc = text_thumbnail_docs[thumbnail_doc.doc_id]
|
||||
doc_dict = thumbnail_doc.to_dict()
|
||||
doc_dict["_id"] = text_doc.doc_id
|
||||
doc_dict["content"] = text_doc.content
|
||||
doc_dict["metadata"]["type"] = "image"
|
||||
for key in text_doc.metadata:
|
||||
if key not in doc_dict["metadata"]:
|
||||
doc_dict["metadata"][key] = text_doc.metadata[key]
|
||||
|
||||
additional_docs.append(RetrievedDocument(**doc_dict, score=text_doc.score))
|
||||
|
||||
result = additional_docs + non_thumbnail_docs
|
||||
|
||||
if not result:
|
||||
# return output from raw retrieved thumbnails
|
||||
result = self._filter_docs(raw_thumbnail_docs, top_k=thumbnail_count)
|
||||
|
||||
return result
|
||||
|
||||
|
||||
|
|
|
|||
|
|
@ -7,6 +7,7 @@ from .chats import (
|
|||
ChatLLM,
|
||||
ChatOpenAI,
|
||||
EndpointChatLLM,
|
||||
LCAnthropicChat,
|
||||
LCAzureChatOpenAI,
|
||||
LCChatOpenAI,
|
||||
LlamaCppChat,
|
||||
|
|
@ -27,6 +28,7 @@ __all__ = [
|
|||
"SystemMessage",
|
||||
"AzureChatOpenAI",
|
||||
"ChatOpenAI",
|
||||
"LCAnthropicChat",
|
||||
"LCAzureChatOpenAI",
|
||||
"LCChatOpenAI",
|
||||
"LlamaCppChat",
|
||||
|
|
|
|||
|
|
@ -1,6 +1,11 @@
|
|||
from .base import ChatLLM
|
||||
from .endpoint_based import EndpointChatLLM
|
||||
from .langchain_based import LCAzureChatOpenAI, LCChatMixin, LCChatOpenAI
|
||||
from .langchain_based import (
|
||||
LCAnthropicChat,
|
||||
LCAzureChatOpenAI,
|
||||
LCChatMixin,
|
||||
LCChatOpenAI,
|
||||
)
|
||||
from .llamacpp import LlamaCppChat
|
||||
from .openai import AzureChatOpenAI, ChatOpenAI
|
||||
|
||||
|
|
@ -10,6 +15,7 @@ __all__ = [
|
|||
"ChatLLM",
|
||||
"EndpointChatLLM",
|
||||
"ChatOpenAI",
|
||||
"LCAnthropicChat",
|
||||
"LCChatOpenAI",
|
||||
"LCAzureChatOpenAI",
|
||||
"LCChatMixin",
|
||||
|
|
|
|||
|
|
@ -221,3 +221,27 @@ class LCAzureChatOpenAI(LCChatMixin, ChatLLM): # type: ignore
|
|||
from langchain.chat_models import AzureChatOpenAI
|
||||
|
||||
return AzureChatOpenAI
|
||||
|
||||
|
||||
class LCAnthropicChat(LCChatMixin, ChatLLM): # type: ignore
|
||||
def __init__(
|
||||
self,
|
||||
api_key: str | None = None,
|
||||
model_name: str | None = None,
|
||||
temperature: float = 0.7,
|
||||
**params,
|
||||
):
|
||||
super().__init__(
|
||||
api_key=api_key,
|
||||
model_name=model_name,
|
||||
temperature=temperature,
|
||||
**params,
|
||||
)
|
||||
|
||||
def _get_lc_class(self):
|
||||
try:
|
||||
from langchain_anthropic import ChatAnthropic
|
||||
except ImportError:
|
||||
raise ImportError("Please install langchain-anthropic")
|
||||
|
||||
return ChatAnthropic
|
||||
|
|
|
|||
|
|
@ -159,6 +159,15 @@ class BaseChatOpenAI(ChatLLM):
|
|||
additional_kwargs["tool_calls"] = resp["choices"][0]["message"][
|
||||
"tool_calls"
|
||||
]
|
||||
|
||||
if resp["choices"][0].get("logprobs") is None:
|
||||
logprobs = []
|
||||
else:
|
||||
all_logprobs = resp["choices"][0]["logprobs"].get("content")
|
||||
logprobs = (
|
||||
[logprob["logprob"] for logprob in all_logprobs] if all_logprobs else []
|
||||
)
|
||||
|
||||
output = LLMInterface(
|
||||
candidates=[(_["message"]["content"] or "") for _ in resp["choices"]],
|
||||
content=resp["choices"][0]["message"]["content"] or "",
|
||||
|
|
@ -170,6 +179,7 @@ class BaseChatOpenAI(ChatLLM):
|
|||
AIMessage(content=(_["message"]["content"]) or "")
|
||||
for _ in resp["choices"]
|
||||
],
|
||||
logprobs=logprobs,
|
||||
)
|
||||
|
||||
return output
|
||||
|
|
@ -216,11 +226,24 @@ class BaseChatOpenAI(ChatLLM):
|
|||
client, messages=input_messages, stream=True, **kwargs
|
||||
)
|
||||
|
||||
for chunk in resp:
|
||||
if not chunk.choices:
|
||||
for c in resp:
|
||||
chunk = c.dict()
|
||||
if not chunk["choices"]:
|
||||
continue
|
||||
if chunk.choices[0].delta.content is not None:
|
||||
yield LLMInterface(content=chunk.choices[0].delta.content)
|
||||
if chunk["choices"][0]["delta"]["content"] is not None:
|
||||
if chunk["choices"][0].get("logprobs") is None:
|
||||
logprobs = []
|
||||
else:
|
||||
logprobs = [
|
||||
logprob["logprob"]
|
||||
for logprob in chunk["choices"][0]["logprobs"].get(
|
||||
"content", []
|
||||
)
|
||||
]
|
||||
|
||||
yield LLMInterface(
|
||||
content=chunk["choices"][0]["delta"]["content"], logprobs=logprobs
|
||||
)
|
||||
|
||||
async def astream(
|
||||
self, messages: str | BaseMessage | list[BaseMessage], *args, **kwargs
|
||||
|
|
|
|||
|
|
@ -3,10 +3,12 @@ from .azureai_document_intelligence_loader import AzureAIDocumentIntelligenceLoa
|
|||
from .base import AutoReader, BaseReader
|
||||
from .composite_loader import DirectoryReader
|
||||
from .docx_loader import DocxReader
|
||||
from .excel_loader import PandasExcelReader
|
||||
from .excel_loader import ExcelReader, PandasExcelReader
|
||||
from .html_loader import HtmlReader, MhtmlReader
|
||||
from .mathpix_loader import MathpixPDFReader
|
||||
from .ocr_loader import ImageReader, OCRReader
|
||||
from .pdf_loader import PDFThumbnailReader
|
||||
from .txt_loader import TxtReader
|
||||
from .unstructured_loader import UnstructuredReader
|
||||
|
||||
__all__ = [
|
||||
|
|
@ -14,6 +16,7 @@ __all__ = [
|
|||
"AzureAIDocumentIntelligenceLoader",
|
||||
"BaseReader",
|
||||
"PandasExcelReader",
|
||||
"ExcelReader",
|
||||
"MathpixPDFReader",
|
||||
"ImageReader",
|
||||
"OCRReader",
|
||||
|
|
@ -23,4 +26,6 @@ __all__ = [
|
|||
"HtmlReader",
|
||||
"MhtmlReader",
|
||||
"AdobeReader",
|
||||
"TxtReader",
|
||||
"PDFThumbnailReader",
|
||||
]
|
||||
|
|
|
|||
|
|
@ -6,7 +6,7 @@ from pathlib import Path
|
|||
from typing import Any, Dict, List, Optional
|
||||
|
||||
from decouple import config
|
||||
from llama_index.readers.base import BaseReader
|
||||
from llama_index.core.readers.base import BaseReader
|
||||
|
||||
from kotaemon.base import Document
|
||||
|
||||
|
|
@ -154,7 +154,7 @@ class AdobeReader(BaseReader):
|
|||
for page_number, table_content, table_caption in tables:
|
||||
documents.append(
|
||||
Document(
|
||||
text=table_caption,
|
||||
text=table_content,
|
||||
metadata={
|
||||
"table_origin": table_content,
|
||||
"type": "table",
|
||||
|
|
|
|||
|
|
@ -1,10 +1,56 @@
|
|||
import base64
|
||||
import os
|
||||
from io import BytesIO
|
||||
from pathlib import Path
|
||||
from typing import Optional
|
||||
|
||||
from PIL import Image
|
||||
|
||||
from kotaemon.base import Document, Param
|
||||
|
||||
from .base import BaseReader
|
||||
from .utils.adobe import generate_single_figure_caption
|
||||
|
||||
|
||||
def crop_image(file_path: Path, bbox: list[float], page_number: int = 0) -> Image.Image:
|
||||
"""Crop the image based on the bounding box
|
||||
|
||||
Args:
|
||||
file_path (Path): path to the image file
|
||||
bbox (list[float]): bounding box of the image (in percentage [x0, y0, x1, y1])
|
||||
page_number (int, optional): page number of the image. Defaults to 0.
|
||||
|
||||
Returns:
|
||||
Image.Image: cropped image
|
||||
"""
|
||||
left, upper, right, lower = bbox
|
||||
|
||||
img: Image.Image
|
||||
suffix = file_path.suffix.lower()
|
||||
if suffix == ".pdf":
|
||||
try:
|
||||
import fitz
|
||||
except ImportError:
|
||||
raise ImportError("Please install PyMuPDF: 'pip install PyMuPDF'")
|
||||
|
||||
doc = fitz.open(file_path)
|
||||
page = doc.load_page(page_number)
|
||||
pm = page.get_pixmap(dpi=150)
|
||||
img = Image.frombytes("RGB", [pm.width, pm.height], pm.samples)
|
||||
elif suffix in [".tif", ".tiff"]:
|
||||
img = Image.open(file_path)
|
||||
img.seek(page_number)
|
||||
else:
|
||||
img = Image.open(file_path)
|
||||
|
||||
return img.crop(
|
||||
(
|
||||
int(left * img.width),
|
||||
int(upper * img.height),
|
||||
int(right * img.width),
|
||||
int(lower * img.height),
|
||||
)
|
||||
)
|
||||
|
||||
|
||||
class AzureAIDocumentIntelligenceLoader(BaseReader):
|
||||
|
|
@ -14,7 +60,7 @@ class AzureAIDocumentIntelligenceLoader(BaseReader):
|
|||
heif, docx, xlsx, pptx and html.
|
||||
"""
|
||||
|
||||
_dependencies = ["azure-ai-documentintelligence"]
|
||||
_dependencies = ["azure-ai-documentintelligence", "PyMuPDF", "Pillow"]
|
||||
|
||||
endpoint: str = Param(
|
||||
os.environ.get("AZUREAI_DOCUMENT_INTELLIGENT_ENDPOINT", None),
|
||||
|
|
@ -34,6 +80,29 @@ class AzureAIDocumentIntelligenceLoader(BaseReader):
|
|||
"#model-analysis-features)"
|
||||
),
|
||||
)
|
||||
output_content_format: str = Param(
|
||||
"markdown",
|
||||
help="Output content format. Can be 'markdown' or 'text'.Default is markdown",
|
||||
)
|
||||
vlm_endpoint: str = Param(
|
||||
help=(
|
||||
"Default VLM endpoint for figure captioning. If not provided, will not "
|
||||
"caption the figures"
|
||||
)
|
||||
)
|
||||
figure_friendly_filetypes: list[str] = Param(
|
||||
[".pdf", ".jpeg", ".jpg", ".png", ".bmp", ".tiff", ".heif", ".tif"],
|
||||
help=(
|
||||
"File types that we can reliably open and extract figures. "
|
||||
"For files like .docx or .html, the visual layout may be different "
|
||||
"when viewed from different tools, hence we cannot use Azure DI "
|
||||
"location to extract figures."
|
||||
),
|
||||
)
|
||||
cache_dir: str = Param(
|
||||
None,
|
||||
help="Directory to cache the downloaded files. Default is None",
|
||||
)
|
||||
|
||||
@Param.auto(depends_on=["endpoint", "credential"])
|
||||
def client_(self):
|
||||
|
|
@ -55,14 +124,114 @@ class AzureAIDocumentIntelligenceLoader(BaseReader):
|
|||
def load_data(
|
||||
self, file_path: Path, extra_info: Optional[dict] = None, **kwargs
|
||||
) -> list[Document]:
|
||||
"""Extract the input file, allowing multi-modal extraction"""
|
||||
metadata = extra_info or {}
|
||||
file_name = Path(file_path)
|
||||
with open(file_path, "rb") as fi:
|
||||
poller = self.client_.begin_analyze_document(
|
||||
self.model,
|
||||
analyze_request=fi,
|
||||
content_type="application/octet-stream",
|
||||
output_content_format="markdown",
|
||||
output_content_format=self.output_content_format,
|
||||
)
|
||||
result = poller.result()
|
||||
|
||||
return [Document(content=result.content, metadata=metadata)]
|
||||
# the total text content of the document in `output_content_format` format
|
||||
text_content = result.content
|
||||
removed_spans: list[dict] = []
|
||||
|
||||
# extract the figures
|
||||
figures = []
|
||||
for figure_desc in result.get("figures", []):
|
||||
if not self.vlm_endpoint:
|
||||
continue
|
||||
if file_path.suffix.lower() not in self.figure_friendly_filetypes:
|
||||
continue
|
||||
|
||||
# read & crop the image
|
||||
page_number = figure_desc["boundingRegions"][0]["pageNumber"]
|
||||
page_width = result.pages[page_number - 1]["width"]
|
||||
page_height = result.pages[page_number - 1]["height"]
|
||||
polygon = figure_desc["boundingRegions"][0]["polygon"]
|
||||
xs = [polygon[i] for i in range(0, len(polygon), 2)]
|
||||
ys = [polygon[i] for i in range(1, len(polygon), 2)]
|
||||
bbox = [
|
||||
min(xs) / page_width,
|
||||
min(ys) / page_height,
|
||||
max(xs) / page_width,
|
||||
max(ys) / page_height,
|
||||
]
|
||||
img = crop_image(file_path, bbox, page_number - 1)
|
||||
|
||||
# convert the image into base64
|
||||
img_bytes = BytesIO()
|
||||
img.save(img_bytes, format="PNG")
|
||||
img_base64 = base64.b64encode(img_bytes.getvalue()).decode("utf-8")
|
||||
img_base64 = f"data:image/png;base64,{img_base64}"
|
||||
|
||||
# caption the image
|
||||
caption = generate_single_figure_caption(
|
||||
figure=img_base64, vlm_endpoint=self.vlm_endpoint
|
||||
)
|
||||
|
||||
# store the image into document
|
||||
figure_metadata = {
|
||||
"image_origin": img_base64,
|
||||
"type": "image",
|
||||
"page_label": page_number,
|
||||
}
|
||||
figure_metadata.update(metadata)
|
||||
|
||||
figures.append(
|
||||
Document(
|
||||
text=caption,
|
||||
metadata=figure_metadata,
|
||||
)
|
||||
)
|
||||
removed_spans += figure_desc["spans"]
|
||||
|
||||
# extract the tables
|
||||
tables = []
|
||||
for table_desc in result.get("tables", []):
|
||||
if not table_desc["spans"]:
|
||||
continue
|
||||
|
||||
# convert the tables into markdown format
|
||||
boundingRegions = table_desc["boundingRegions"]
|
||||
if boundingRegions:
|
||||
page_number = boundingRegions[0]["pageNumber"]
|
||||
else:
|
||||
page_number = 1
|
||||
|
||||
# store the tables into document
|
||||
offset = table_desc["spans"][0]["offset"]
|
||||
length = table_desc["spans"][0]["length"]
|
||||
table_metadata = {
|
||||
"type": "table",
|
||||
"page_label": page_number,
|
||||
"table_origin": text_content[offset : offset + length],
|
||||
}
|
||||
table_metadata.update(metadata)
|
||||
|
||||
tables.append(
|
||||
Document(
|
||||
text=text_content[offset : offset + length],
|
||||
metadata=table_metadata,
|
||||
)
|
||||
)
|
||||
removed_spans += table_desc["spans"]
|
||||
# save the text content into markdown format
|
||||
if self.cache_dir is not None:
|
||||
with open(
|
||||
Path(self.cache_dir) / f"{file_name.stem}.md", "w", encoding="utf-8"
|
||||
) as f:
|
||||
f.write(text_content)
|
||||
|
||||
removed_spans = sorted(removed_spans, key=lambda x: x["offset"], reverse=True)
|
||||
for span in removed_spans:
|
||||
text_content = (
|
||||
text_content[: span["offset"]]
|
||||
+ text_content[span["offset"] + span["length"] :]
|
||||
)
|
||||
|
||||
return [Document(content=text_content, metadata=metadata)] + figures + tables
|
||||
|
|
|
|||
|
|
@ -4,7 +4,7 @@ from typing import TYPE_CHECKING, Any, List, Type, Union
|
|||
from kotaemon.base import BaseComponent, Document
|
||||
|
||||
if TYPE_CHECKING:
|
||||
from llama_index.readers.base import BaseReader as LIBaseReader
|
||||
from llama_index.core.readers.base import BaseReader as LIBaseReader
|
||||
|
||||
|
||||
class BaseReader(BaseComponent):
|
||||
|
|
@ -20,7 +20,7 @@ class AutoReader(BaseReader):
|
|||
"""Init reader using string identifier or class name from llama-hub"""
|
||||
|
||||
if isinstance(reader_type, str):
|
||||
from llama_index import download_loader
|
||||
from llama_index.core import download_loader
|
||||
|
||||
self._reader = download_loader(reader_type)()
|
||||
else:
|
||||
|
|
|
|||
|
|
@ -1,6 +1,6 @@
|
|||
from typing import Callable, List, Optional, Type
|
||||
|
||||
from llama_index.readers.base import BaseReader as LIBaseReader
|
||||
from llama_index.core.readers.base import BaseReader as LIBaseReader
|
||||
|
||||
from .base import BaseReader, LIReaderMixin
|
||||
|
||||
|
|
@ -48,6 +48,6 @@ class DirectoryReader(LIReaderMixin, BaseReader):
|
|||
file_metadata: Optional[Callable[[str], dict]] = None
|
||||
|
||||
def _get_wrapped_class(self) -> Type["LIBaseReader"]:
|
||||
from llama_index import SimpleDirectoryReader
|
||||
from llama_index.core import SimpleDirectoryReader
|
||||
|
||||
return SimpleDirectoryReader
|
||||
|
|
|
|||
|
|
@ -3,7 +3,7 @@ from pathlib import Path
|
|||
from typing import List, Optional
|
||||
|
||||
import pandas as pd
|
||||
from llama_index.readers.base import BaseReader
|
||||
from llama_index.core.readers.base import BaseReader
|
||||
|
||||
from kotaemon.base import Document
|
||||
|
||||
|
|
@ -27,6 +27,21 @@ class DocxReader(BaseReader):
|
|||
"Please install it using `pip install python-docx`"
|
||||
)
|
||||
|
||||
def _load_single_table(self, table) -> List[List[str]]:
|
||||
"""Extract content from tables. Return a list of columns: list[str]
|
||||
Some merged cells will share duplicated content.
|
||||
"""
|
||||
n_row = len(table.rows)
|
||||
n_col = len(table.columns)
|
||||
|
||||
arrays = [["" for _ in range(n_row)] for _ in range(n_col)]
|
||||
|
||||
for i, row in enumerate(table.rows):
|
||||
for j, cell in enumerate(row.cells):
|
||||
arrays[j][i] = cell.text
|
||||
|
||||
return arrays
|
||||
|
||||
def load_data(
|
||||
self, file_path: Path, extra_info: Optional[dict] = None, **kwargs
|
||||
) -> List[Document]:
|
||||
|
|
@ -50,13 +65,9 @@ class DocxReader(BaseReader):
|
|||
|
||||
tables = []
|
||||
for t in doc.tables:
|
||||
arrays = [
|
||||
[
|
||||
unicodedata.normalize("NFKC", t.cell(i, j).text)
|
||||
for i in range(len(t.rows))
|
||||
]
|
||||
for j in range(len(t.columns))
|
||||
]
|
||||
# return list of columns: list of string
|
||||
arrays = self._load_single_table(t)
|
||||
|
||||
tables.append(pd.DataFrame({a[0]: a[1:] for a in arrays}))
|
||||
|
||||
extra_info = extra_info or {}
|
||||
|
|
|
|||
|
|
@ -6,7 +6,7 @@ Pandas parser for .xlsx files.
|
|||
from pathlib import Path
|
||||
from typing import Any, List, Optional, Union
|
||||
|
||||
from llama_index.readers.base import BaseReader
|
||||
from llama_index.core.readers.base import BaseReader
|
||||
|
||||
from kotaemon.base import Document
|
||||
|
||||
|
|
@ -82,6 +82,9 @@ class PandasExcelReader(BaseReader):
|
|||
sheet = []
|
||||
if include_sheetname:
|
||||
sheet.append([key])
|
||||
dfs[key] = dfs[key].dropna(axis=0, how="all")
|
||||
dfs[key] = dfs[key].dropna(axis=0, how="all")
|
||||
dfs[key].fillna("", inplace=True)
|
||||
sheet.extend(dfs[key].values.astype(str).tolist())
|
||||
df_sheets.append(sheet)
|
||||
|
||||
|
|
@ -99,3 +102,91 @@ class PandasExcelReader(BaseReader):
|
|||
]
|
||||
|
||||
return output
|
||||
|
||||
|
||||
class ExcelReader(BaseReader):
|
||||
r"""Spreadsheet exporter respecting multiple worksheets
|
||||
|
||||
Parses CSVs using the separator detection from Pandas `read_csv` function.
|
||||
If special parameters are required, use the `pandas_config` dict.
|
||||
|
||||
Args:
|
||||
|
||||
pandas_config (dict): Options for the `pandas.read_excel` function call.
|
||||
Refer to https://pandas.pydata.org/docs/reference/api/pandas.read_excel.html
|
||||
for more information. Set to empty dict by default,
|
||||
this means defaults will be used.
|
||||
|
||||
"""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
*args: Any,
|
||||
pandas_config: Optional[dict] = None,
|
||||
row_joiner: str = "\n",
|
||||
col_joiner: str = " ",
|
||||
**kwargs: Any,
|
||||
) -> None:
|
||||
"""Init params."""
|
||||
super().__init__(*args, **kwargs)
|
||||
self._pandas_config = pandas_config or {}
|
||||
self._row_joiner = row_joiner if row_joiner else "\n"
|
||||
self._col_joiner = col_joiner if col_joiner else " "
|
||||
|
||||
def load_data(
|
||||
self,
|
||||
file: Path,
|
||||
include_sheetname: bool = True,
|
||||
sheet_name: Optional[Union[str, int, list]] = None,
|
||||
extra_info: Optional[dict] = None,
|
||||
**kwargs,
|
||||
) -> List[Document]:
|
||||
"""Parse file and extract values from a specific column.
|
||||
|
||||
Args:
|
||||
file (Path): The path to the Excel file to read.
|
||||
include_sheetname (bool): Whether to include the sheet name in the output.
|
||||
sheet_name (Union[str, int, None]): The specific sheet to read from,
|
||||
default is None which reads all sheets.
|
||||
|
||||
Returns:
|
||||
List[Document]: A list of`Document objects containing the
|
||||
values from the specified column in the Excel file.
|
||||
"""
|
||||
|
||||
try:
|
||||
import pandas as pd
|
||||
except ImportError:
|
||||
raise ImportError(
|
||||
"install pandas using `pip3 install pandas` to use this loader"
|
||||
)
|
||||
|
||||
if sheet_name is not None:
|
||||
sheet_name = (
|
||||
[sheet_name] if not isinstance(sheet_name, list) else sheet_name
|
||||
)
|
||||
|
||||
# clean up input
|
||||
file = Path(file)
|
||||
extra_info = extra_info or {}
|
||||
|
||||
dfs = pd.read_excel(file, sheet_name=sheet_name, **self._pandas_config)
|
||||
sheet_names = dfs.keys()
|
||||
output = []
|
||||
|
||||
for idx, key in enumerate(sheet_names):
|
||||
dfs[key] = dfs[key].dropna(axis=0, how="all")
|
||||
dfs[key] = dfs[key].dropna(axis=0, how="all")
|
||||
dfs[key] = dfs[key].astype("object")
|
||||
dfs[key].fillna("", inplace=True)
|
||||
|
||||
rows = dfs[key].values.astype(str).tolist()
|
||||
content = self._row_joiner.join(
|
||||
self._col_joiner.join(row).strip() for row in rows
|
||||
).strip()
|
||||
if include_sheetname:
|
||||
content = f"(Sheet {key} of file {file.name})\n{content}"
|
||||
metadata = {"page_label": idx + 1, "sheet_name": key, **extra_info}
|
||||
output.append(Document(text=content, metadata=metadata))
|
||||
|
||||
return output
|
||||
|
|
|
|||
|
|
@ -2,7 +2,8 @@ import email
|
|||
from pathlib import Path
|
||||
from typing import Optional
|
||||
|
||||
from llama_index.readers.base import BaseReader
|
||||
from llama_index.core.readers.base import BaseReader
|
||||
from theflow.settings import settings as flowsettings
|
||||
|
||||
from kotaemon.base import Document
|
||||
|
||||
|
|
@ -78,6 +79,9 @@ class MhtmlReader(BaseReader):
|
|||
|
||||
def __init__(
|
||||
self,
|
||||
cache_dir: Optional[str] = getattr(
|
||||
flowsettings, "KH_MARKDOWN_OUTPUT_DIR", None
|
||||
),
|
||||
open_encoding: Optional[str] = None,
|
||||
bs_kwargs: Optional[dict] = None,
|
||||
get_text_separator: str = "",
|
||||
|
|
@ -86,6 +90,7 @@ class MhtmlReader(BaseReader):
|
|||
to pass to the BeautifulSoup object.
|
||||
|
||||
Args:
|
||||
cache_dir: Path for markdwon format.
|
||||
file_path: Path to file to load.
|
||||
open_encoding: The encoding to use when opening the file.
|
||||
bs_kwargs: Any kwargs to pass to the BeautifulSoup object.
|
||||
|
|
@ -100,6 +105,7 @@ class MhtmlReader(BaseReader):
|
|||
"`pip install beautifulsoup4`"
|
||||
)
|
||||
|
||||
self.cache_dir = cache_dir
|
||||
self.open_encoding = open_encoding
|
||||
if bs_kwargs is None:
|
||||
bs_kwargs = {"features": "lxml"}
|
||||
|
|
@ -116,6 +122,7 @@ class MhtmlReader(BaseReader):
|
|||
extra_info = extra_info or {}
|
||||
metadata: dict = extra_info
|
||||
page = []
|
||||
file_name = Path(file_path)
|
||||
with open(file_path, "r", encoding=self.open_encoding) as f:
|
||||
message = email.message_from_string(f.read())
|
||||
parts = message.get_payload()
|
||||
|
|
@ -144,5 +151,11 @@ class MhtmlReader(BaseReader):
|
|||
text = "\n\n".join(lines)
|
||||
if text:
|
||||
page.append(text)
|
||||
# save the page into markdown format
|
||||
print(self.cache_dir)
|
||||
if self.cache_dir is not None:
|
||||
print(Path(self.cache_dir) / f"{file_name.stem}.md")
|
||||
with open(Path(self.cache_dir) / f"{file_name.stem}.md", "w") as f:
|
||||
f.write(page[0])
|
||||
|
||||
return [Document(text="\n\n".join(page), metadata=metadata)]
|
||||
|
|
|
|||
|
|
@ -6,7 +6,7 @@ from typing import Any, Dict, List, Optional
|
|||
|
||||
import requests
|
||||
from langchain.utils import get_from_dict_or_env
|
||||
from llama_index.readers.base import BaseReader
|
||||
from llama_index.core.readers.base import BaseReader
|
||||
|
||||
from kotaemon.base import Document
|
||||
|
||||
|
|
|
|||
|
|
@ -5,8 +5,8 @@ from typing import List, Optional
|
|||
from uuid import uuid4
|
||||
|
||||
import requests
|
||||
from llama_index.readers.base import BaseReader
|
||||
from tenacity import after_log, retry, stop_after_attempt, wait_fixed, wait_random
|
||||
from llama_index.core.readers.base import BaseReader
|
||||
from tenacity import after_log, retry, stop_after_attempt, wait_exponential
|
||||
|
||||
from kotaemon.base import Document
|
||||
|
||||
|
|
@ -19,12 +19,15 @@ DEFAULT_OCR_ENDPOINT = "http://127.0.0.1:8000/v2/ai/infer/"
|
|||
|
||||
|
||||
@retry(
|
||||
stop=stop_after_attempt(3),
|
||||
wait=wait_fixed(5) + wait_random(0, 2),
|
||||
after=after_log(logger, logging.DEBUG),
|
||||
stop=stop_after_attempt(6),
|
||||
wait=wait_exponential(multiplier=20, exp_base=2, min=1, max=1000),
|
||||
after=after_log(logger, logging.WARNING),
|
||||
)
|
||||
def tenacious_api_post(url, **kwargs):
|
||||
resp = requests.post(url=url, **kwargs)
|
||||
def tenacious_api_post(url, file_path, table_only, **kwargs):
|
||||
with file_path.open("rb") as content:
|
||||
files = {"input": content}
|
||||
data = {"job_id": uuid4(), "table_only": table_only}
|
||||
resp = requests.post(url=url, files=files, data=data, **kwargs)
|
||||
resp.raise_for_status()
|
||||
return resp
|
||||
|
||||
|
|
@ -71,17 +74,15 @@ class OCRReader(BaseReader):
|
|||
"""
|
||||
file_path = Path(file_path).resolve()
|
||||
|
||||
with file_path.open("rb") as content:
|
||||
files = {"input": content}
|
||||
data = {"job_id": uuid4(), "table_only": not self.use_ocr}
|
||||
|
||||
# call the API from FullOCR endpoint
|
||||
if "response_content" in kwargs:
|
||||
# overriding response content if specified
|
||||
ocr_results = kwargs["response_content"]
|
||||
else:
|
||||
# call original API
|
||||
resp = tenacious_api_post(url=self.ocr_endpoint, files=files, data=data)
|
||||
resp = tenacious_api_post(
|
||||
url=self.ocr_endpoint, file_path=file_path, table_only=not self.use_ocr
|
||||
)
|
||||
ocr_results = resp.json()["result"]
|
||||
|
||||
debug_path = kwargs.pop("debug_path", None)
|
||||
|
|
@ -168,17 +169,15 @@ class ImageReader(BaseReader):
|
|||
"""
|
||||
file_path = Path(file_path).resolve()
|
||||
|
||||
with file_path.open("rb") as content:
|
||||
files = {"input": content}
|
||||
data = {"job_id": uuid4(), "table_only": False}
|
||||
|
||||
# call the API from FullOCR endpoint
|
||||
if "response_content" in kwargs:
|
||||
# overriding response content if specified
|
||||
ocr_results = kwargs["response_content"]
|
||||
else:
|
||||
# call original API
|
||||
resp = tenacious_api_post(url=self.ocr_endpoint, files=files, data=data)
|
||||
resp = tenacious_api_post(
|
||||
url=self.ocr_endpoint, file_path=file_path, table_only=False
|
||||
)
|
||||
ocr_results = resp.json()["result"]
|
||||
|
||||
extra_info = extra_info or {}
|
||||
|
|
|
|||
114
libs/kotaemon/kotaemon/loaders/pdf_loader.py
Normal file
|
|
@ -0,0 +1,114 @@
|
|||
import base64
|
||||
from io import BytesIO
|
||||
from pathlib import Path
|
||||
from typing import Dict, List, Optional
|
||||
|
||||
from fsspec import AbstractFileSystem
|
||||
from llama_index.readers.file import PDFReader
|
||||
from PIL import Image
|
||||
|
||||
from kotaemon.base import Document
|
||||
|
||||
|
||||
def get_page_thumbnails(
|
||||
file_path: Path, pages: list[int], dpi: int = 80
|
||||
) -> List[Image.Image]:
|
||||
"""Get image thumbnails of the pages in the PDF file.
|
||||
|
||||
Args:
|
||||
file_path (Path): path to the image file
|
||||
page_number (list[int]): list of page numbers to extract
|
||||
|
||||
Returns:
|
||||
list[Image.Image]: list of page thumbnails
|
||||
"""
|
||||
|
||||
img: Image.Image
|
||||
suffix = file_path.suffix.lower()
|
||||
assert suffix == ".pdf", "This function only supports PDF files."
|
||||
try:
|
||||
import fitz
|
||||
except ImportError:
|
||||
raise ImportError("Please install PyMuPDF: 'pip install PyMuPDF'")
|
||||
|
||||
doc = fitz.open(file_path)
|
||||
|
||||
output_imgs = []
|
||||
for page_number in pages:
|
||||
page = doc.load_page(page_number)
|
||||
pm = page.get_pixmap(dpi=dpi)
|
||||
img = Image.frombytes("RGB", [pm.width, pm.height], pm.samples)
|
||||
output_imgs.append(convert_image_to_base64(img))
|
||||
|
||||
return output_imgs
|
||||
|
||||
|
||||
def convert_image_to_base64(img: Image.Image) -> str:
|
||||
# convert the image into base64
|
||||
img_bytes = BytesIO()
|
||||
img.save(img_bytes, format="PNG")
|
||||
img_base64 = base64.b64encode(img_bytes.getvalue()).decode("utf-8")
|
||||
img_base64 = f"data:image/png;base64,{img_base64}"
|
||||
|
||||
return img_base64
|
||||
|
||||
|
||||
class PDFThumbnailReader(PDFReader):
|
||||
"""PDF parser with thumbnail for each page."""
|
||||
|
||||
def __init__(self) -> None:
|
||||
"""
|
||||
Initialize PDFReader.
|
||||
"""
|
||||
super().__init__(return_full_document=False)
|
||||
|
||||
def load_data(
|
||||
self,
|
||||
file: Path,
|
||||
extra_info: Optional[Dict] = None,
|
||||
fs: Optional[AbstractFileSystem] = None,
|
||||
) -> List[Document]:
|
||||
"""Parse file."""
|
||||
documents = super().load_data(file, extra_info, fs)
|
||||
|
||||
page_numbers_str = []
|
||||
filtered_docs = []
|
||||
is_int_page_number: dict[str, bool] = {}
|
||||
|
||||
for doc in documents:
|
||||
if "page_label" in doc.metadata:
|
||||
page_num_str = doc.metadata["page_label"]
|
||||
page_numbers_str.append(page_num_str)
|
||||
try:
|
||||
_ = int(page_num_str)
|
||||
is_int_page_number[page_num_str] = True
|
||||
filtered_docs.append(doc)
|
||||
except ValueError:
|
||||
is_int_page_number[page_num_str] = False
|
||||
continue
|
||||
|
||||
documents = filtered_docs
|
||||
page_numbers = list(range(len(page_numbers_str)))
|
||||
|
||||
print("Page numbers:", len(page_numbers))
|
||||
page_thumbnails = get_page_thumbnails(file, page_numbers)
|
||||
|
||||
documents.extend(
|
||||
[
|
||||
Document(
|
||||
text="Page thumbnail",
|
||||
metadata={
|
||||
"image_origin": page_thumbnail,
|
||||
"type": "thumbnail",
|
||||
"page_label": page_number,
|
||||
**(extra_info if extra_info is not None else {}),
|
||||
},
|
||||
)
|
||||
for (page_thumbnail, page_number) in zip(
|
||||
page_thumbnails, page_numbers_str
|
||||
)
|
||||
if is_int_page_number[page_number]
|
||||
]
|
||||
)
|
||||
|
||||
return documents
|
||||
22
libs/kotaemon/kotaemon/loaders/txt_loader.py
Normal file
|
|
@ -0,0 +1,22 @@
|
|||
from pathlib import Path
|
||||
from typing import Optional
|
||||
|
||||
from kotaemon.base import Document
|
||||
|
||||
from .base import BaseReader
|
||||
|
||||
|
||||
class TxtReader(BaseReader):
|
||||
def run(
|
||||
self, file_path: str | Path, extra_info: Optional[dict] = None, **kwargs
|
||||
) -> list[Document]:
|
||||
return self.load_data(Path(file_path), extra_info=extra_info, **kwargs)
|
||||
|
||||
def load_data(
|
||||
self, file_path: Path, extra_info: Optional[dict] = None, **kwargs
|
||||
) -> list[Document]:
|
||||
with open(file_path, "r") as f:
|
||||
text = f.read()
|
||||
|
||||
metadata = extra_info or {}
|
||||
return [Document(text=text, metadata=metadata)]
|
||||
|
|
@ -12,7 +12,7 @@ pip install xlrd
|
|||
from pathlib import Path
|
||||
from typing import Any, Dict, List, Optional
|
||||
|
||||
from llama_index.readers.base import BaseReader
|
||||
from llama_index.core.readers.base import BaseReader
|
||||
|
||||
from kotaemon.base import Document
|
||||
|
||||
|
|
|
|||
|
|
@ -1,12 +1,19 @@
|
|||
import json
|
||||
import logging
|
||||
from typing import Any, List
|
||||
|
||||
import requests
|
||||
from decouple import config
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
|
||||
def generate_gpt4v(
|
||||
endpoint: str, images: str | List[str], prompt: str, max_tokens: int = 512
|
||||
endpoint: str,
|
||||
images: str | List[str],
|
||||
prompt: str,
|
||||
max_tokens: int = 512,
|
||||
max_images: int = 10,
|
||||
) -> str:
|
||||
# OpenAI API Key
|
||||
api_key = config("AZURE_OPENAI_API_KEY", default="")
|
||||
|
|
@ -27,24 +34,36 @@ def generate_gpt4v(
|
|||
"type": "image_url",
|
||||
"image_url": {"url": image},
|
||||
}
|
||||
for image in images
|
||||
for image in images[:max_images]
|
||||
],
|
||||
}
|
||||
],
|
||||
"max_tokens": max_tokens,
|
||||
"temperature": 0,
|
||||
}
|
||||
|
||||
try:
|
||||
if len(images) > max_images:
|
||||
print(f"Truncated to {max_images} images (original {len(images)} images")
|
||||
|
||||
response = requests.post(endpoint, headers=headers, json=payload)
|
||||
|
||||
try:
|
||||
response.raise_for_status()
|
||||
except Exception as e:
|
||||
logger.exception(f"Error generating gpt4v: {response.text}; error {e}")
|
||||
return ""
|
||||
|
||||
output = response.json()
|
||||
output = output["choices"][0]["message"]["content"]
|
||||
except Exception:
|
||||
output = ""
|
||||
return output
|
||||
|
||||
|
||||
def stream_gpt4v(
|
||||
endpoint: str, images: str | List[str], prompt: str, max_tokens: int = 512
|
||||
endpoint: str,
|
||||
images: str | List[str],
|
||||
prompt: str,
|
||||
max_tokens: int = 512,
|
||||
max_images: int = 10,
|
||||
) -> Any:
|
||||
# OpenAI API Key
|
||||
api_key = config("AZURE_OPENAI_API_KEY", default="")
|
||||
|
|
@ -65,17 +84,22 @@ def stream_gpt4v(
|
|||
"type": "image_url",
|
||||
"image_url": {"url": image},
|
||||
}
|
||||
for image in images
|
||||
for image in images[:max_images]
|
||||
],
|
||||
}
|
||||
],
|
||||
"max_tokens": max_tokens,
|
||||
"stream": True,
|
||||
"logprobs": True,
|
||||
"temperature": 0,
|
||||
}
|
||||
if len(images) > max_images:
|
||||
print(f"Truncated to {max_images} images (original {len(images)} images")
|
||||
try:
|
||||
response = requests.post(endpoint, headers=headers, json=payload, stream=True)
|
||||
assert response.status_code == 200, str(response.content)
|
||||
output = ""
|
||||
logprobs = []
|
||||
for line in response.iter_lines():
|
||||
if line:
|
||||
if line.startswith(b"\xef\xbb\xbf"):
|
||||
|
|
@ -89,8 +113,23 @@ def stream_gpt4v(
|
|||
except Exception:
|
||||
break
|
||||
if len(line["choices"]):
|
||||
if line["choices"][0].get("logprobs") is None:
|
||||
_logprobs = []
|
||||
else:
|
||||
_logprobs = [
|
||||
logprob["logprob"]
|
||||
for logprob in line["choices"][0]["logprobs"].get(
|
||||
"content", []
|
||||
)
|
||||
]
|
||||
|
||||
output += line["choices"][0]["delta"].get("content", "")
|
||||
yield line["choices"][0]["delta"].get("content", "")
|
||||
except Exception:
|
||||
logprobs += _logprobs
|
||||
yield line["choices"][0]["delta"].get("content", ""), _logprobs
|
||||
|
||||
except Exception as e:
|
||||
logger.error(f"Error streaming gpt4v {e}")
|
||||
logprobs = []
|
||||
output = ""
|
||||
return output
|
||||
|
||||
return output, logprobs
|
||||
|
|
|
|||
|
|
@ -2,12 +2,14 @@ from .docstores import (
|
|||
BaseDocumentStore,
|
||||
ElasticsearchDocumentStore,
|
||||
InMemoryDocumentStore,
|
||||
LanceDBDocumentStore,
|
||||
SimpleFileDocumentStore,
|
||||
)
|
||||
from .vectorstores import (
|
||||
BaseVectorStore,
|
||||
ChromaVectorStore,
|
||||
InMemoryVectorStore,
|
||||
LanceDBVectorStore,
|
||||
SimpleFileVectorStore,
|
||||
)
|
||||
|
||||
|
|
@ -17,9 +19,11 @@ __all__ = [
|
|||
"InMemoryDocumentStore",
|
||||
"ElasticsearchDocumentStore",
|
||||
"SimpleFileDocumentStore",
|
||||
"LanceDBDocumentStore",
|
||||
# Vector stores
|
||||
"BaseVectorStore",
|
||||
"ChromaVectorStore",
|
||||
"InMemoryVectorStore",
|
||||
"SimpleFileVectorStore",
|
||||
"LanceDBVectorStore",
|
||||
]
|
||||
|
|
|
|||
|
|
@ -1,6 +1,7 @@
|
|||
from .base import BaseDocumentStore
|
||||
from .elasticsearch import ElasticsearchDocumentStore
|
||||
from .in_memory import InMemoryDocumentStore
|
||||
from .lancedb import LanceDBDocumentStore
|
||||
from .simple_file import SimpleFileDocumentStore
|
||||
|
||||
__all__ = [
|
||||
|
|
@ -8,4 +9,5 @@ __all__ = [
|
|||
"InMemoryDocumentStore",
|
||||
"ElasticsearchDocumentStore",
|
||||
"SimpleFileDocumentStore",
|
||||
"LanceDBDocumentStore",
|
||||
]
|
||||
|
|
|
|||
|
|
@ -41,6 +41,13 @@ class BaseDocumentStore(ABC):
|
|||
"""Count number of documents"""
|
||||
...
|
||||
|
||||
@abstractmethod
|
||||
def query(
|
||||
self, query: str, top_k: int = 10, doc_ids: Optional[list] = None
|
||||
) -> List[Document]:
|
||||
"""Search document store using search query"""
|
||||
...
|
||||
|
||||
@abstractmethod
|
||||
def delete(self, ids: Union[List[str], str]):
|
||||
"""Delete document by id"""
|
||||
|
|
|
|||
|
|
@ -92,7 +92,10 @@ class ElasticsearchDocumentStore(BaseDocumentStore):
|
|||
"_id": doc_id,
|
||||
}
|
||||
requests.append(request)
|
||||
self.es_bulk(self.client, requests)
|
||||
|
||||
success, failed = self.es_bulk(self.client, requests)
|
||||
print("Added/Updated documents to index", success)
|
||||
print("Failed documents to index", failed)
|
||||
|
||||
if refresh_indices:
|
||||
self.client.indices.refresh(index=self.index_name)
|
||||
|
|
@ -131,16 +134,17 @@ class ElasticsearchDocumentStore(BaseDocumentStore):
|
|||
Returns:
|
||||
List[Document]: List of result documents
|
||||
"""
|
||||
query_dict: dict = {"query": {"match": {"content": query}}, "size": top_k}
|
||||
if doc_ids:
|
||||
query_dict["query"]["match"]["_id"] = {"values": doc_ids}
|
||||
query_dict: dict = {"match": {"content": query}}
|
||||
if doc_ids is not None:
|
||||
query_dict = {"bool": {"must": [query_dict, {"terms": {"_id": doc_ids}}]}}
|
||||
query_dict = {"query": query_dict, "size": top_k}
|
||||
return self.query_raw(query_dict)
|
||||
|
||||
def get(self, ids: Union[List[str], str]) -> List[Document]:
|
||||
"""Get document by id"""
|
||||
if not isinstance(ids, list):
|
||||
ids = [ids]
|
||||
query_dict = {"query": {"terms": {"_id": ids}}}
|
||||
query_dict = {"query": {"terms": {"_id": ids}}, "size": 10000}
|
||||
return self.query_raw(query_dict)
|
||||
|
||||
def count(self) -> int:
|
||||
|
|
|
|||
|
|
@ -81,6 +81,12 @@ class InMemoryDocumentStore(BaseDocumentStore):
|
|||
# Also, for portability, use SQLAlchemy for document store.
|
||||
self._store = {key: Document.from_dict(value) for key, value in store.items()}
|
||||
|
||||
def query(
|
||||
self, query: str, top_k: int = 10, doc_ids: Optional[list] = None
|
||||
) -> List[Document]:
|
||||
"""Perform full-text search on document store"""
|
||||
return []
|
||||
|
||||
def __persist_flow__(self):
|
||||
return {}
|
||||
|
||||
|
|
|
|||
153
libs/kotaemon/kotaemon/storages/docstores/lancedb.py
Normal file
|
|
@ -0,0 +1,153 @@
|
|||
import json
|
||||
from typing import List, Optional, Union
|
||||
|
||||
from kotaemon.base import Document
|
||||
|
||||
from .base import BaseDocumentStore
|
||||
|
||||
MAX_DOCS_TO_GET = 10**4
|
||||
|
||||
|
||||
class LanceDBDocumentStore(BaseDocumentStore):
|
||||
"""LancdDB document store which support full-text search query"""
|
||||
|
||||
def __init__(self, path: str = "lancedb", collection_name: str = "docstore"):
|
||||
try:
|
||||
import lancedb
|
||||
except ImportError:
|
||||
raise ImportError(
|
||||
"Please install lancedb: 'pip install lancedb tanvity-py'"
|
||||
)
|
||||
|
||||
self.db_uri = path
|
||||
self.collection_name = collection_name
|
||||
self.db_connection = lancedb.connect(self.db_uri) # type: ignore
|
||||
|
||||
def add(
|
||||
self,
|
||||
docs: Union[Document, List[Document]],
|
||||
ids: Optional[Union[List[str], str]] = None,
|
||||
refresh_indices: bool = True,
|
||||
**kwargs,
|
||||
):
|
||||
"""Load documents into lancedb storage."""
|
||||
doc_ids = ids if ids else [doc.doc_id for doc in docs]
|
||||
data: list[dict[str, str]] | None = [
|
||||
{
|
||||
"id": doc_id,
|
||||
"text": doc.text,
|
||||
"attributes": json.dumps(doc.metadata),
|
||||
}
|
||||
for doc_id, doc in zip(doc_ids, docs)
|
||||
]
|
||||
|
||||
if self.collection_name not in self.db_connection.table_names():
|
||||
if data:
|
||||
document_collection = self.db_connection.create_table(
|
||||
self.collection_name, data=data, mode="overwrite"
|
||||
)
|
||||
else:
|
||||
# add data to existing table
|
||||
document_collection = self.db_connection.open_table(self.collection_name)
|
||||
if data:
|
||||
document_collection.add(data)
|
||||
|
||||
if refresh_indices:
|
||||
document_collection.create_fts_index(
|
||||
"text",
|
||||
tokenizer_name="en_stem",
|
||||
replace=True,
|
||||
)
|
||||
|
||||
def query(
|
||||
self, query: str, top_k: int = 10, doc_ids: Optional[list] = None
|
||||
) -> List[Document]:
|
||||
if doc_ids:
|
||||
id_filter = ", ".join([f"'{_id}'" for _id in doc_ids])
|
||||
query_filter = f"id in ({id_filter})"
|
||||
else:
|
||||
query_filter = None
|
||||
try:
|
||||
document_collection = self.db_connection.open_table(self.collection_name)
|
||||
if query_filter:
|
||||
docs = (
|
||||
document_collection.search(query, query_type="fts")
|
||||
.where(query_filter, prefilter=True)
|
||||
.limit(top_k)
|
||||
.to_list()
|
||||
)
|
||||
else:
|
||||
docs = (
|
||||
document_collection.search(query, query_type="fts")
|
||||
.limit(top_k)
|
||||
.to_list()
|
||||
)
|
||||
except (ValueError, FileNotFoundError):
|
||||
docs = []
|
||||
return [
|
||||
Document(
|
||||
id_=doc["id"],
|
||||
text=doc["text"] if doc["text"] else "<empty>",
|
||||
metadata=json.loads(doc["attributes"]),
|
||||
)
|
||||
for doc in docs
|
||||
]
|
||||
|
||||
def get(self, ids: Union[List[str], str]) -> List[Document]:
|
||||
"""Get document by id"""
|
||||
if not isinstance(ids, list):
|
||||
ids = [ids]
|
||||
|
||||
id_filter = ", ".join([f"'{_id}'" for _id in ids])
|
||||
try:
|
||||
document_collection = self.db_connection.open_table(self.collection_name)
|
||||
query_filter = f"id in ({id_filter})"
|
||||
docs = (
|
||||
document_collection.search()
|
||||
.where(query_filter)
|
||||
.limit(MAX_DOCS_TO_GET)
|
||||
.to_list()
|
||||
)
|
||||
except (ValueError, FileNotFoundError):
|
||||
docs = []
|
||||
return [
|
||||
Document(
|
||||
id_=doc["id"],
|
||||
text=doc["text"] if doc["text"] else "<empty>",
|
||||
metadata=json.loads(doc["attributes"]),
|
||||
)
|
||||
for doc in docs
|
||||
]
|
||||
|
||||
def delete(self, ids: Union[List[str], str], refresh_indices: bool = True):
|
||||
"""Delete document by id"""
|
||||
if not isinstance(ids, list):
|
||||
ids = [ids]
|
||||
|
||||
document_collection = self.db_connection.open_table(self.collection_name)
|
||||
id_filter = ", ".join([f"'{_id}'" for _id in ids])
|
||||
query_filter = f"id in ({id_filter})"
|
||||
document_collection.delete(query_filter)
|
||||
|
||||
if refresh_indices:
|
||||
document_collection.create_fts_index(
|
||||
"text",
|
||||
tokenizer_name="en_stem",
|
||||
replace=True,
|
||||
)
|
||||
|
||||
def drop(self):
|
||||
"""Drop the document store"""
|
||||
self.db_connection.drop_table(self.collection_name)
|
||||
|
||||
def count(self) -> int:
|
||||
raise NotImplementedError
|
||||
|
||||
def get_all(self) -> List[Document]:
|
||||
raise NotImplementedError
|
||||
|
||||
def __persist_flow__(self):
|
||||
return {
|
||||
"db_uri": self.db_uri,
|
||||
"collection_name": self.collection_name,
|
||||
}
|
||||
|
|
@ -1,6 +1,7 @@
|
|||
from .base import BaseVectorStore
|
||||
from .chroma import ChromaVectorStore
|
||||
from .in_memory import InMemoryVectorStore
|
||||
from .lancedb import LanceDBVectorStore
|
||||
from .simple_file import SimpleFileVectorStore
|
||||
|
||||
__all__ = [
|
||||
|
|
@ -8,4 +9,5 @@ __all__ = [
|
|||
"ChromaVectorStore",
|
||||
"InMemoryVectorStore",
|
||||
"SimpleFileVectorStore",
|
||||
"LanceDBVectorStore",
|
||||
]
|
||||
|
|
|
|||
|
|
@ -3,10 +3,10 @@ from __future__ import annotations
|
|||
from abc import ABC, abstractmethod
|
||||
from typing import Any, Optional
|
||||
|
||||
from llama_index.schema import NodeRelationship, RelatedNodeInfo
|
||||
from llama_index.vector_stores.types import BasePydanticVectorStore
|
||||
from llama_index.vector_stores.types import VectorStore as LIVectorStore
|
||||
from llama_index.vector_stores.types import VectorStoreQuery
|
||||
from llama_index.core.schema import NodeRelationship, RelatedNodeInfo
|
||||
from llama_index.core.vector_stores.types import BasePydanticVectorStore
|
||||
from llama_index.core.vector_stores.types import VectorStore as LIVectorStore
|
||||
from llama_index.core.vector_stores.types import VectorStoreQuery
|
||||
|
||||
from kotaemon.base import DocumentWithEmbedding
|
||||
|
||||
|
|
|
|||
|
|
@ -2,8 +2,8 @@
|
|||
from typing import Any, Optional, Type
|
||||
|
||||
import fsspec
|
||||
from llama_index.vector_stores import SimpleVectorStore as LISimpleVectorStore
|
||||
from llama_index.vector_stores.simple import SimpleVectorStoreData
|
||||
from llama_index.core.vector_stores import SimpleVectorStore as LISimpleVectorStore
|
||||
from llama_index.core.vector_stores.simple import SimpleVectorStoreData
|
||||
|
||||
from .base import LlamaIndexVectorStore
|
||||
|
||||
|
|
|
|||
87
libs/kotaemon/kotaemon/storages/vectorstores/lancedb.py
Normal file
|
|
@ -0,0 +1,87 @@
|
|||
from typing import Any, List, Type, cast
|
||||
|
||||
from llama_index.core.vector_stores.types import MetadataFilters
|
||||
from llama_index.vector_stores.lancedb import LanceDBVectorStore as LILanceDBVectorStore
|
||||
from llama_index.vector_stores.lancedb import base as base_lancedb
|
||||
|
||||
from .base import LlamaIndexVectorStore
|
||||
|
||||
# custom monkey patch for LanceDB
|
||||
original_to_lance_filter = base_lancedb._to_lance_filter
|
||||
|
||||
|
||||
def custom_to_lance_filter(
|
||||
standard_filters: MetadataFilters, metadata_keys: list
|
||||
) -> Any:
|
||||
for filter in standard_filters.filters:
|
||||
if isinstance(filter.value, list):
|
||||
# quote string values if filter are list of strings
|
||||
if filter.value and isinstance(filter.value[0], str):
|
||||
filter.value = [f"'{v}'" for v in filter.value]
|
||||
|
||||
return original_to_lance_filter(standard_filters, metadata_keys)
|
||||
|
||||
|
||||
# skip table existence check
|
||||
LILanceDBVectorStore._table_exists = lambda _: False
|
||||
base_lancedb._to_lance_filter = custom_to_lance_filter
|
||||
|
||||
|
||||
class LanceDBVectorStore(LlamaIndexVectorStore):
|
||||
_li_class: Type[LILanceDBVectorStore] = LILanceDBVectorStore
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
path: str = "./lancedb",
|
||||
collection_name: str = "default",
|
||||
**kwargs: Any,
|
||||
):
|
||||
self._path = path
|
||||
self._collection_name = collection_name
|
||||
|
||||
try:
|
||||
import lancedb
|
||||
except ImportError:
|
||||
raise ImportError(
|
||||
"Please install lancedb: 'pip install lancedb tanvity-py'"
|
||||
)
|
||||
|
||||
db_connection = lancedb.connect(path) # type: ignore
|
||||
try:
|
||||
table = db_connection.open_table(collection_name)
|
||||
except FileNotFoundError:
|
||||
table = None
|
||||
|
||||
self._kwargs = kwargs
|
||||
|
||||
# pass through for nice IDE support
|
||||
super().__init__(
|
||||
uri=path,
|
||||
table_name=collection_name,
|
||||
table=table,
|
||||
**kwargs,
|
||||
)
|
||||
self._client = cast(LILanceDBVectorStore, self._client)
|
||||
self._client._metadata_keys = ["file_id"]
|
||||
|
||||
def delete(self, ids: List[str], **kwargs):
|
||||
"""Delete vector embeddings from vector stores
|
||||
|
||||
Args:
|
||||
ids: List of ids of the embeddings to be deleted
|
||||
kwargs: meant for vectorstore-specific parameters
|
||||
"""
|
||||
self._client.delete_nodes(ids)
|
||||
|
||||
def drop(self):
|
||||
"""Delete entire collection from vector stores"""
|
||||
self._client.client.drop_table(self.collection_name)
|
||||
|
||||
def count(self) -> int:
|
||||
raise NotImplementedError
|
||||
|
||||
def __persist_flow__(self):
|
||||
return {
|
||||
"path": self._path,
|
||||
"collection_name": self._collection_name,
|
||||
}
|
||||
|
|
@ -3,8 +3,8 @@ from pathlib import Path
|
|||
from typing import Any, Optional, Type
|
||||
|
||||
import fsspec
|
||||
from llama_index.vector_stores import SimpleVectorStore as LISimpleVectorStore
|
||||
from llama_index.vector_stores.simple import SimpleVectorStoreData
|
||||
from llama_index.core.vector_stores import SimpleVectorStore as LISimpleVectorStore
|
||||
from llama_index.core.vector_stores.simple import SimpleVectorStoreData
|
||||
|
||||
from kotaemon.base import DocumentWithEmbedding
|
||||
|
||||
|
|
|
|||
|
|
@ -26,9 +26,11 @@ dependencies = [
|
|||
"langchain-openai>=0.1.4,<0.2.0",
|
||||
"openai>=1.23.6,<2",
|
||||
"theflow>=0.8.6,<0.9.0",
|
||||
"llama-index==0.9.48",
|
||||
"llama-index>=0.10.40,<0.11.0",
|
||||
"llama-index-vector-stores-chroma>=0.1.9",
|
||||
"llama-index-vector-stores-lancedb",
|
||||
"llama-hub>=0.0.79,<0.1.0",
|
||||
"gradio>=4.26.0,<5",
|
||||
"gradio>=4.31.0,<4.40",
|
||||
"openpyxl>=3.1.2,<3.2",
|
||||
"cookiecutter>=2.6.0,<2.7",
|
||||
"click>=8.1.7,<9",
|
||||
|
|
@ -36,13 +38,9 @@ dependencies = [
|
|||
"trogon>=0.5.0,<0.6",
|
||||
"tenacity>=8.2.3,<8.3",
|
||||
"python-dotenv>=1.0.1,<1.1",
|
||||
"chromadb>=0.4.21,<0.5",
|
||||
"unstructured==0.13.4",
|
||||
"pypdf>=4.2.0,<4.3",
|
||||
"PyMuPDF>=1.23",
|
||||
"html2text==2024.2.26",
|
||||
"fastembed==0.2.6",
|
||||
"llama-cpp-python>=0.2.72,<0.3",
|
||||
"azure-ai-documentintelligence",
|
||||
"cohere>=5.3.2,<5.4",
|
||||
]
|
||||
readme = "README.md"
|
||||
|
|
@ -63,11 +61,12 @@ adv = [
|
|||
"duckduckgo-search>=6.1.0,<6.2",
|
||||
"googlesearch-python>=1.2.4,<1.3",
|
||||
"python-docx>=1.1.0,<1.2",
|
||||
"unstructured[pdf]==0.13.4",
|
||||
"sentence_transformers==2.7.0",
|
||||
"elasticsearch>=8.13.0,<8.14",
|
||||
"pdfservices-sdk @ git+https://github.com/niallcm/pdfservices-python-sdk.git@bump-and-unfreeze-requirements",
|
||||
"beautifulsoup4>=4.12.3,<4.13",
|
||||
"plotly",
|
||||
"tabulate",
|
||||
"fast_langdetect",
|
||||
"azure-ai-documentintelligence",
|
||||
]
|
||||
dev = [
|
||||
"ipython",
|
||||
|
|
|
|||
|
|
@ -2,7 +2,7 @@ from pathlib import Path
|
|||
from unittest.mock import patch
|
||||
|
||||
from langchain.schema import Document as LangchainDocument
|
||||
from llama_index.node_parser import SimpleNodeParser
|
||||
from llama_index.core.node_parser import SimpleNodeParser
|
||||
|
||||
from kotaemon.base import Document
|
||||
from kotaemon.loaders import (
|
||||
|
|
|
|||
|
|
@ -1,4 +1,4 @@
|
|||
from llama_index.schema import NodeRelationship
|
||||
from llama_index.core.schema import NodeRelationship
|
||||
|
||||
from kotaemon.base import Document
|
||||
from kotaemon.indices.splitters import TokenSplitter
|
||||
|
|
|
|||
1
libs/ktem/.gitignore
vendored
|
|
@ -1,2 +1,3 @@
|
|||
14-1_抜粋-1.pdf
|
||||
_example_.db
|
||||
ktem/assets/prebuilt/
|
||||
|
|
|
|||
|
|
@ -4,6 +4,7 @@ from typing import Optional
|
|||
import gradio as gr
|
||||
import pluggy
|
||||
from ktem import extension_protocol
|
||||
from ktem.assets import PDFJS_PREBUILT_DIR
|
||||
from ktem.components import reasonings
|
||||
from ktem.exceptions import HookAlreadyDeclared, HookNotDeclared
|
||||
from ktem.index import IndexManager
|
||||
|
|
@ -36,6 +37,7 @@ class BaseApp:
|
|||
def __init__(self):
|
||||
self.dev_mode = getattr(settings, "KH_MODE", "") == "dev"
|
||||
self.app_name = getattr(settings, "KH_APP_NAME", "Kotaemon")
|
||||
self.app_version = getattr(settings, "KH_APP_VERSION", "")
|
||||
self.f_user_management = getattr(settings, "KH_FEATURE_USER_MANAGEMENT", False)
|
||||
self._theme = gr.Theme.from_hub("lone17/kotaemon")
|
||||
|
||||
|
|
@ -44,6 +46,13 @@ class BaseApp:
|
|||
self._css = fi.read()
|
||||
with (dir_assets / "js" / "main.js").open() as fi:
|
||||
self._js = fi.read()
|
||||
self._js = self._js.replace("KH_APP_VERSION", self.app_version)
|
||||
with (dir_assets / "js" / "pdf_viewer.js").open() as fi:
|
||||
self._pdf_view_js = fi.read()
|
||||
self._pdf_view_js = self._pdf_view_js.replace(
|
||||
"PDFJS_PREBUILT_DIR", str(PDFJS_PREBUILT_DIR)
|
||||
)
|
||||
|
||||
self._favicon = str(dir_assets / "img" / "favicon.svg")
|
||||
|
||||
self.default_settings = SettingGroup(
|
||||
|
|
@ -156,11 +165,17 @@ class BaseApp:
|
|||
"""Called when the app is created"""
|
||||
|
||||
def make(self):
|
||||
external_js = """
|
||||
<script type="module" src="https://cdn.skypack.dev/pdfjs-viewer-element"></script>
|
||||
"""
|
||||
|
||||
with gr.Blocks(
|
||||
theme=self._theme,
|
||||
css=self._css,
|
||||
title=self.app_name,
|
||||
analytics_enabled=False,
|
||||
js=self._js,
|
||||
head=external_js,
|
||||
) as demo:
|
||||
self.app = demo
|
||||
self.settings_state.render()
|
||||
|
|
@ -173,6 +188,8 @@ class BaseApp:
|
|||
self.register_events()
|
||||
self.on_app_created()
|
||||
|
||||
demo.load(None, None, None, js=self._pdf_view_js)
|
||||
|
||||
return demo
|
||||
|
||||
def declare_public_events(self):
|
||||
|
|
@ -200,7 +217,6 @@ class BaseApp:
|
|||
|
||||
def on_app_created(self):
|
||||
"""Execute on app created callbacks"""
|
||||
self.app.load(lambda: None, None, None, js=f"() => {{{self._js}}}")
|
||||
self._on_app_created()
|
||||
for value in self.__dict__.values():
|
||||
if isinstance(value, BasePage):
|
||||
|
|
|
|||
6
libs/ktem/ktem/assets/__init__.py
Normal file
|
|
@ -0,0 +1,6 @@
|
|||
from pathlib import Path
|
||||
|
||||
from decouple import config
|
||||
|
||||
PDFJS_VERSION_DIST: str = config("PDFJS_VERSION_DIST", "pdfjs-4.0.379-dist")
|
||||
PDFJS_PREBUILT_DIR: Path = Path(__file__).parent / "prebuilt" / PDFJS_VERSION_DIST
|
||||
|
|
@ -147,6 +147,16 @@ mark {
|
|||
max-height: 42px;
|
||||
}
|
||||
|
||||
/* Hide sort buttons at gr.DataFrame */
|
||||
.sort-button {
|
||||
display: none !important;
|
||||
}
|
||||
|
||||
/* Show sort button only in File list*/
|
||||
#file_list_view .sort-button {
|
||||
display: block !important;
|
||||
}
|
||||
|
||||
.scrollable {
|
||||
overflow-y: auto;
|
||||
}
|
||||
|
|
@ -158,3 +168,58 @@ mark {
|
|||
.unset-overflow {
|
||||
overflow: unset !important;
|
||||
}
|
||||
|
||||
/*body {*/
|
||||
/* margin: 0;*/
|
||||
/* font-family: Arial, sans-serif;*/
|
||||
/*}*/
|
||||
|
||||
pdfjs-viewer-element {
|
||||
height: 100vh;
|
||||
height: 100dvh;
|
||||
}
|
||||
|
||||
/* Modal styles */
|
||||
|
||||
.modal {
|
||||
display: none;
|
||||
position: relative;
|
||||
z-index: 1;
|
||||
left: 0;
|
||||
top: 0;
|
||||
width: 100%;
|
||||
height: 100%;
|
||||
overflow: auto;
|
||||
background-color: rgb(0, 0, 0);
|
||||
background-color: rgba(0, 0, 0, 0.4);
|
||||
}
|
||||
|
||||
.modal-header {
|
||||
padding: 0px 10px
|
||||
}
|
||||
|
||||
.modal-content {
|
||||
background-color: #fefefe;
|
||||
height: 110%;
|
||||
display: flex;
|
||||
flex-direction: column;
|
||||
}
|
||||
|
||||
.close {
|
||||
color: #aaa;
|
||||
align-self: flex-end;
|
||||
font-size: 28px;
|
||||
font-weight: bold;
|
||||
}
|
||||
|
||||
.close:hover,
|
||||
.close:focus {
|
||||
color: black;
|
||||
text-decoration: none;
|
||||
cursor: pointer;
|
||||
}
|
||||
|
||||
.modal-body {
|
||||
flex: 1;
|
||||
overflow: auto;
|
||||
}
|
||||
|
|
|
|||
1
libs/ktem/ktem/assets/icons/delete.svg
Normal file
{kind=link}
|
|
@ -0,0 +1 @@
|
|||
<svg xmlns="http://www.w3.org/2000/svg" width="24" height="24" fill="none" class="h-5 w-5 shrink-0"><path fill="#f93a37" fill-rule="evenodd" d="M10.556 4a1 1 0 0 0-.97.751l-.292 1.14h5.421l-.293-1.14A1 1 0 0 0 13.453 4zm6.224 1.892-.421-1.639A3 3 0 0 0 13.453 2h-2.897A3 3 0 0 0 7.65 4.253l-.421 1.639H4a1 1 0 1 0 0 2h.1l1.215 11.425A3 3 0 0 0 8.3 22h7.4a3 3 0 0 0 2.984-2.683l1.214-11.425H20a1 1 0 1 0 0-2zm1.108 2H6.112l1.192 11.214A1 1 0 0 0 8.3 20h7.4a1 1 0 0 0 .995-.894zM10 10a1 1 0 0 1 1 1v5a1 1 0 1 1-2 0v-5a1 1 0 0 1 1-1m4 0a1 1 0 0 1 1 1v5a1 1 0 1 1-2 0v-5a1 1 0 0 1 1-1" clip-rule="evenodd"/></svg>
|
||||
|
After Width: | Height: | Size: 610 B |
1
libs/ktem/ktem/assets/icons/new.svg
Normal file
{kind=link}
|
|
@ -0,0 +1 @@
|
|||
<svg xmlns="http://www.w3.org/2000/svg" width="24" height="24" fill="#10b981" class="icon-xl-heavy"><path d="M15.673 3.913a3.121 3.121 0 1 1 4.414 4.414l-5.937 5.937a5 5 0 0 1-2.828 1.415l-2.18.31a1 1 0 0 1-1.132-1.13l.311-2.18A5 5 0 0 1 9.736 9.85zm3 1.414a1.12 1.12 0 0 0-1.586 0l-5.937 5.937a3 3 0 0 0-.849 1.697l-.123.86.86-.122a3 3 0 0 0 1.698-.849l5.937-5.937a1.12 1.12 0 0 0 0-1.586M11 4a1 1 0 0 1-1 1c-.998 0-1.702.008-2.253.06-.54.052-.862.141-1.109.267a3 3 0 0 0-1.311 1.311c-.134.263-.226.611-.276 1.216C5.001 8.471 5 9.264 5 10.4v3.2c0 1.137 0 1.929.051 2.546.05.605.142.953.276 1.216a3 3 0 0 0 1.311 1.311c.263.134.611.226 1.216.276.617.05 1.41.051 2.546.051h3.2c1.137 0 1.929 0 2.546-.051.605-.05.953-.142 1.216-.276a3 3 0 0 0 1.311-1.311c.126-.247.215-.569.266-1.108.053-.552.06-1.256.06-2.255a1 1 0 1 1 2 .002c0 .978-.006 1.78-.069 2.442-.064.673-.192 1.27-.475 1.827a5 5 0 0 1-2.185 2.185c-.592.302-1.232.428-1.961.487C15.6 21 14.727 21 13.643 21h-3.286c-1.084 0-1.958 0-2.666-.058-.728-.06-1.369-.185-1.96-.487a5 5 0 0 1-2.186-2.185c-.302-.592-.428-1.233-.487-1.961C3 15.6 3 14.727 3 13.643v-3.286c0-1.084 0-1.958.058-2.666.06-.729.185-1.369.487-1.961A5 5 0 0 1 5.73 3.545c.556-.284 1.154-.411 1.827-.475C8.22 3.007 9.021 3 10 3a1 1 0 0 1 1 1"/></svg>
|
||||
|
After Width: | Height: | Size: 1.2 KiB |
1
libs/ktem/ktem/assets/icons/rename.svg
Normal file
{kind=link}
|
|
@ -0,0 +1 @@
|
|||
<svg xmlns="http://www.w3.org/2000/svg" width="24" height="24" fill="none" class="h-5 w-5 shrink-0"><path fill="#cecece" fill-rule="evenodd" d="M13.293 4.293a4.536 4.536 0 1 1 6.414 6.414l-1 1-7.094 7.094A5 5 0 0 1 8.9 20.197l-4.736.79a1 1 0 0 1-1.15-1.151l.789-4.736a5 5 0 0 1 1.396-2.713zM13 7.414l-6.386 6.387a3 3 0 0 0-.838 1.628l-.56 3.355 3.355-.56a3 3 0 0 0 1.628-.837L16.586 11zm5 2.172L14.414 6l.293-.293a2.536 2.536 0 0 1 3.586 3.586z" clip-rule="evenodd"/></svg>
|
||||
|
After Width: | Height: | Size: 474 B |
1
libs/ktem/ktem/assets/icons/sidebar.svg
Normal file
{kind=link}
|
|
@ -0,0 +1 @@
|
|||
<svg xmlns="http://www.w3.org/2000/svg" width="24" height="24" fill="none" class="icon-xl-heavy"><path fill="#cecece" fill-rule="evenodd" d="M8.857 3h6.286c1.084 0 1.958 0 2.666.058.729.06 1.369.185 1.961.487a5 5 0 0 1 2.185 2.185c.302.592.428 1.233.487 1.961.058.708.058 1.582.058 2.666v3.286c0 1.084 0 1.958-.058 2.666-.06.729-.185 1.369-.487 1.961a5 5 0 0 1-2.185 2.185c-.592.302-1.232.428-1.961.487C17.1 21 16.227 21 15.143 21H8.857c-1.084 0-1.958 0-2.666-.058-.728-.06-1.369-.185-1.96-.487a5 5 0 0 1-2.186-2.185c-.302-.592-.428-1.232-.487-1.961C1.5 15.6 1.5 14.727 1.5 13.643v-3.286c0-1.084 0-1.958.058-2.666.06-.728.185-1.369.487-1.96A5 5 0 0 1 4.23 3.544c.592-.302 1.233-.428 1.961-.487C6.9 3 7.773 3 8.857 3M6.354 5.051c-.605.05-.953.142-1.216.276a3 3 0 0 0-1.311 1.311c-.134.263-.226.611-.276 1.216-.05.617-.051 1.41-.051 2.546v3.2c0 1.137 0 1.929.051 2.546.05.605.142.953.276 1.216a3 3 0 0 0 1.311 1.311c.263.134.611.226 1.216.276.617.05 1.41.051 2.546.051h.6V5h-.6c-1.137 0-1.929 0-2.546.051M11.5 5v14h3.6c1.137 0 1.929 0 2.546-.051.605-.05.953-.142 1.216-.276a3 3 0 0 0 1.311-1.311c.134-.263.226-.611.276-1.216.05-.617.051-1.41.051-2.546v-3.2c0-1.137 0-1.929-.051-2.546-.05-.605-.142-.953-.276-1.216a3 3 0 0 0-1.311-1.311c-.263-.134-.611-.226-1.216-.276C17.029 5.001 16.236 5 15.1 5zM5 8.5a1 1 0 0 1 1-1h1a1 1 0 1 1 0 2H6a1 1 0 0 1-1-1M5 12a1 1 0 0 1 1-1h1a1 1 0 1 1 0 2H6a1 1 0 0 1-1-1" clip-rule="evenodd"/></svg>
|
||||
|
After Width: | Height: | Size: 1.4 KiB |
|
|
@ -1,13 +1,18 @@
|
|||
let main_parent = document.getElementById("chat-tab").parentNode;
|
||||
function run() {
|
||||
let main_parent = document.getElementById("chat-tab").parentNode;
|
||||
|
||||
main_parent.childNodes[0].classList.add("header-bar");
|
||||
main_parent.style = "padding: 0; margin: 0";
|
||||
main_parent.parentNode.style = "gap: 0";
|
||||
main_parent.parentNode.parentNode.style = "padding: 0";
|
||||
main_parent.childNodes[0].classList.add("header-bar");
|
||||
main_parent.style = "padding: 0; margin: 0";
|
||||
main_parent.parentNode.style = "gap: 0";
|
||||
main_parent.parentNode.parentNode.style = "padding: 0";
|
||||
|
||||
const version_node = document.createElement("p");
|
||||
version_node.innerHTML = "version: KH_APP_VERSION";
|
||||
version_node.style = "position: fixed; top: 10px; right: 10px;";
|
||||
main_parent.appendChild(version_node);
|
||||
|
||||
// clpse
|
||||
globalThis.clpseFn = (id) => {
|
||||
// clpse
|
||||
globalThis.clpseFn = (id) => {
|
||||
var obj = document.getElementById('clpse-btn-' + id);
|
||||
obj.classList.toggle("clpse-active");
|
||||
var content = obj.nextElementSibling;
|
||||
|
|
@ -16,15 +21,17 @@ globalThis.clpseFn = (id) => {
|
|||
} else {
|
||||
content.style.display = "none";
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
// store info in local storage
|
||||
globalThis.setStorage = (key, value) => {
|
||||
localStorage.setItem(key, JSON.stringify(value))
|
||||
}
|
||||
globalThis.getStorage = (key, value) => {
|
||||
return JSON.parse(localStorage.getItem(key))
|
||||
}
|
||||
globalThis.removeFromStorage = (key) => {
|
||||
// store info in local storage
|
||||
globalThis.setStorage = (key, value) => {
|
||||
localStorage.setItem(key, value)
|
||||
}
|
||||
globalThis.getStorage = (key, value) => {
|
||||
item = localStorage.getItem(key);
|
||||
return item ? item : value;
|
||||
}
|
||||
globalThis.removeFromStorage = (key) => {
|
||||
localStorage.removeItem(key)
|
||||
}
|
||||
}
|
||||
|
|
|
|||
99
libs/ktem/ktem/assets/js/pdf_viewer.js
Normal file
|
|
@ -0,0 +1,99 @@
|
|||
function onBlockLoad () {
|
||||
var infor_panel_scroll_pos = 0;
|
||||
globalThis.createModal = () => {
|
||||
// Create modal for the 1st time if it does not exist
|
||||
var modal = document.getElementById("pdf-modal");
|
||||
var old_position = null;
|
||||
var old_width = null;
|
||||
var old_left = null;
|
||||
var expanded = false;
|
||||
|
||||
modal.id = "pdf-modal";
|
||||
modal.className = "modal";
|
||||
modal.innerHTML = `
|
||||
<div class="modal-content">
|
||||
<div class="modal-header">
|
||||
<span class="close" id="modal-close">×</span>
|
||||
<span class="close" id="modal-expand">⛶</span>
|
||||
</div>
|
||||
<div class="modal-body">
|
||||
<pdfjs-viewer-element id="pdf-viewer" viewer-path="/file=PDFJS_PREBUILT_DIR" locale="en" phrase="true">
|
||||
</pdfjs-viewer-element>
|
||||
</div>
|
||||
</div>
|
||||
`;
|
||||
|
||||
modal.querySelector("#modal-close").onclick = function() {
|
||||
modal.style.display = "none";
|
||||
var info_panel = document.getElementById("html-info-panel");
|
||||
if (info_panel) {
|
||||
info_panel.style.display = "block";
|
||||
}
|
||||
var scrollableDiv = document.getElementById("chat-info-panel");
|
||||
scrollableDiv.scrollTop = infor_panel_scroll_pos;
|
||||
};
|
||||
|
||||
modal.querySelector("#modal-expand").onclick = function () {
|
||||
expanded = !expanded;
|
||||
if (expanded) {
|
||||
old_position = modal.style.position;
|
||||
old_left = modal.style.left;
|
||||
old_width = modal.style.width;
|
||||
|
||||
modal.style.position = "fixed";
|
||||
modal.style.width = "70%";
|
||||
modal.style.left = "15%";
|
||||
} else {
|
||||
modal.style.position = old_position;
|
||||
modal.style.width = old_width;
|
||||
modal.style.left = old_left;
|
||||
}
|
||||
};
|
||||
}
|
||||
|
||||
// Function to open modal and display PDF
|
||||
globalThis.openModal = (event) => {
|
||||
event.preventDefault();
|
||||
var target = event.currentTarget;
|
||||
var src = target.getAttribute("data-src");
|
||||
var page = target.getAttribute("data-page");
|
||||
var search = target.getAttribute("data-search");
|
||||
var phrase = target.getAttribute("data-phrase");
|
||||
|
||||
var pdfViewer = document.getElementById("pdf-viewer");
|
||||
|
||||
current_src = pdfViewer.getAttribute("src");
|
||||
if (current_src != src) {
|
||||
pdfViewer.setAttribute("src", src);
|
||||
}
|
||||
pdfViewer.setAttribute("phrase", phrase);
|
||||
pdfViewer.setAttribute("search", search);
|
||||
pdfViewer.setAttribute("page", page);
|
||||
|
||||
var scrollableDiv = document.getElementById("chat-info-panel");
|
||||
infor_panel_scroll_pos = scrollableDiv.scrollTop;
|
||||
|
||||
var modal = document.getElementById("pdf-modal")
|
||||
modal.style.display = "block";
|
||||
var info_panel = document.getElementById("html-info-panel");
|
||||
if (info_panel) {
|
||||
info_panel.style.display = "none";
|
||||
}
|
||||
scrollableDiv.scrollTop = 0;
|
||||
}
|
||||
|
||||
globalThis.assignPdfOnclickEvent = () => {
|
||||
// Get all links and attach click event
|
||||
var links = document.getElementsByClassName("pdf-link");
|
||||
for (var i = 0; i < links.length; i++) {
|
||||
links[i].onclick = openModal;
|
||||
}
|
||||
}
|
||||
|
||||
var created_modal = document.getElementById("pdf-viewer");
|
||||
if (!created_modal) {
|
||||
createModal();
|
||||
console.log("Created modal")
|
||||
}
|
||||
|
||||
}
|
||||
|
|
@ -8,3 +8,6 @@ An open-source tool for you to chat with your documents.
|
|||
[User Guide](https://cinnamon.github.io/kotaemon/) |
|
||||
[Developer Guide](https://cinnamon.github.io/kotaemon/development/) |
|
||||
[Feedback](https://github.com/Cinnamon/kotaemon/issues)
|
||||
|
||||
[Dark Mode](?__theme=dark)
|
||||
[Night Mode](?__theme=light)
|
||||
|
|
|
|||
|
|
@ -136,6 +136,6 @@ Now navigate back to the `Chat` tab. The chat tab is divided into 3 regions:
|
|||
files will be considered during chat.
|
||||
2. Chat Panel
|
||||
- This is where you can chat with the chatbot.
|
||||
3. Information panel
|
||||
3. Information Panel
|
||||
- Supporting information such as the retrieved evidence and reference will be
|
||||
displayed here.
|
||||
|
|
|
|||
|
|
@ -1,9 +1,11 @@
|
|||
import datetime
|
||||
import uuid
|
||||
from typing import Optional
|
||||
from zoneinfo import ZoneInfo
|
||||
|
||||
from sqlalchemy import JSON, Column
|
||||
from sqlmodel import Field, SQLModel
|
||||
from theflow.settings import settings as flowsettings
|
||||
|
||||
|
||||
class BaseConversation(SQLModel):
|
||||
|
|
@ -24,10 +26,14 @@ class BaseConversation(SQLModel):
|
|||
default_factory=lambda: uuid.uuid4().hex, primary_key=True, index=True
|
||||
)
|
||||
name: str = Field(
|
||||
default_factory=lambda: datetime.datetime.utcnow().strftime("%Y-%m-%d %H:%M:%S")
|
||||
default_factory=lambda: datetime.datetime.now(
|
||||
ZoneInfo(getattr(flowsettings, "TIME_ZONE", "UTC"))
|
||||
).strftime("%Y-%m-%d %H:%M:%S")
|
||||
)
|
||||
user: int = Field(default=0) # For now we only have one user
|
||||
|
||||
is_public: bool = Field(default=False)
|
||||
|
||||
# contains messages + current files
|
||||
data_source: dict = Field(default={}, sa_column=Column(JSON))
|
||||
|
||||
|
|
|
|||
|
|
@ -36,7 +36,7 @@ class EmbeddingManager:
|
|||
|
||||
def load(self):
|
||||
"""Load the model pool from database"""
|
||||
self._models, self._info, self._defaut = {}, {}, ""
|
||||
self._models, self._info, self._default = {}, {}, ""
|
||||
with Session(engine) as sess:
|
||||
stmt = select(EmbeddingTable)
|
||||
items = sess.execute(stmt)
|
||||
|
|
|
|||
|
|
@ -115,7 +115,7 @@ class EmbeddingManagement(BasePage):
|
|||
"""Called when the app is created"""
|
||||
self._app.app.load(
|
||||
self.list_embeddings,
|
||||
inputs=None,
|
||||
inputs=[],
|
||||
outputs=[self.emb_list],
|
||||
)
|
||||
self._app.app.load(
|
||||
|
|
@ -144,7 +144,7 @@ class EmbeddingManagement(BasePage):
|
|||
self.create_emb,
|
||||
inputs=[self.name, self.emb_choices, self.spec, self.default],
|
||||
outputs=None,
|
||||
).success(self.list_embeddings, inputs=None, outputs=[self.emb_list]).success(
|
||||
).success(self.list_embeddings, inputs=[], outputs=[self.emb_list]).success(
|
||||
lambda: ("", None, "", False, self.spec_desc_default),
|
||||
outputs=[
|
||||
self.name,
|
||||
|
|
@ -179,7 +179,7 @@ class EmbeddingManagement(BasePage):
|
|||
)
|
||||
self.btn_delete.click(
|
||||
self.on_btn_delete_click,
|
||||
inputs=None,
|
||||
inputs=[],
|
||||
outputs=[self.btn_delete, self.btn_delete_yes, self.btn_delete_no],
|
||||
show_progress="hidden",
|
||||
)
|
||||
|
|
@ -190,7 +190,7 @@ class EmbeddingManagement(BasePage):
|
|||
show_progress="hidden",
|
||||
).then(
|
||||
self.list_embeddings,
|
||||
inputs=None,
|
||||
inputs=[],
|
||||
outputs=[self.emb_list],
|
||||
)
|
||||
self.btn_delete_no.click(
|
||||
|
|
@ -199,7 +199,7 @@ class EmbeddingManagement(BasePage):
|
|||
gr.update(visible=False),
|
||||
gr.update(visible=False),
|
||||
),
|
||||
inputs=None,
|
||||
inputs=[],
|
||||
outputs=[self.btn_delete, self.btn_delete_yes, self.btn_delete_no],
|
||||
show_progress="hidden",
|
||||
)
|
||||
|
|
@ -213,7 +213,7 @@ class EmbeddingManagement(BasePage):
|
|||
show_progress="hidden",
|
||||
).then(
|
||||
self.list_embeddings,
|
||||
inputs=None,
|
||||
inputs=[],
|
||||
outputs=[self.emb_list],
|
||||
)
|
||||
self.btn_close.click(
|
||||
|
|
|
|||
|
|
@ -54,6 +54,7 @@ class BaseFileIndexIndexing(BaseComponent):
|
|||
DS = Param(help="The DocStore")
|
||||
FSPath = Param(help="The file storage path")
|
||||
user_id = Param(help="The user id")
|
||||
private = Param(False, help="Whether this is private index")
|
||||
|
||||
def run(
|
||||
self, file_paths: str | Path | list[str | Path], *args, **kwargs
|
||||
|
|
@ -73,7 +74,9 @@ class BaseFileIndexIndexing(BaseComponent):
|
|||
|
||||
def stream(
|
||||
self, file_paths: str | Path | list[str | Path], *args, **kwargs
|
||||
) -> Generator[Document, None, tuple[list[str | None], list[str | None]]]:
|
||||
) -> Generator[
|
||||
Document, None, tuple[list[str | None], list[str | None], list[Document]]
|
||||
]:
|
||||
"""Stream the indexing pipeline
|
||||
|
||||
Args:
|
||||
|
|
@ -87,6 +90,7 @@ class BaseFileIndexIndexing(BaseComponent):
|
|||
None if the indexing failed for that file path)
|
||||
- the error messages (each error message corresponds to an input file path,
|
||||
or None if the indexing was successful for that file path)
|
||||
- the indexed documents in form of list[Documents]
|
||||
"""
|
||||
raise NotImplementedError
|
||||
|
||||
|
|
@ -149,3 +153,7 @@ class BaseFileIndexIndexing(BaseComponent):
|
|||
msg: the message to log
|
||||
"""
|
||||
print(msg)
|
||||
|
||||
def rebuild_index(self):
|
||||
"""Rebuild the index"""
|
||||
raise NotImplementedError
|
||||
|
|
|
|||
3
libs/ktem/ktem/index/file/graph/__init__.py
Normal file
|
|
@ -0,0 +1,3 @@
|
|||
from .graph_index import GraphRAGIndex
|
||||
|
||||
__all__ = ["GraphRAGIndex"]
|
||||
36
libs/ktem/ktem/index/file/graph/graph_index.py
Normal file
|
|
@ -0,0 +1,36 @@
|
|||
from typing import Any
|
||||
|
||||
from ktem.index.file import FileIndex
|
||||
|
||||
from ..base import BaseFileIndexIndexing, BaseFileIndexRetriever
|
||||
from .pipelines import GraphRAGIndexingPipeline, GraphRAGRetrieverPipeline
|
||||
|
||||
|
||||
class GraphRAGIndex(FileIndex):
|
||||
def _setup_indexing_cls(self):
|
||||
self._indexing_pipeline_cls = GraphRAGIndexingPipeline
|
||||
|
||||
def _setup_retriever_cls(self):
|
||||
self._retriever_pipeline_cls = [GraphRAGRetrieverPipeline]
|
||||
|
||||
def get_indexing_pipeline(self, settings, user_id) -> BaseFileIndexIndexing:
|
||||
"""Define the interface of the indexing pipeline"""
|
||||
|
||||
obj = super().get_indexing_pipeline(settings, user_id)
|
||||
# disable vectorstore for this kind of Index
|
||||
obj.VS = None
|
||||
|
||||
return obj
|
||||
|
||||
def get_retriever_pipelines(
|
||||
self, settings: dict, user_id: int, selected: Any = None
|
||||
) -> list["BaseFileIndexRetriever"]:
|
||||
_, file_ids, _ = selected
|
||||
retrievers = [
|
||||
GraphRAGRetrieverPipeline(
|
||||
file_ids=file_ids,
|
||||
Index=self._resources["Index"],
|
||||
)
|
||||
]
|
||||
|
||||
return retrievers
|
||||
359
libs/ktem/ktem/index/file/graph/pipelines.py
Normal file
|
|
@ -0,0 +1,359 @@
|
|||
import os
|
||||
import subprocess
|
||||
from pathlib import Path
|
||||
from shutil import rmtree
|
||||
from typing import Generator
|
||||
from uuid import uuid4
|
||||
|
||||
import pandas as pd
|
||||
import tiktoken
|
||||
from ktem.db.models import engine
|
||||
from sqlalchemy.orm import Session
|
||||
from theflow.settings import settings
|
||||
|
||||
from kotaemon.base import Document, Param, RetrievedDocument
|
||||
|
||||
from ..pipelines import BaseFileIndexRetriever, IndexDocumentPipeline, IndexPipeline
|
||||
from .visualize import create_knowledge_graph, visualize_graph
|
||||
|
||||
try:
|
||||
from graphrag.query.context_builder.entity_extraction import EntityVectorStoreKey
|
||||
from graphrag.query.indexer_adapters import (
|
||||
read_indexer_entities,
|
||||
read_indexer_relationships,
|
||||
read_indexer_reports,
|
||||
read_indexer_text_units,
|
||||
)
|
||||
from graphrag.query.input.loaders.dfs import store_entity_semantic_embeddings
|
||||
from graphrag.query.llm.oai.embedding import OpenAIEmbedding
|
||||
from graphrag.query.llm.oai.typing import OpenaiApiType
|
||||
from graphrag.query.structured_search.local_search.mixed_context import (
|
||||
LocalSearchMixedContext,
|
||||
)
|
||||
from graphrag.vector_stores.lancedb import LanceDBVectorStore
|
||||
except ImportError:
|
||||
print(
|
||||
(
|
||||
"GraphRAG dependencies not installed. "
|
||||
"GraphRAG retriever pipeline will not work properly."
|
||||
)
|
||||
)
|
||||
|
||||
|
||||
filestorage_path = Path(settings.KH_FILESTORAGE_PATH) / "graphrag"
|
||||
filestorage_path.mkdir(parents=True, exist_ok=True)
|
||||
|
||||
|
||||
def prepare_graph_index_path(graph_id: str):
|
||||
root_path = Path(filestorage_path) / graph_id
|
||||
input_path = root_path / "input"
|
||||
|
||||
return root_path, input_path
|
||||
|
||||
|
||||
class GraphRAGIndexingPipeline(IndexDocumentPipeline):
|
||||
"""GraphRAG specific indexing pipeline"""
|
||||
|
||||
def route(self, file_path: Path) -> IndexPipeline:
|
||||
"""Simply disable the splitter (chunking) for this pipeline"""
|
||||
pipeline = super().route(file_path)
|
||||
pipeline.splitter = None
|
||||
|
||||
return pipeline
|
||||
|
||||
def store_file_id_with_graph_id(self, file_ids: list[str | None]):
|
||||
# create new graph_id and assign them to doc_id in self.Index
|
||||
# record in the index
|
||||
graph_id = str(uuid4())
|
||||
with Session(engine) as session:
|
||||
nodes = []
|
||||
for file_id in file_ids:
|
||||
if not file_id:
|
||||
continue
|
||||
nodes.append(
|
||||
self.Index(
|
||||
source_id=file_id,
|
||||
target_id=graph_id,
|
||||
relation_type="graph",
|
||||
)
|
||||
)
|
||||
|
||||
session.add_all(nodes)
|
||||
session.commit()
|
||||
|
||||
return graph_id
|
||||
|
||||
def write_docs_to_files(self, graph_id: str, docs: list[Document]):
|
||||
root_path, input_path = prepare_graph_index_path(graph_id)
|
||||
input_path.mkdir(parents=True, exist_ok=True)
|
||||
|
||||
for doc in docs:
|
||||
if doc.metadata.get("type", "text") == "text":
|
||||
with open(input_path / f"{doc.doc_id}.txt", "w") as f:
|
||||
f.write(doc.text)
|
||||
|
||||
return root_path
|
||||
|
||||
def call_graphrag_index(self, input_path: str):
|
||||
# Construct the command
|
||||
command = [
|
||||
"python",
|
||||
"-m",
|
||||
"graphrag.index",
|
||||
"--root",
|
||||
input_path,
|
||||
"--reporter",
|
||||
"rich",
|
||||
"--init",
|
||||
]
|
||||
|
||||
# Run the command
|
||||
yield Document(
|
||||
channel="debug",
|
||||
text="[GraphRAG] Creating index... This can take a long time.",
|
||||
)
|
||||
result = subprocess.run(command, capture_output=True, text=True)
|
||||
print(result.stdout)
|
||||
command = command[:-1]
|
||||
|
||||
# Run the command and stream stdout
|
||||
with subprocess.Popen(command, stdout=subprocess.PIPE, text=True) as process:
|
||||
if process.stdout:
|
||||
for line in process.stdout:
|
||||
yield Document(channel="debug", text=line)
|
||||
|
||||
def stream(
|
||||
self, file_paths: str | Path | list[str | Path], reindex: bool = False, **kwargs
|
||||
) -> Generator[
|
||||
Document, None, tuple[list[str | None], list[str | None], list[Document]]
|
||||
]:
|
||||
file_ids, errors, all_docs = yield from super().stream(
|
||||
file_paths, reindex=reindex, **kwargs
|
||||
)
|
||||
|
||||
# assign graph_id to file_ids
|
||||
graph_id = self.store_file_id_with_graph_id(file_ids)
|
||||
# call GraphRAG index with docs and graph_id
|
||||
graph_index_path = self.write_docs_to_files(graph_id, all_docs)
|
||||
yield from self.call_graphrag_index(graph_index_path)
|
||||
|
||||
return file_ids, errors, all_docs
|
||||
|
||||
|
||||
class GraphRAGRetrieverPipeline(BaseFileIndexRetriever):
|
||||
"""GraphRAG specific retriever pipeline"""
|
||||
|
||||
Index = Param(help="The SQLAlchemy Index table")
|
||||
file_ids: list[str] = []
|
||||
|
||||
@classmethod
|
||||
def get_user_settings(cls) -> dict:
|
||||
return {
|
||||
"search_type": {
|
||||
"name": "Search type",
|
||||
"value": "local",
|
||||
"choices": ["local", "global"],
|
||||
"component": "dropdown",
|
||||
"info": "Whether to use local or global search in the graph.",
|
||||
}
|
||||
}
|
||||
|
||||
def _build_graph_search(self):
|
||||
assert (
|
||||
len(self.file_ids) <= 1
|
||||
), "GraphRAG retriever only supports one file_id at a time"
|
||||
|
||||
file_id = self.file_ids[0]
|
||||
# retrieve the graph_id from the index
|
||||
with Session(engine) as session:
|
||||
graph_id = (
|
||||
session.query(self.Index.target_id)
|
||||
.filter(self.Index.source_id == file_id)
|
||||
.filter(self.Index.relation_type == "graph")
|
||||
.first()
|
||||
)
|
||||
graph_id = graph_id[0] if graph_id else None
|
||||
assert graph_id, f"GraphRAG index not found for file_id: {file_id}"
|
||||
|
||||
root_path, _ = prepare_graph_index_path(graph_id)
|
||||
output_path = root_path / "output"
|
||||
child_paths = sorted(
|
||||
list(output_path.iterdir()), key=lambda x: x.stem, reverse=True
|
||||
)
|
||||
|
||||
# get the latest child path
|
||||
assert child_paths, "GraphRAG index output not found"
|
||||
latest_child_path = Path(child_paths[0]) / "artifacts"
|
||||
|
||||
INPUT_DIR = latest_child_path
|
||||
LANCEDB_URI = str(INPUT_DIR / "lancedb")
|
||||
COMMUNITY_REPORT_TABLE = "create_final_community_reports"
|
||||
ENTITY_TABLE = "create_final_nodes"
|
||||
ENTITY_EMBEDDING_TABLE = "create_final_entities"
|
||||
RELATIONSHIP_TABLE = "create_final_relationships"
|
||||
TEXT_UNIT_TABLE = "create_final_text_units"
|
||||
COMMUNITY_LEVEL = 2
|
||||
|
||||
# read nodes table to get community and degree data
|
||||
entity_df = pd.read_parquet(f"{INPUT_DIR}/{ENTITY_TABLE}.parquet")
|
||||
entity_embedding_df = pd.read_parquet(
|
||||
f"{INPUT_DIR}/{ENTITY_EMBEDDING_TABLE}.parquet"
|
||||
)
|
||||
entities = read_indexer_entities(
|
||||
entity_df, entity_embedding_df, COMMUNITY_LEVEL
|
||||
)
|
||||
|
||||
# load description embeddings to an in-memory lancedb vectorstore
|
||||
# to connect to a remote db, specify url and port values.
|
||||
description_embedding_store = LanceDBVectorStore(
|
||||
collection_name="entity_description_embeddings",
|
||||
)
|
||||
description_embedding_store.connect(db_uri=LANCEDB_URI)
|
||||
if Path(LANCEDB_URI).is_dir():
|
||||
rmtree(LANCEDB_URI)
|
||||
_ = store_entity_semantic_embeddings(
|
||||
entities=entities, vectorstore=description_embedding_store
|
||||
)
|
||||
print(f"Entity count: {len(entity_df)}")
|
||||
|
||||
# Read relationships
|
||||
relationship_df = pd.read_parquet(f"{INPUT_DIR}/{RELATIONSHIP_TABLE}.parquet")
|
||||
relationships = read_indexer_relationships(relationship_df)
|
||||
|
||||
# Read community reports
|
||||
report_df = pd.read_parquet(f"{INPUT_DIR}/{COMMUNITY_REPORT_TABLE}.parquet")
|
||||
reports = read_indexer_reports(report_df, entity_df, COMMUNITY_LEVEL)
|
||||
|
||||
# Read text units
|
||||
text_unit_df = pd.read_parquet(f"{INPUT_DIR}/{TEXT_UNIT_TABLE}.parquet")
|
||||
text_units = read_indexer_text_units(text_unit_df)
|
||||
|
||||
embedding_model = os.getenv("GRAPHRAG_EMBEDDING_MODEL")
|
||||
text_embedder = OpenAIEmbedding(
|
||||
api_key=os.getenv("OPENAI_API_KEY"),
|
||||
api_base=None,
|
||||
api_type=OpenaiApiType.OpenAI,
|
||||
model=embedding_model,
|
||||
deployment_name=embedding_model,
|
||||
max_retries=20,
|
||||
)
|
||||
token_encoder = tiktoken.get_encoding("cl100k_base")
|
||||
|
||||
context_builder = LocalSearchMixedContext(
|
||||
community_reports=reports,
|
||||
text_units=text_units,
|
||||
entities=entities,
|
||||
relationships=relationships,
|
||||
covariates=None,
|
||||
entity_text_embeddings=description_embedding_store,
|
||||
embedding_vectorstore_key=EntityVectorStoreKey.ID,
|
||||
# if the vectorstore uses entity title as ids,
|
||||
# set this to EntityVectorStoreKey.TITLE
|
||||
text_embedder=text_embedder,
|
||||
token_encoder=token_encoder,
|
||||
)
|
||||
return context_builder
|
||||
|
||||
def _to_document(self, header: str, context_text: str) -> RetrievedDocument:
|
||||
return RetrievedDocument(
|
||||
text=context_text,
|
||||
metadata={
|
||||
"file_name": header,
|
||||
"type": "table",
|
||||
"llm_trulens_score": 1.0,
|
||||
},
|
||||
score=1.0,
|
||||
)
|
||||
|
||||
def format_context_records(self, context_records) -> list[RetrievedDocument]:
|
||||
entities = context_records.get("entities", [])
|
||||
relationships = context_records.get("relationships", [])
|
||||
reports = context_records.get("reports", [])
|
||||
sources = context_records.get("sources", [])
|
||||
|
||||
docs = []
|
||||
|
||||
context: str = ""
|
||||
|
||||
header = "<b>Entities</b>\n"
|
||||
context = entities[["entity", "description"]].to_markdown(index=False)
|
||||
docs.append(self._to_document(header, context))
|
||||
|
||||
header = "\n<b>Relationships</b>\n"
|
||||
context = relationships[["source", "target", "description"]].to_markdown(
|
||||
index=False
|
||||
)
|
||||
docs.append(self._to_document(header, context))
|
||||
|
||||
header = "\n<b>Reports</b>\n"
|
||||
context = ""
|
||||
for idx, row in reports.iterrows():
|
||||
title, content = row["title"], row["content"]
|
||||
context += f"\n\n<h5>Report <b>{title}</b></h5>\n"
|
||||
context += content
|
||||
docs.append(self._to_document(header, context))
|
||||
|
||||
header = "\n<b>Sources</b>\n"
|
||||
context = ""
|
||||
for idx, row in sources.iterrows():
|
||||
title, content = row["id"], row["text"]
|
||||
context += f"\n\n<h5>Source <b>#{title}</b></h5>\n"
|
||||
context += content
|
||||
docs.append(self._to_document(header, context))
|
||||
|
||||
return docs
|
||||
|
||||
def plot_graph(self, context_records):
|
||||
relationships = context_records.get("relationships", [])
|
||||
G = create_knowledge_graph(relationships)
|
||||
plot = visualize_graph(G)
|
||||
return plot
|
||||
|
||||
def generate_relevant_scores(self, text, documents: list[RetrievedDocument]):
|
||||
return documents
|
||||
|
||||
def run(
|
||||
self,
|
||||
text: str,
|
||||
) -> list[RetrievedDocument]:
|
||||
if not self.file_ids:
|
||||
return []
|
||||
context_builder = self._build_graph_search()
|
||||
|
||||
local_context_params = {
|
||||
"text_unit_prop": 0.5,
|
||||
"community_prop": 0.1,
|
||||
"conversation_history_max_turns": 5,
|
||||
"conversation_history_user_turns_only": True,
|
||||
"top_k_mapped_entities": 10,
|
||||
"top_k_relationships": 10,
|
||||
"include_entity_rank": False,
|
||||
"include_relationship_weight": False,
|
||||
"include_community_rank": False,
|
||||
"return_candidate_context": False,
|
||||
"embedding_vectorstore_key": EntityVectorStoreKey.ID,
|
||||
# set this to EntityVectorStoreKey.TITLE i
|
||||
# f the vectorstore uses entity title as ids
|
||||
"max_tokens": 12_000,
|
||||
# change this based on the token limit you have on your model
|
||||
# (if you are using a model with 8k limit, a good setting could be 5000)
|
||||
}
|
||||
|
||||
context_text, context_records = context_builder.build_context(
|
||||
query=text,
|
||||
conversation_history=None,
|
||||
**local_context_params,
|
||||
)
|
||||
documents = self.format_context_records(context_records)
|
||||
plot = self.plot_graph(context_records)
|
||||
|
||||
return documents + [
|
||||
RetrievedDocument(
|
||||
text="",
|
||||
metadata={
|
||||
"file_name": "GraphRAG",
|
||||
"type": "plot",
|
||||
"data": plot,
|
||||
},
|
||||
),
|
||||
]
|
||||
102
libs/ktem/ktem/index/file/graph/visualize.py
Normal file
|
|
@ -0,0 +1,102 @@
|
|||
import networkx as nx
|
||||
import plotly.graph_objects as go
|
||||
from plotly.io import to_json
|
||||
|
||||
|
||||
def create_knowledge_graph(df):
|
||||
"""
|
||||
create nx Graph from DataFrame relations data
|
||||
"""
|
||||
G = nx.Graph()
|
||||
for _, row in df.iterrows():
|
||||
source = row["source"]
|
||||
target = row["target"]
|
||||
attributes = {k: v for k, v in row.items() if k not in ["source", "target"]}
|
||||
G.add_edge(source, target, **attributes)
|
||||
|
||||
return G
|
||||
|
||||
|
||||
def visualize_graph(G):
|
||||
pos = nx.spring_layout(G, dim=2)
|
||||
|
||||
edge_x = []
|
||||
edge_y = []
|
||||
edge_texts = nx.get_edge_attributes(G, "description")
|
||||
to_display_edge_texts = []
|
||||
for edge in G.edges():
|
||||
x0, y0 = pos[edge[0]]
|
||||
x1, y1 = pos[edge[1]]
|
||||
edge_x.append(x0)
|
||||
edge_x.append(x1)
|
||||
edge_x.append(None)
|
||||
edge_y.append(y0)
|
||||
edge_y.append(y1)
|
||||
edge_y.append(None)
|
||||
to_display_edge_texts.append(edge_texts[edge])
|
||||
|
||||
edge_trace = go.Scatter(
|
||||
x=edge_x,
|
||||
y=edge_y,
|
||||
text=to_display_edge_texts,
|
||||
line=dict(width=0.5, color="#888"),
|
||||
hoverinfo="text",
|
||||
mode="lines",
|
||||
)
|
||||
|
||||
node_x = []
|
||||
node_y = []
|
||||
for node in G.nodes():
|
||||
x, y = pos[node]
|
||||
node_x.append(x)
|
||||
node_y.append(y)
|
||||
|
||||
node_adjacencies = []
|
||||
node_text = []
|
||||
node_size = []
|
||||
for node_id, adjacencies in enumerate(G.adjacency()):
|
||||
degree = len(adjacencies[1])
|
||||
node_adjacencies.append(degree)
|
||||
node_text.append(adjacencies[0])
|
||||
node_size.append(15 if degree < 5 else (30 if degree < 10 else 60))
|
||||
|
||||
node_trace = go.Scatter(
|
||||
x=node_x,
|
||||
y=node_y,
|
||||
textfont=dict(
|
||||
family="Courier New, monospace",
|
||||
size=10, # Set the font size here
|
||||
),
|
||||
textposition="top center",
|
||||
mode="markers+text",
|
||||
hoverinfo="text",
|
||||
text=node_text,
|
||||
marker=dict(
|
||||
showscale=True,
|
||||
# colorscale options
|
||||
size=node_size,
|
||||
colorscale="YlGnBu",
|
||||
reversescale=True,
|
||||
color=node_adjacencies,
|
||||
colorbar=dict(
|
||||
thickness=5,
|
||||
xanchor="left",
|
||||
titleside="right",
|
||||
),
|
||||
line_width=2,
|
||||
),
|
||||
)
|
||||
|
||||
fig = go.Figure(
|
||||
data=[edge_trace, node_trace],
|
||||
layout=go.Layout(
|
||||
showlegend=False,
|
||||
hovermode="closest",
|
||||
margin=dict(b=20, l=5, r=5, t=40),
|
||||
xaxis=dict(showgrid=False, zeroline=False, showticklabels=False),
|
||||
yaxis=dict(showgrid=False, zeroline=False, showticklabels=False),
|
||||
),
|
||||
)
|
||||
fig.update_layout(autosize=True)
|
||||
|
||||
return to_json(fig)
|
||||
|
|
@ -4,8 +4,9 @@ from typing import Any, Optional, Type
|
|||
from ktem.components import filestorage_path, get_docstore, get_vectorstore
|
||||
from ktem.db.engine import engine
|
||||
from ktem.index.base import BaseIndex
|
||||
from sqlalchemy import Column, DateTime, Integer, String
|
||||
from sqlalchemy import JSON, Column, DateTime, Integer, String, UniqueConstraint
|
||||
from sqlalchemy.ext.declarative import declarative_base
|
||||
from sqlalchemy.ext.mutable import MutableDict
|
||||
from sqlalchemy.sql import func
|
||||
from theflow.settings import settings as flowsettings
|
||||
from theflow.utils.modules import import_dotted_string
|
||||
|
|
@ -52,6 +53,36 @@ class FileIndex(BaseIndex):
|
|||
- File storage path
|
||||
"""
|
||||
Base = declarative_base()
|
||||
|
||||
if self.config.get("private", False):
|
||||
Source = type(
|
||||
"Source",
|
||||
(Base,),
|
||||
{
|
||||
"__tablename__": f"index__{self.id}__source",
|
||||
"__table_args__": (
|
||||
UniqueConstraint("name", "user", name="_name_user_uc"),
|
||||
),
|
||||
"id": Column(
|
||||
String,
|
||||
primary_key=True,
|
||||
default=lambda: str(uuid.uuid4()),
|
||||
unique=True,
|
||||
),
|
||||
"name": Column(String),
|
||||
"path": Column(String),
|
||||
"size": Column(Integer, default=0),
|
||||
"date_created": Column(
|
||||
DateTime(timezone=True), server_default=func.now()
|
||||
),
|
||||
"user": Column(Integer, default=1),
|
||||
"note": Column(
|
||||
MutableDict.as_mutable(JSON), # type: ignore
|
||||
default={},
|
||||
),
|
||||
},
|
||||
)
|
||||
else:
|
||||
Source = type(
|
||||
"Source",
|
||||
(Base,),
|
||||
|
|
@ -66,11 +97,14 @@ class FileIndex(BaseIndex):
|
|||
"name": Column(String, unique=True),
|
||||
"path": Column(String),
|
||||
"size": Column(Integer, default=0),
|
||||
"text_length": Column(Integer, default=0),
|
||||
"date_created": Column(
|
||||
DateTime(timezone=True), server_default=func.now()
|
||||
),
|
||||
"user": Column(Integer, default=1),
|
||||
"note": Column(
|
||||
MutableDict.as_mutable(JSON), # type: ignore
|
||||
default={},
|
||||
),
|
||||
},
|
||||
)
|
||||
Index = type(
|
||||
|
|
@ -85,6 +119,7 @@ class FileIndex(BaseIndex):
|
|||
"user": Column(Integer, default=1),
|
||||
},
|
||||
)
|
||||
|
||||
self._vs: BaseVectorStore = get_vectorstore(f"index_{self.id}")
|
||||
self._docstore: BaseDocumentStore = get_docstore(f"index_{self.id}")
|
||||
self._fs_path = filestorage_path / f"index_{self.id}"
|
||||
|
|
@ -358,8 +393,6 @@ class FileIndex(BaseIndex):
|
|||
for key, value in settings.items():
|
||||
if key.startswith(prefix):
|
||||
stripped_settings[key[len(prefix) :]] = value
|
||||
else:
|
||||
stripped_settings[key] = value
|
||||
|
||||
obj = self._indexing_pipeline_cls.get_pipeline(stripped_settings, self.config)
|
||||
obj.Source = self._resources["Source"]
|
||||
|
|
@ -368,6 +401,7 @@ class FileIndex(BaseIndex):
|
|||
obj.DS = self._docstore
|
||||
obj.FSPath = self._fs_path
|
||||
obj.user_id = user_id
|
||||
obj.private = self.config.get("private", False)
|
||||
|
||||
return obj
|
||||
|
||||
|
|
@ -380,8 +414,6 @@ class FileIndex(BaseIndex):
|
|||
for key, value in settings.items():
|
||||
if key.startswith(prefix):
|
||||
stripped_settings[key[len(prefix) :]] = value
|
||||
else:
|
||||
stripped_settings[key] = value
|
||||
|
||||
# transform selected id
|
||||
selected_ids: Optional[list[str]] = self._selector_ui.get_selected_ids(selected)
|
||||
|
|
|
|||
3
libs/ktem/ktem/index/file/knet/__init__.py
Normal file
|
|
@ -0,0 +1,3 @@
|
|||
from .knet_index import KnowledgeNetworkFileIndex
|
||||
|
||||
__all__ = ["KnowledgeNetworkFileIndex"]
|
||||
47
libs/ktem/ktem/index/file/knet/knet_index.py
Normal file
|
|
@ -0,0 +1,47 @@
|
|||
from typing import Any
|
||||
|
||||
from ktem.index.file import FileIndex
|
||||
|
||||
from ..base import BaseFileIndexIndexing, BaseFileIndexRetriever
|
||||
from .pipelines import KnetIndexingPipeline, KnetRetrievalPipeline
|
||||
|
||||
|
||||
class KnowledgeNetworkFileIndex(FileIndex):
|
||||
@classmethod
|
||||
def get_admin_settings(cls):
|
||||
admin_settings = super().get_admin_settings()
|
||||
|
||||
# remove embedding from admin settings
|
||||
# as we don't need it
|
||||
admin_settings.pop("embedding")
|
||||
return admin_settings
|
||||
|
||||
def _setup_indexing_cls(self):
|
||||
self._indexing_pipeline_cls = KnetIndexingPipeline
|
||||
|
||||
def _setup_retriever_cls(self):
|
||||
self._retriever_pipeline_cls = [KnetRetrievalPipeline]
|
||||
|
||||
def get_indexing_pipeline(self, settings, user_id) -> BaseFileIndexIndexing:
|
||||
"""Define the interface of the indexing pipeline"""
|
||||
|
||||
obj = super().get_indexing_pipeline(settings, user_id)
|
||||
# disable vectorstore for this kind of Index
|
||||
# also set the collection_name for API call
|
||||
obj.VS = None
|
||||
obj.collection_name = f"kh_index_{self.id}"
|
||||
|
||||
return obj
|
||||
|
||||
def get_retriever_pipelines(
|
||||
self, settings: dict, user_id: int, selected: Any = None
|
||||
) -> list["BaseFileIndexRetriever"]:
|
||||
retrievers = super().get_retriever_pipelines(settings, user_id, selected)
|
||||
|
||||
for obj in retrievers:
|
||||
# disable vectorstore for this kind of Index
|
||||
# also set the collection_name for API call
|
||||
obj.VS = None
|
||||
obj.collection_name = f"kh_index_{self.id}"
|
||||
|
||||
return retrievers
|
||||
169
libs/ktem/ktem/index/file/knet/pipelines.py
Normal file
|
|
@ -0,0 +1,169 @@
|
|||
import base64
|
||||
import json
|
||||
import os
|
||||
from pathlib import Path
|
||||
from typing import Optional, Sequence
|
||||
|
||||
import requests
|
||||
import yaml
|
||||
|
||||
from kotaemon.base import RetrievedDocument
|
||||
from kotaemon.indices.rankings import BaseReranking, LLMReranking, LLMTrulensScoring
|
||||
|
||||
from ..pipelines import BaseFileIndexRetriever, IndexDocumentPipeline, IndexPipeline
|
||||
|
||||
|
||||
class KnetIndexingPipeline(IndexDocumentPipeline):
|
||||
"""Knowledge Network specific indexing pipeline"""
|
||||
|
||||
# collection name for external indexing call
|
||||
collection_name: str = "default"
|
||||
|
||||
@classmethod
|
||||
def get_user_settings(cls):
|
||||
return {
|
||||
"reader_mode": {
|
||||
"name": "Index parser",
|
||||
"value": "knowledge_network",
|
||||
"choices": [
|
||||
("Default (KN)", "knowledge_network"),
|
||||
],
|
||||
"component": "dropdown",
|
||||
},
|
||||
}
|
||||
|
||||
def route(self, file_path: Path) -> IndexPipeline:
|
||||
"""Simply disable the splitter (chunking) for this pipeline"""
|
||||
pipeline = super().route(file_path)
|
||||
pipeline.splitter = None
|
||||
# assign IndexPipeline collection name to parse to loader
|
||||
pipeline.collection_name = self.collection_name
|
||||
|
||||
return pipeline
|
||||
|
||||
|
||||
class KnetRetrievalPipeline(BaseFileIndexRetriever):
|
||||
DEFAULT_KNET_ENDPOINT: str = "http://127.0.0.1:8081/retrieve"
|
||||
|
||||
collection_name: str = "default"
|
||||
rerankers: Sequence[BaseReranking] = [LLMReranking.withx()]
|
||||
|
||||
def encode_image_base64(self, image_path: str | Path) -> bytes | str:
|
||||
"""Convert image to base64"""
|
||||
img_base64 = "data:image/png;base64,{}"
|
||||
with open(image_path, "rb") as image_file:
|
||||
return img_base64.format(
|
||||
base64.b64encode(image_file.read()).decode("utf-8")
|
||||
)
|
||||
|
||||
def run(
|
||||
self,
|
||||
text: str,
|
||||
doc_ids: Optional[list[str]] = None,
|
||||
*args,
|
||||
**kwargs,
|
||||
) -> list[RetrievedDocument]:
|
||||
"""Retrieve document excerpts similar to the text
|
||||
|
||||
Args:
|
||||
text: the text to retrieve similar documents
|
||||
doc_ids: list of document ids to constraint the retrieval
|
||||
"""
|
||||
print("searching in doc_ids", doc_ids)
|
||||
if not doc_ids:
|
||||
return []
|
||||
|
||||
docs: list[RetrievedDocument] = []
|
||||
params = {
|
||||
"query": text,
|
||||
"collection": self.collection_name,
|
||||
"meta_filters": {"doc_name": doc_ids},
|
||||
}
|
||||
params["meta_filters"] = json.dumps(params["meta_filters"])
|
||||
response = requests.get(self.DEFAULT_KNET_ENDPOINT, params=params)
|
||||
metadata_translation = {
|
||||
"TABLE": "table",
|
||||
"FIGURE": "image",
|
||||
}
|
||||
|
||||
if response.status_code == 200:
|
||||
# Load YAML content from the response content
|
||||
chunks = yaml.safe_load(response.content)
|
||||
for chunk in chunks:
|
||||
metadata = chunk["node"]["metadata"]
|
||||
metadata["type"] = metadata_translation.get(
|
||||
metadata.pop("content_type", ""), ""
|
||||
)
|
||||
metadata["file_name"] = metadata.pop("company_name", "")
|
||||
|
||||
# load image from returned path
|
||||
image_path = metadata.get("image_path", "")
|
||||
if image_path and os.path.isfile(image_path):
|
||||
base64_im = self.encode_image_base64(image_path)
|
||||
# explicitly set document type
|
||||
metadata["type"] = "image"
|
||||
metadata["image_origin"] = base64_im
|
||||
|
||||
docs.append(
|
||||
RetrievedDocument(text=chunk["node"]["text"], metadata=metadata)
|
||||
)
|
||||
else:
|
||||
raise IOError(f"{response.status_code}: {response.text}")
|
||||
|
||||
for reranker in self.rerankers:
|
||||
docs = reranker(documents=docs, query=text)
|
||||
|
||||
return docs
|
||||
|
||||
@classmethod
|
||||
def get_user_settings(cls) -> dict:
|
||||
from ktem.llms.manager import llms
|
||||
|
||||
try:
|
||||
reranking_llm = llms.get_default_name()
|
||||
reranking_llm_choices = list(llms.options().keys())
|
||||
except Exception:
|
||||
reranking_llm = None
|
||||
reranking_llm_choices = []
|
||||
|
||||
return {
|
||||
"reranking_llm": {
|
||||
"name": "LLM for scoring",
|
||||
"value": reranking_llm,
|
||||
"component": "dropdown",
|
||||
"choices": reranking_llm_choices,
|
||||
"special_type": "llm",
|
||||
},
|
||||
"retrieval_mode": {
|
||||
"name": "Retrieval mode",
|
||||
"value": "hybrid",
|
||||
"choices": ["vector", "text", "hybrid"],
|
||||
"component": "dropdown",
|
||||
},
|
||||
}
|
||||
|
||||
@classmethod
|
||||
def get_pipeline(cls, user_settings, index_settings, selected):
|
||||
"""Get retriever objects associated with the index
|
||||
|
||||
Args:
|
||||
settings: the settings of the app
|
||||
kwargs: other arguments
|
||||
"""
|
||||
from ktem.llms.manager import llms
|
||||
|
||||
retriever = cls(
|
||||
rerankers=[LLMTrulensScoring()],
|
||||
)
|
||||
|
||||
# hacky way to input doc_ids to retriever.run() call (through theflow)
|
||||
kwargs = {".doc_ids": selected}
|
||||
retriever.set_run(kwargs, temp=False)
|
||||
|
||||
for reranker in retriever.rerankers:
|
||||
if isinstance(reranker, LLMReranking):
|
||||
reranker.llm = llms.get(
|
||||
user_settings["reranking_llm"], llms.get_default()
|
||||
)
|
||||
|
||||
return retriever
|
||||
|
|
@ -2,25 +2,29 @@ from __future__ import annotations
|
|||
|
||||
import logging
|
||||
import shutil
|
||||
import threading
|
||||
import time
|
||||
import warnings
|
||||
from collections import defaultdict
|
||||
from copy import deepcopy
|
||||
from functools import lru_cache
|
||||
from hashlib import sha256
|
||||
from pathlib import Path
|
||||
from typing import Generator, Optional
|
||||
from typing import Generator, Optional, Sequence
|
||||
|
||||
import tiktoken
|
||||
from ktem.db.models import engine
|
||||
from ktem.embeddings.manager import embedding_models_manager
|
||||
from ktem.llms.manager import llms
|
||||
from llama_index.readers.base import BaseReader
|
||||
from llama_index.readers.file.base import default_file_metadata_func
|
||||
from llama_index.vector_stores import (
|
||||
from llama_index.core.readers.base import BaseReader
|
||||
from llama_index.core.readers.file.base import default_file_metadata_func
|
||||
from llama_index.core.vector_stores import (
|
||||
FilterCondition,
|
||||
FilterOperator,
|
||||
MetadataFilter,
|
||||
MetadataFilters,
|
||||
)
|
||||
from llama_index.vector_stores.types import VectorStoreQueryMode
|
||||
from llama_index.core.vector_stores.types import VectorStoreQueryMode
|
||||
from sqlalchemy import delete, select
|
||||
from sqlalchemy.orm import Session
|
||||
from theflow.settings import settings
|
||||
|
|
@ -29,8 +33,18 @@ from theflow.utils.modules import import_dotted_string
|
|||
from kotaemon.base import BaseComponent, Document, Node, Param, RetrievedDocument
|
||||
from kotaemon.embeddings import BaseEmbeddings
|
||||
from kotaemon.indices import VectorIndexing, VectorRetrieval
|
||||
from kotaemon.indices.ingests.files import KH_DEFAULT_FILE_EXTRACTORS
|
||||
from kotaemon.indices.rankings import BaseReranking, LLMReranking
|
||||
from kotaemon.indices.ingests.files import (
|
||||
KH_DEFAULT_FILE_EXTRACTORS,
|
||||
adobe_reader,
|
||||
azure_reader,
|
||||
unstructured,
|
||||
)
|
||||
from kotaemon.indices.rankings import (
|
||||
BaseReranking,
|
||||
CohereReranking,
|
||||
LLMReranking,
|
||||
LLMTrulensScoring,
|
||||
)
|
||||
from kotaemon.indices.splitters import BaseSplitter, TokenSplitter
|
||||
|
||||
from .base import BaseFileIndexIndexing, BaseFileIndexRetriever
|
||||
|
|
@ -60,6 +74,9 @@ def dev_settings():
|
|||
return file_extractors, chunk_size, chunk_overlap
|
||||
|
||||
|
||||
_default_token_func = tiktoken.encoding_for_model("gpt-3.5-turbo").encode
|
||||
|
||||
|
||||
class DocumentRetrievalPipeline(BaseFileIndexRetriever):
|
||||
"""Retrieve relevant document
|
||||
|
||||
|
|
@ -75,10 +92,13 @@ class DocumentRetrievalPipeline(BaseFileIndexRetriever):
|
|||
"""
|
||||
|
||||
embedding: BaseEmbeddings
|
||||
reranker: BaseReranking = LLMReranking.withx()
|
||||
rerankers: Sequence[BaseReranking] = []
|
||||
# use LLM to create relevant scores for displaying on UI
|
||||
llm_scorer: LLMReranking | None = LLMReranking.withx()
|
||||
get_extra_table: bool = False
|
||||
mmr: bool = False
|
||||
top_k: int = 5
|
||||
retrieval_mode: str = "hybrid"
|
||||
|
||||
@Node.auto(depends_on=["embedding", "VS", "DS"])
|
||||
def vector_retrieval(self) -> VectorRetrieval:
|
||||
|
|
@ -86,6 +106,8 @@ class DocumentRetrievalPipeline(BaseFileIndexRetriever):
|
|||
embedding=self.embedding,
|
||||
vector_store=self.VS,
|
||||
doc_store=self.DS,
|
||||
retrieval_mode=self.retrieval_mode, # type: ignore
|
||||
rerankers=self.rerankers,
|
||||
)
|
||||
|
||||
def run(
|
||||
|
|
@ -101,27 +123,30 @@ class DocumentRetrievalPipeline(BaseFileIndexRetriever):
|
|||
text: the text to retrieve similar documents
|
||||
doc_ids: list of document ids to constraint the retrieval
|
||||
"""
|
||||
print("searching in doc_ids", doc_ids)
|
||||
if not doc_ids:
|
||||
logger.info(f"Skip retrieval because of no selected files: {self}")
|
||||
return []
|
||||
|
||||
retrieval_kwargs = {}
|
||||
retrieval_kwargs: dict = {}
|
||||
with Session(engine) as session:
|
||||
stmt = select(self.Index).where(
|
||||
self.Index.relation_type == "vector",
|
||||
self.Index.relation_type == "document",
|
||||
self.Index.source_id.in_(doc_ids),
|
||||
)
|
||||
results = session.execute(stmt)
|
||||
vs_ids = [r[0].target_id for r in results.all()]
|
||||
chunk_ids = [r[0].target_id for r in results.all()]
|
||||
|
||||
# do first round top_k extension
|
||||
retrieval_kwargs["do_extend"] = True
|
||||
retrieval_kwargs["scope"] = chunk_ids
|
||||
retrieval_kwargs["filters"] = MetadataFilters(
|
||||
filters=[
|
||||
MetadataFilter(
|
||||
key="doc_id",
|
||||
value=vs_id,
|
||||
operator=FilterOperator.EQ,
|
||||
key="file_id",
|
||||
value=doc_ids,
|
||||
operator=FilterOperator.IN,
|
||||
)
|
||||
for vs_id in vs_ids
|
||||
],
|
||||
condition=FilterCondition.OR,
|
||||
)
|
||||
|
|
@ -132,9 +157,10 @@ class DocumentRetrievalPipeline(BaseFileIndexRetriever):
|
|||
retrieval_kwargs["mmr_threshold"] = 0.5
|
||||
|
||||
# rerank
|
||||
s_time = time.time()
|
||||
print(f"retrieval_kwargs: {retrieval_kwargs.keys()}")
|
||||
docs = self.vector_retrieval(text=text, top_k=self.top_k, **retrieval_kwargs)
|
||||
if docs and self.get_from_path("reranker"):
|
||||
docs = self.reranker(docs, query=text)
|
||||
print("retrieval step took", time.time() - s_time)
|
||||
|
||||
if not self.get_extra_table:
|
||||
return docs
|
||||
|
|
@ -157,6 +183,7 @@ class DocumentRetrievalPipeline(BaseFileIndexRetriever):
|
|||
for fn, pls in table_pages.items()
|
||||
]
|
||||
if queries:
|
||||
try:
|
||||
extra_docs = self.vector_retrieval(
|
||||
text="",
|
||||
top_k=50,
|
||||
|
|
@ -165,9 +192,21 @@ class DocumentRetrievalPipeline(BaseFileIndexRetriever):
|
|||
for doc in extra_docs:
|
||||
if doc.doc_id not in retrieved_id:
|
||||
docs.append(doc)
|
||||
except Exception:
|
||||
print("Error retrieving additional tables")
|
||||
|
||||
return docs
|
||||
|
||||
def generate_relevant_scores(
|
||||
self, query: str, documents: list[RetrievedDocument]
|
||||
) -> list[RetrievedDocument]:
|
||||
docs = (
|
||||
documents
|
||||
if not self.llm_scorer
|
||||
else self.llm_scorer(documents=documents, query=query)
|
||||
)
|
||||
return docs
|
||||
|
||||
@classmethod
|
||||
def get_user_settings(cls) -> dict:
|
||||
from ktem.llms.manager import llms
|
||||
|
|
@ -182,43 +221,44 @@ class DocumentRetrievalPipeline(BaseFileIndexRetriever):
|
|||
|
||||
return {
|
||||
"reranking_llm": {
|
||||
"name": "LLM for reranking",
|
||||
"name": "LLM for relevant scoring",
|
||||
"value": reranking_llm,
|
||||
"component": "dropdown",
|
||||
"choices": reranking_llm_choices,
|
||||
},
|
||||
"separate_embedding": {
|
||||
"name": "Use separate embedding",
|
||||
"value": False,
|
||||
"choices": [("Yes", True), ("No", False)],
|
||||
"component": "dropdown",
|
||||
"special_type": "llm",
|
||||
},
|
||||
"num_retrieval": {
|
||||
"name": "Number of document chunks to retrieve",
|
||||
"value": 3,
|
||||
"value": 10,
|
||||
"component": "number",
|
||||
},
|
||||
"retrieval_mode": {
|
||||
"name": "Retrieval mode",
|
||||
"value": "vector",
|
||||
"value": "hybrid",
|
||||
"choices": ["vector", "text", "hybrid"],
|
||||
"component": "dropdown",
|
||||
},
|
||||
"prioritize_table": {
|
||||
"name": "Prioritize table",
|
||||
"value": True,
|
||||
"value": False,
|
||||
"choices": [True, False],
|
||||
"component": "checkbox",
|
||||
},
|
||||
"mmr": {
|
||||
"name": "Use MMR",
|
||||
"value": True,
|
||||
"value": False,
|
||||
"choices": [True, False],
|
||||
"component": "checkbox",
|
||||
},
|
||||
"use_reranking": {
|
||||
"name": "Use reranking",
|
||||
"value": False,
|
||||
"value": True,
|
||||
"choices": [True, False],
|
||||
"component": "checkbox",
|
||||
},
|
||||
"use_llm_reranking": {
|
||||
"name": "Use LLM relevant scoring",
|
||||
"value": True,
|
||||
"choices": [True, False],
|
||||
"component": "checkbox",
|
||||
},
|
||||
|
|
@ -232,6 +272,8 @@ class DocumentRetrievalPipeline(BaseFileIndexRetriever):
|
|||
settings: the settings of the app
|
||||
kwargs: other arguments
|
||||
"""
|
||||
use_llm_reranking = user_settings.get("use_llm_reranking", False)
|
||||
|
||||
retriever = cls(
|
||||
get_extra_table=user_settings["prioritize_table"],
|
||||
top_k=user_settings["num_retrieval"],
|
||||
|
|
@ -241,16 +283,26 @@ class DocumentRetrievalPipeline(BaseFileIndexRetriever):
|
|||
"embedding", embedding_models_manager.get_default_name()
|
||||
)
|
||||
],
|
||||
retrieval_mode=user_settings["retrieval_mode"],
|
||||
llm_scorer=(LLMTrulensScoring() if use_llm_reranking else None),
|
||||
rerankers=[CohereReranking()],
|
||||
)
|
||||
if not user_settings["use_reranking"]:
|
||||
retriever.reranker = None # type: ignore
|
||||
else:
|
||||
retriever.reranker.llm = llms.get(
|
||||
retriever.rerankers = [] # type: ignore
|
||||
|
||||
for reranker in retriever.rerankers:
|
||||
if isinstance(reranker, LLMReranking):
|
||||
reranker.llm = llms.get(
|
||||
user_settings["reranking_llm"], llms.get_default()
|
||||
)
|
||||
|
||||
if retriever.llm_scorer:
|
||||
retriever.llm_scorer.llm = llms.get(
|
||||
user_settings["reranking_llm"], llms.get_default()
|
||||
)
|
||||
|
||||
kwargs = {".doc_ids": selected}
|
||||
retriever.set_run(kwargs, temp=True)
|
||||
retriever.set_run(kwargs, temp=False)
|
||||
return retriever
|
||||
|
||||
|
||||
|
|
@ -258,8 +310,8 @@ class IndexPipeline(BaseComponent):
|
|||
"""Index a single file"""
|
||||
|
||||
loader: BaseReader
|
||||
splitter: BaseSplitter
|
||||
chunk_batch_size: int = 50
|
||||
splitter: BaseSplitter | None
|
||||
chunk_batch_size: int = 200
|
||||
|
||||
Source = Param(help="The SQLAlchemy Source table")
|
||||
Index = Param(help="The SQLAlchemy Index table")
|
||||
|
|
@ -267,6 +319,9 @@ class IndexPipeline(BaseComponent):
|
|||
DS = Param(help="The DocStore")
|
||||
FSPath = Param(help="The file storage path")
|
||||
user_id = Param(help="The user id")
|
||||
collection_name: str = "default"
|
||||
private: bool = False
|
||||
run_embedding_in_thread: bool = False
|
||||
embedding: BaseEmbeddings
|
||||
|
||||
@Node.auto(depends_on=["Source", "Index", "embedding"])
|
||||
|
|
@ -276,31 +331,81 @@ class IndexPipeline(BaseComponent):
|
|||
)
|
||||
|
||||
def handle_docs(self, docs, file_id, file_name) -> Generator[Document, None, int]:
|
||||
s_time = time.time()
|
||||
text_docs = []
|
||||
non_text_docs = []
|
||||
thumbnail_docs = []
|
||||
|
||||
for doc in docs:
|
||||
doc_type = doc.metadata.get("type", "text")
|
||||
if doc_type == "text":
|
||||
text_docs.append(doc)
|
||||
elif doc_type == "thumbnail":
|
||||
thumbnail_docs.append(doc)
|
||||
else:
|
||||
non_text_docs.append(doc)
|
||||
|
||||
print(f"Got {len(thumbnail_docs)} page thumbnails")
|
||||
page_label_to_thumbnail = {
|
||||
doc.metadata["page_label"]: doc.doc_id for doc in thumbnail_docs
|
||||
}
|
||||
|
||||
if self.splitter:
|
||||
all_chunks = self.splitter(text_docs)
|
||||
else:
|
||||
all_chunks = text_docs
|
||||
|
||||
# add the thumbnails doc_id to the chunks
|
||||
for chunk in all_chunks:
|
||||
page_label = chunk.metadata.get("page_label", None)
|
||||
if page_label and page_label in page_label_to_thumbnail:
|
||||
chunk.metadata["thumbnail_doc_id"] = page_label_to_thumbnail[page_label]
|
||||
|
||||
to_index_chunks = all_chunks + non_text_docs + thumbnail_docs
|
||||
|
||||
# add to doc store
|
||||
chunks = []
|
||||
n_chunks = 0
|
||||
for cidx, chunk in enumerate(self.splitter(docs)):
|
||||
chunks.append(chunk)
|
||||
if cidx % self.chunk_batch_size == 0:
|
||||
self.handle_chunks(chunks, file_id)
|
||||
chunk_size = self.chunk_batch_size * 4
|
||||
for start_idx in range(0, len(to_index_chunks), chunk_size):
|
||||
chunks = to_index_chunks[start_idx : start_idx + chunk_size]
|
||||
self.handle_chunks_docstore(chunks, file_id)
|
||||
n_chunks += len(chunks)
|
||||
yield Document(
|
||||
f" => [{file_name}] Processed {n_chunks} chunks",
|
||||
channel="debug",
|
||||
)
|
||||
|
||||
def insert_chunks_to_vectorstore():
|
||||
chunks = []
|
||||
yield Document(
|
||||
f" => [{file_name}] Processed {n_chunks} chunks", channel="debug"
|
||||
)
|
||||
|
||||
if chunks:
|
||||
self.handle_chunks(chunks, file_id)
|
||||
n_chunks = 0
|
||||
chunk_size = self.chunk_batch_size
|
||||
for start_idx in range(0, len(to_index_chunks), chunk_size):
|
||||
chunks = to_index_chunks[start_idx : start_idx + chunk_size]
|
||||
self.handle_chunks_vectorstore(chunks, file_id)
|
||||
n_chunks += len(chunks)
|
||||
if self.VS:
|
||||
yield Document(
|
||||
f" => [{file_name}] Processed {n_chunks} chunks", channel="debug"
|
||||
f" => [{file_name}] Created embedding for {n_chunks} chunks",
|
||||
channel="debug",
|
||||
)
|
||||
|
||||
# run vector indexing in thread if specified
|
||||
if self.run_embedding_in_thread:
|
||||
print("Running embedding in thread")
|
||||
threading.Thread(
|
||||
target=lambda: list(insert_chunks_to_vectorstore())
|
||||
).start()
|
||||
else:
|
||||
yield from insert_chunks_to_vectorstore()
|
||||
|
||||
print("indexing step took", time.time() - s_time)
|
||||
return n_chunks
|
||||
|
||||
def handle_chunks(self, chunks, file_id):
|
||||
def handle_chunks_docstore(self, chunks, file_id):
|
||||
"""Run chunks"""
|
||||
# run embedding, add to both vector store and doc store
|
||||
self.vector_indexing(chunks)
|
||||
self.vector_indexing.add_to_docstore(chunks)
|
||||
|
||||
# record in the index
|
||||
with Session(engine) as session:
|
||||
|
|
@ -313,6 +418,20 @@ class IndexPipeline(BaseComponent):
|
|||
relation_type="document",
|
||||
)
|
||||
)
|
||||
session.add_all(nodes)
|
||||
session.commit()
|
||||
|
||||
def handle_chunks_vectorstore(self, chunks, file_id):
|
||||
"""Run chunks"""
|
||||
# run embedding, add to both vector store and doc store
|
||||
self.vector_indexing.add_to_vectorstore(chunks)
|
||||
self.vector_indexing.write_chunk_to_file(chunks)
|
||||
|
||||
if self.VS:
|
||||
# record in the index
|
||||
with Session(engine) as session:
|
||||
nodes = []
|
||||
for chunk in chunks:
|
||||
nodes.append(
|
||||
self.Index(
|
||||
source_id=file_id,
|
||||
|
|
@ -332,8 +451,16 @@ class IndexPipeline(BaseComponent):
|
|||
Returns:
|
||||
the file id if the file is indexed, otherwise None
|
||||
"""
|
||||
if self.private:
|
||||
cond: tuple = (
|
||||
self.Source.name == file_path.name,
|
||||
self.Source.user == self.user_id,
|
||||
)
|
||||
else:
|
||||
cond = (self.Source.name == file_path.name,)
|
||||
|
||||
with Session(engine) as session:
|
||||
stmt = select(self.Source).where(self.Source.name == file_path.name)
|
||||
stmt = select(self.Source).where(*cond)
|
||||
item = session.execute(stmt).first()
|
||||
if item:
|
||||
return item[0].id
|
||||
|
|
@ -369,20 +496,36 @@ class IndexPipeline(BaseComponent):
|
|||
def finish(self, file_id: str, file_path: Path) -> str:
|
||||
"""Finish the indexing"""
|
||||
with Session(engine) as session:
|
||||
stmt = select(self.Index.target_id).where(self.Index.source_id == file_id)
|
||||
doc_ids = [_[0] for _ in session.execute(stmt)]
|
||||
if doc_ids:
|
||||
docs = self.DS.get(doc_ids)
|
||||
stmt = select(self.Source).where(self.Source.id == file_id)
|
||||
result = session.execute(stmt).first()
|
||||
if result:
|
||||
if not result:
|
||||
return file_id
|
||||
|
||||
item = result[0]
|
||||
item.text_length = sum([len(doc.text) for doc in docs])
|
||||
|
||||
# populate the number of tokens
|
||||
doc_ids_stmt = select(self.Index.target_id).where(
|
||||
self.Index.source_id == file_id,
|
||||
self.Index.relation_type == "document",
|
||||
)
|
||||
doc_ids = [_[0] for _ in session.execute(doc_ids_stmt)]
|
||||
token_func = self.get_token_func()
|
||||
if doc_ids and token_func:
|
||||
docs = self.DS.get(doc_ids)
|
||||
item.note["tokens"] = sum([len(token_func(doc.text)) for doc in docs])
|
||||
|
||||
# populate the note
|
||||
item.note["loader"] = self.get_from_path("loader").__class__.__name__
|
||||
|
||||
session.add(item)
|
||||
session.commit()
|
||||
|
||||
return file_id
|
||||
|
||||
def get_token_func(self):
|
||||
"""Get the token function for calculating the number of tokens"""
|
||||
return _default_token_func
|
||||
|
||||
def delete_file(self, file_id: str):
|
||||
"""Delete a file from the db, including its chunks in docstore and vectorstore
|
||||
|
||||
|
|
@ -398,44 +541,24 @@ class IndexPipeline(BaseComponent):
|
|||
for each in index:
|
||||
if each[0].relation_type == "vector":
|
||||
vs_ids.append(each[0].target_id)
|
||||
else:
|
||||
elif each[0].relation_type == "document":
|
||||
ds_ids.append(each[0].target_id)
|
||||
session.delete(each[0])
|
||||
session.commit()
|
||||
|
||||
if vs_ids and self.VS:
|
||||
self.VS.delete(vs_ids)
|
||||
if ds_ids:
|
||||
self.DS.delete(ds_ids)
|
||||
|
||||
def run(self, file_path: str | Path, reindex: bool, **kwargs) -> str:
|
||||
"""Index the file and return the file id"""
|
||||
# check for duplication
|
||||
file_path = Path(file_path).resolve()
|
||||
file_id = self.get_id_if_exists(file_path)
|
||||
if file_id is not None:
|
||||
if not reindex:
|
||||
raise ValueError(
|
||||
f"File {file_path.name} already indexed. Please rerun with "
|
||||
"reindex=True to force reindexing."
|
||||
)
|
||||
else:
|
||||
# remove the existing records
|
||||
self.delete_file(file_id)
|
||||
file_id = self.store_file(file_path)
|
||||
else:
|
||||
# add record to db
|
||||
file_id = self.store_file(file_path)
|
||||
|
||||
# extract the file
|
||||
extra_info = default_file_metadata_func(str(file_path))
|
||||
docs = self.loader.load_data(file_path, extra_info=extra_info)
|
||||
for _ in self.handle_docs(docs, file_id, file_path.name):
|
||||
continue
|
||||
self.finish(file_id, file_path)
|
||||
|
||||
return file_id
|
||||
def run(
|
||||
self, file_path: str | Path, reindex: bool, **kwargs
|
||||
) -> tuple[str, list[Document]]:
|
||||
raise NotImplementedError
|
||||
|
||||
def stream(
|
||||
self, file_path: str | Path, reindex: bool, **kwargs
|
||||
) -> Generator[Document, None, str]:
|
||||
) -> Generator[Document, None, tuple[str, list[Document]]]:
|
||||
# check for duplication
|
||||
file_path = Path(file_path).resolve()
|
||||
file_id = self.get_id_if_exists(file_path)
|
||||
|
|
@ -456,6 +579,9 @@ class IndexPipeline(BaseComponent):
|
|||
|
||||
# extract the file
|
||||
extra_info = default_file_metadata_func(str(file_path))
|
||||
extra_info["file_id"] = file_id
|
||||
extra_info["collection_name"] = self.collection_name
|
||||
|
||||
yield Document(f" => Converting {file_path.name} to text", channel="debug")
|
||||
docs = self.loader.load_data(file_path, extra_info=extra_info)
|
||||
yield Document(f" => Converted {file_path.name} to text", channel="debug")
|
||||
|
|
@ -464,7 +590,7 @@ class IndexPipeline(BaseComponent):
|
|||
self.finish(file_id, file_path)
|
||||
|
||||
yield Document(f" => Finished indexing {file_path.name}", channel="debug")
|
||||
return file_id
|
||||
return file_id, docs
|
||||
|
||||
|
||||
class IndexDocumentPipeline(BaseFileIndexIndexing):
|
||||
|
|
@ -479,16 +605,54 @@ class IndexDocumentPipeline(BaseFileIndexIndexing):
|
|||
decide which pipeline should be used.
|
||||
"""
|
||||
|
||||
reader_mode: str = Param("default", help="The reader mode")
|
||||
embedding: BaseEmbeddings
|
||||
run_embedding_in_thread: bool = False
|
||||
|
||||
@Param.auto(depends_on="reader_mode")
|
||||
def readers(self):
|
||||
readers = deepcopy(KH_DEFAULT_FILE_EXTRACTORS)
|
||||
print("reader_mode", self.reader_mode)
|
||||
if self.reader_mode == "adobe":
|
||||
readers[".pdf"] = adobe_reader
|
||||
elif self.reader_mode == "azure-di":
|
||||
readers[".pdf"] = azure_reader
|
||||
|
||||
dev_readers, _, _ = dev_settings()
|
||||
readers.update(dev_readers)
|
||||
|
||||
return readers
|
||||
|
||||
@classmethod
|
||||
def get_user_settings(cls):
|
||||
return {
|
||||
"reader_mode": {
|
||||
"name": "File loader",
|
||||
"value": "default",
|
||||
"choices": [
|
||||
("Default (open-source)", "default"),
|
||||
("Adobe API (figure+table extraction)", "adobe"),
|
||||
(
|
||||
"Azure AI Document Intelligence (figure+table extraction)",
|
||||
"azure-di",
|
||||
),
|
||||
],
|
||||
"component": "dropdown",
|
||||
},
|
||||
}
|
||||
|
||||
@classmethod
|
||||
def get_pipeline(cls, user_settings, index_settings) -> BaseFileIndexIndexing:
|
||||
use_quick_index_mode = user_settings.get("quick_index_mode", False)
|
||||
print("use_quick_index_mode", use_quick_index_mode)
|
||||
obj = cls(
|
||||
embedding=embedding_models_manager[
|
||||
index_settings.get(
|
||||
"embedding", embedding_models_manager.get_default_name()
|
||||
)
|
||||
]
|
||||
],
|
||||
run_embedding_in_thread=use_quick_index_mode,
|
||||
reader_mode=user_settings.get("reader_mode", "default"),
|
||||
)
|
||||
return obj
|
||||
|
||||
|
|
@ -497,16 +661,17 @@ class IndexDocumentPipeline(BaseFileIndexIndexing):
|
|||
|
||||
Can subclass this method for a more elaborate pipeline routing strategy.
|
||||
"""
|
||||
readers, chunk_size, chunk_overlap = dev_settings()
|
||||
_, chunk_size, chunk_overlap = dev_settings()
|
||||
|
||||
ext = file_path.suffix
|
||||
reader = readers.get(ext, KH_DEFAULT_FILE_EXTRACTORS.get(ext, None))
|
||||
ext = file_path.suffix.lower()
|
||||
reader = self.readers.get(ext, unstructured)
|
||||
if reader is None:
|
||||
raise NotImplementedError(
|
||||
f"No supported pipeline to index {file_path.name}. Please specify "
|
||||
"the suitable pipeline for this file type in the settings."
|
||||
)
|
||||
|
||||
print("Using reader", reader)
|
||||
pipeline: IndexPipeline = IndexPipeline(
|
||||
loader=reader,
|
||||
splitter=TokenSplitter(
|
||||
|
|
@ -515,50 +680,37 @@ class IndexDocumentPipeline(BaseFileIndexIndexing):
|
|||
separator="\n\n",
|
||||
backup_separators=["\n", ".", "\u200B"],
|
||||
),
|
||||
run_embedding_in_thread=self.run_embedding_in_thread,
|
||||
Source=self.Source,
|
||||
Index=self.Index,
|
||||
VS=self.VS,
|
||||
DS=self.DS,
|
||||
FSPath=self.FSPath,
|
||||
user_id=self.user_id,
|
||||
private=self.private,
|
||||
embedding=self.embedding,
|
||||
)
|
||||
|
||||
return pipeline
|
||||
|
||||
def run(
|
||||
self, file_paths: str | Path | list[str | Path], reindex: bool = False, **kwargs
|
||||
self, file_paths: str | Path | list[str | Path], *args, **kwargs
|
||||
) -> tuple[list[str | None], list[str | None]]:
|
||||
"""Return a list of indexed file ids, and a list of errors"""
|
||||
if not isinstance(file_paths, list):
|
||||
file_paths = [file_paths]
|
||||
|
||||
file_ids: list[str | None] = []
|
||||
errors: list[str | None] = []
|
||||
for file_path in file_paths:
|
||||
file_path = Path(file_path)
|
||||
|
||||
try:
|
||||
pipeline = self.route(file_path)
|
||||
file_id = pipeline.run(file_path, reindex=reindex, **kwargs)
|
||||
file_ids.append(file_id)
|
||||
errors.append(None)
|
||||
except Exception as e:
|
||||
logger.error(e)
|
||||
file_ids.append(None)
|
||||
errors.append(str(e))
|
||||
|
||||
return file_ids, errors
|
||||
raise NotImplementedError
|
||||
|
||||
def stream(
|
||||
self, file_paths: str | Path | list[str | Path], reindex: bool = False, **kwargs
|
||||
) -> Generator[Document, None, tuple[list[str | None], list[str | None]]]:
|
||||
) -> Generator[
|
||||
Document, None, tuple[list[str | None], list[str | None], list[Document]]
|
||||
]:
|
||||
"""Return a list of indexed file ids, and a list of errors"""
|
||||
if not isinstance(file_paths, list):
|
||||
file_paths = [file_paths]
|
||||
|
||||
file_ids: list[str | None] = []
|
||||
errors: list[str | None] = []
|
||||
all_docs = []
|
||||
|
||||
n_files = len(file_paths)
|
||||
for idx, file_path in enumerate(file_paths):
|
||||
file_path = Path(file_path)
|
||||
|
|
@ -569,9 +721,10 @@ class IndexDocumentPipeline(BaseFileIndexIndexing):
|
|||
|
||||
try:
|
||||
pipeline = self.route(file_path)
|
||||
file_id = yield from pipeline.stream(
|
||||
file_id, docs = yield from pipeline.stream(
|
||||
file_path, reindex=reindex, **kwargs
|
||||
)
|
||||
all_docs.extend(docs)
|
||||
file_ids.append(file_id)
|
||||
errors.append(None)
|
||||
yield Document(
|
||||
|
|
@ -579,7 +732,7 @@ class IndexDocumentPipeline(BaseFileIndexIndexing):
|
|||
channel="index",
|
||||
)
|
||||
except Exception as e:
|
||||
logger.error(e)
|
||||
logger.exception(e)
|
||||
file_ids.append(None)
|
||||
errors.append(str(e))
|
||||
yield Document(
|
||||
|
|
@ -591,4 +744,4 @@ class IndexDocumentPipeline(BaseFileIndexIndexing):
|
|||
channel="index",
|
||||
)
|
||||
|
||||
return file_ids, errors
|
||||
return file_ids, errors, all_docs
|
||||
|
|
|
|||
|
|
@ -1,5 +1,9 @@
|
|||
import html
|
||||
import os
|
||||
import shutil
|
||||
import tempfile
|
||||
import zipfile
|
||||
from copy import deepcopy
|
||||
from pathlib import Path
|
||||
from typing import Generator
|
||||
|
||||
|
|
@ -9,8 +13,12 @@ from gradio.data_classes import FileData
|
|||
from gradio.utils import NamedString
|
||||
from ktem.app import BasePage
|
||||
from ktem.db.engine import engine
|
||||
from ktem.utils.render import Render
|
||||
from sqlalchemy import select
|
||||
from sqlalchemy.orm import Session
|
||||
from theflow.settings import settings as flowsettings
|
||||
|
||||
DOWNLOAD_MESSAGE = "Press again to download"
|
||||
|
||||
|
||||
class File(gr.File):
|
||||
|
|
@ -143,10 +151,49 @@ class FileIndexPage(BasePage):
|
|||
)
|
||||
|
||||
gr.Markdown("## File List")
|
||||
self.filter = gr.Textbox(
|
||||
value="",
|
||||
label="Filter by name:",
|
||||
info=(
|
||||
"(1) Case-insensitive. "
|
||||
"(2) Search with empty string to show all files."
|
||||
),
|
||||
)
|
||||
self.file_list_state = gr.State(value=None)
|
||||
self.file_list = gr.DataFrame(
|
||||
headers=["id", "name", "size", "text_length", "date_created"],
|
||||
headers=[
|
||||
"id",
|
||||
"name",
|
||||
"size",
|
||||
"tokens",
|
||||
"loader",
|
||||
"date_created",
|
||||
],
|
||||
column_widths=["0%", "50%", "8%", "7%", "15%", "20%"],
|
||||
interactive=False,
|
||||
wrap=False,
|
||||
elem_id="file_list_view",
|
||||
)
|
||||
|
||||
with gr.Row():
|
||||
self.deselect_button = gr.Button(
|
||||
"Close",
|
||||
visible=False,
|
||||
)
|
||||
self.delete_button = gr.Button(
|
||||
"Delete",
|
||||
variant="stop",
|
||||
visible=False,
|
||||
)
|
||||
with gr.Row():
|
||||
self.is_zipped_state = gr.State(value=False)
|
||||
self.download_all_button = gr.DownloadButton(
|
||||
"Download all files",
|
||||
visible=True,
|
||||
)
|
||||
self.download_single_button = gr.DownloadButton(
|
||||
"Download file",
|
||||
visible=False,
|
||||
)
|
||||
|
||||
with gr.Row() as self.selection_info:
|
||||
|
|
@ -154,17 +201,7 @@ class FileIndexPage(BasePage):
|
|||
with gr.Column(scale=2):
|
||||
self.selected_panel = gr.Markdown(self.selected_panel_false)
|
||||
|
||||
self.deselect_button = gr.Button(
|
||||
"Deselect",
|
||||
visible=False,
|
||||
elem_classes=["right-button"],
|
||||
)
|
||||
self.delete_button = gr.Button(
|
||||
"Delete",
|
||||
variant="stop",
|
||||
visible=False,
|
||||
elem_classes=["right-button"],
|
||||
)
|
||||
self.chunks = gr.HTML(visible=False)
|
||||
|
||||
def on_subscribe_public_events(self):
|
||||
"""Subscribe to the declared public event of the app"""
|
||||
|
|
@ -189,12 +226,58 @@ class FileIndexPage(BasePage):
|
|||
)
|
||||
|
||||
def file_selected(self, file_id):
|
||||
chunks = []
|
||||
if file_id is not None:
|
||||
# get the chunks
|
||||
|
||||
Index = self._index._resources["Index"]
|
||||
with Session(engine) as session:
|
||||
matches = session.execute(
|
||||
select(Index).where(
|
||||
Index.source_id == file_id,
|
||||
Index.relation_type == "document",
|
||||
)
|
||||
)
|
||||
doc_ids = [doc.target_id for (doc,) in matches]
|
||||
docs = self._index._docstore.get(doc_ids)
|
||||
docs = sorted(
|
||||
docs, key=lambda x: x.metadata.get("page_label", float("inf"))
|
||||
)
|
||||
|
||||
for idx, doc in enumerate(docs):
|
||||
title = html.escape(
|
||||
f"{doc.text[:50]}..." if len(doc.text) > 50 else doc.text
|
||||
)
|
||||
doc_type = doc.metadata.get("type", "text")
|
||||
content = ""
|
||||
if doc_type == "text":
|
||||
content = html.escape(doc.text)
|
||||
elif doc_type == "table":
|
||||
content = Render.table(doc.text)
|
||||
elif doc_type == "image":
|
||||
content = Render.image(
|
||||
url=doc.metadata.get("image_origin", ""), text=doc.text
|
||||
)
|
||||
|
||||
header_prefix = f"[{idx+1}/{len(docs)}]"
|
||||
if doc.metadata.get("page_label"):
|
||||
header_prefix += f" [Page {doc.metadata['page_label']}]"
|
||||
|
||||
chunks.append(
|
||||
Render.collapsible(
|
||||
header=f"{header_prefix} {title}",
|
||||
content=content,
|
||||
)
|
||||
)
|
||||
return (
|
||||
gr.update(value="".join(chunks), visible=file_id is not None),
|
||||
gr.update(visible=file_id is not None),
|
||||
gr.update(visible=file_id is not None),
|
||||
gr.update(visible=file_id is not None),
|
||||
)
|
||||
|
||||
def delete_event(self, file_id):
|
||||
file_name = ""
|
||||
with Session(engine) as session:
|
||||
source = session.execute(
|
||||
select(self._index._resources["Source"]).where(
|
||||
|
|
@ -202,6 +285,7 @@ class FileIndexPage(BasePage):
|
|||
)
|
||||
).first()
|
||||
if source:
|
||||
file_name = source[0].name
|
||||
session.delete(source[0])
|
||||
|
||||
vs_ids, ds_ids = [], []
|
||||
|
|
@ -213,15 +297,16 @@ class FileIndexPage(BasePage):
|
|||
for each in index:
|
||||
if each[0].relation_type == "vector":
|
||||
vs_ids.append(each[0].target_id)
|
||||
else:
|
||||
elif each[0].relation_type == "document":
|
||||
ds_ids.append(each[0].target_id)
|
||||
session.delete(each[0])
|
||||
session.commit()
|
||||
|
||||
if vs_ids:
|
||||
self._index._vs.delete(vs_ids)
|
||||
self._index._docstore.delete(ds_ids)
|
||||
|
||||
gr.Info(f"File {file_id} has been deleted")
|
||||
gr.Info(f"File {file_name} has been deleted")
|
||||
|
||||
return None, self.selected_panel_false
|
||||
|
||||
|
|
@ -231,6 +316,57 @@ class FileIndexPage(BasePage):
|
|||
gr.update(visible=False),
|
||||
)
|
||||
|
||||
def download_single_file(self, is_zipped_state, file_id):
|
||||
with Session(engine) as session:
|
||||
source = session.execute(
|
||||
select(self._index._resources["Source"]).where(
|
||||
self._index._resources["Source"].id == file_id
|
||||
)
|
||||
).first()
|
||||
if source:
|
||||
target_file_name = Path(source[0].name)
|
||||
zip_files = []
|
||||
for file_name in os.listdir(flowsettings.KH_CHUNKS_OUTPUT_DIR):
|
||||
if target_file_name.stem in file_name:
|
||||
zip_files.append(
|
||||
os.path.join(flowsettings.KH_CHUNKS_OUTPUT_DIR, file_name)
|
||||
)
|
||||
for file_name in os.listdir(flowsettings.KH_MARKDOWN_OUTPUT_DIR):
|
||||
if target_file_name.stem in file_name:
|
||||
zip_files.append(
|
||||
os.path.join(flowsettings.KH_MARKDOWN_OUTPUT_DIR, file_name)
|
||||
)
|
||||
zip_file_path = os.path.join(
|
||||
flowsettings.KH_ZIP_OUTPUT_DIR, target_file_name.stem
|
||||
)
|
||||
with zipfile.ZipFile(f"{zip_file_path}.zip", "w") as zipMe:
|
||||
for file in zip_files:
|
||||
zipMe.write(file, arcname=os.path.basename(file))
|
||||
|
||||
if is_zipped_state:
|
||||
new_button = gr.DownloadButton(label="Download", value=None)
|
||||
else:
|
||||
new_button = gr.DownloadButton(
|
||||
label=DOWNLOAD_MESSAGE, value=f"{zip_file_path}.zip"
|
||||
)
|
||||
|
||||
return not is_zipped_state, new_button
|
||||
|
||||
def download_all_files(self):
|
||||
zip_files = []
|
||||
for file_name in os.listdir(flowsettings.KH_CHUNKS_OUTPUT_DIR):
|
||||
zip_files.append(os.path.join(flowsettings.KH_CHUNKS_OUTPUT_DIR, file_name))
|
||||
for file_name in os.listdir(flowsettings.KH_MARKDOWN_OUTPUT_DIR):
|
||||
zip_files.append(
|
||||
os.path.join(flowsettings.KH_MARKDOWN_OUTPUT_DIR, file_name)
|
||||
)
|
||||
zip_file_path = os.path.join(flowsettings.KH_ZIP_OUTPUT_DIR, "all")
|
||||
with zipfile.ZipFile(f"{zip_file_path}.zip", "w") as zipMe:
|
||||
for file in zip_files:
|
||||
arcname = Path(file)
|
||||
zipMe.write(file, arcname=arcname.name)
|
||||
return gr.DownloadButton(label=DOWNLOAD_MESSAGE, value=f"{zip_file_path}.zip")
|
||||
|
||||
def on_register_events(self):
|
||||
"""Register all events to the app"""
|
||||
onDeleted = (
|
||||
|
|
@ -241,35 +377,61 @@ class FileIndexPage(BasePage):
|
|||
)
|
||||
.then(
|
||||
fn=lambda: (None, self.selected_panel_false),
|
||||
inputs=None,
|
||||
inputs=[],
|
||||
outputs=[self.selected_file_id, self.selected_panel],
|
||||
show_progress="hidden",
|
||||
)
|
||||
.then(
|
||||
fn=self.list_file,
|
||||
inputs=[self._app.user_id],
|
||||
inputs=[self._app.user_id, self.filter],
|
||||
outputs=[self.file_list_state, self.file_list],
|
||||
)
|
||||
.then(
|
||||
fn=self.file_selected,
|
||||
inputs=[self.selected_file_id],
|
||||
outputs=[
|
||||
self.chunks,
|
||||
self.deselect_button,
|
||||
self.delete_button,
|
||||
self.download_single_button,
|
||||
],
|
||||
show_progress="hidden",
|
||||
)
|
||||
)
|
||||
for event in self._app.get_event(f"onFileIndex{self._index.id}Changed"):
|
||||
onDeleted = onDeleted.then(**event)
|
||||
|
||||
self.deselect_button.click(
|
||||
fn=lambda: (None, self.selected_panel_false),
|
||||
inputs=None,
|
||||
inputs=[],
|
||||
outputs=[self.selected_file_id, self.selected_panel],
|
||||
show_progress="hidden",
|
||||
)
|
||||
self.selected_panel.change(
|
||||
).then(
|
||||
fn=self.file_selected,
|
||||
inputs=[self.selected_file_id],
|
||||
outputs=[
|
||||
self.chunks,
|
||||
self.deselect_button,
|
||||
self.delete_button,
|
||||
self.download_single_button,
|
||||
],
|
||||
show_progress="hidden",
|
||||
)
|
||||
|
||||
self.download_all_button.click(
|
||||
fn=self.download_all_files,
|
||||
inputs=[],
|
||||
outputs=self.download_all_button,
|
||||
show_progress="hidden",
|
||||
)
|
||||
|
||||
self.download_single_button.click(
|
||||
fn=self.download_single_file,
|
||||
inputs=[self.is_zipped_state, self.selected_file_id],
|
||||
outputs=[self.is_zipped_state, self.download_single_button],
|
||||
show_progress="hidden",
|
||||
)
|
||||
|
||||
onUploaded = self.upload_button.click(
|
||||
fn=lambda: gr.update(visible=True),
|
||||
outputs=[self.upload_progress_panel],
|
||||
|
|
@ -285,9 +447,63 @@ class FileIndexPage(BasePage):
|
|||
concurrency_limit=20,
|
||||
)
|
||||
|
||||
try:
|
||||
# quick file upload event registration of first Index only
|
||||
if self._index.id == 1:
|
||||
self.quick_upload_state = gr.State(value=[])
|
||||
print("Setting up quick upload event")
|
||||
quickUploadedEvent = (
|
||||
self._app.chat_page.quick_file_upload.upload(
|
||||
fn=lambda: gr.update(
|
||||
value="Please wait for the indexing process "
|
||||
"to complete before adding your question."
|
||||
),
|
||||
outputs=self._app.chat_page.quick_file_upload_status,
|
||||
)
|
||||
.then(
|
||||
fn=self.index_fn_with_default_loaders,
|
||||
inputs=[
|
||||
self._app.chat_page.quick_file_upload,
|
||||
gr.State(value=False),
|
||||
self._app.settings_state,
|
||||
self._app.user_id,
|
||||
],
|
||||
outputs=self.quick_upload_state,
|
||||
)
|
||||
.success(
|
||||
fn=lambda: [
|
||||
gr.update(value=None),
|
||||
gr.update(value="select"),
|
||||
],
|
||||
outputs=[
|
||||
self._app.chat_page.quick_file_upload,
|
||||
self._app.chat_page._indices_input[0],
|
||||
],
|
||||
)
|
||||
)
|
||||
for event in self._app.get_event(f"onFileIndex{self._index.id}Changed"):
|
||||
quickUploadedEvent = quickUploadedEvent.then(**event)
|
||||
|
||||
quickUploadedEvent.success(
|
||||
fn=lambda x: x,
|
||||
inputs=self.quick_upload_state,
|
||||
outputs=self._app.chat_page._indices_input[1],
|
||||
).then(
|
||||
fn=lambda: gr.update(value="Indexing completed."),
|
||||
outputs=self._app.chat_page.quick_file_upload_status,
|
||||
).then(
|
||||
fn=self.list_file,
|
||||
inputs=[self._app.user_id, self.filter],
|
||||
outputs=[self.file_list_state, self.file_list],
|
||||
concurrency_limit=20,
|
||||
)
|
||||
|
||||
except Exception as e:
|
||||
print(e)
|
||||
|
||||
uploadedEvent = onUploaded.then(
|
||||
fn=self.list_file,
|
||||
inputs=[self._app.user_id],
|
||||
inputs=[self._app.user_id, self.filter],
|
||||
outputs=[self.file_list_state, self.file_list],
|
||||
concurrency_limit=20,
|
||||
)
|
||||
|
|
@ -309,16 +525,64 @@ class FileIndexPage(BasePage):
|
|||
inputs=[self.file_list],
|
||||
outputs=[self.selected_file_id, self.selected_panel],
|
||||
show_progress="hidden",
|
||||
).then(
|
||||
fn=self.file_selected,
|
||||
inputs=[self.selected_file_id],
|
||||
outputs=[
|
||||
self.chunks,
|
||||
self.deselect_button,
|
||||
self.delete_button,
|
||||
self.download_single_button,
|
||||
],
|
||||
show_progress="hidden",
|
||||
)
|
||||
|
||||
self.filter.submit(
|
||||
fn=self.list_file,
|
||||
inputs=[self._app.user_id, self.filter],
|
||||
outputs=[self.file_list_state, self.file_list],
|
||||
show_progress="hidden",
|
||||
)
|
||||
|
||||
def _on_app_created(self):
|
||||
"""Called when the app is created"""
|
||||
self._app.app.load(
|
||||
self.list_file,
|
||||
inputs=[self._app.user_id],
|
||||
inputs=[self._app.user_id, self.filter],
|
||||
outputs=[self.file_list_state, self.file_list],
|
||||
)
|
||||
|
||||
def _may_extract_zip(self, files, zip_dir: str):
|
||||
"""Handle zip files"""
|
||||
zip_files = [file for file in files if file.endswith(".zip")]
|
||||
remaining_files = [file for file in files if not file.endswith("zip")]
|
||||
|
||||
# Clean-up <zip_dir> before unzip to remove old files
|
||||
shutil.rmtree(zip_dir, ignore_errors=True)
|
||||
|
||||
for zip_file in zip_files:
|
||||
# Prepare new zip output dir, separated for each files
|
||||
basename = os.path.splitext(os.path.basename(zip_file))[0]
|
||||
zip_out_dir = os.path.join(zip_dir, basename)
|
||||
os.makedirs(zip_out_dir, exist_ok=True)
|
||||
with zipfile.ZipFile(zip_file, "r") as zip_ref:
|
||||
zip_ref.extractall(zip_out_dir)
|
||||
|
||||
n_zip_file = 0
|
||||
for root, dirs, files in os.walk(zip_dir):
|
||||
for file in files:
|
||||
ext = os.path.splitext(file)[1]
|
||||
|
||||
# only allow supported file-types ( not zip )
|
||||
if ext not in [".zip"] and ext in self._supported_file_types:
|
||||
remaining_files += [os.path.join(root, file)]
|
||||
n_zip_file += 1
|
||||
|
||||
if n_zip_file > 0:
|
||||
print(f"Update zip files: {n_zip_file}")
|
||||
|
||||
return remaining_files
|
||||
|
||||
def index_fn(
|
||||
self, files, reindex: bool, settings, user_id
|
||||
) -> Generator[tuple[str, str], None, None]:
|
||||
|
|
@ -335,6 +599,8 @@ class FileIndexPage(BasePage):
|
|||
yield "", ""
|
||||
return
|
||||
|
||||
files = self._may_extract_zip(files, flowsettings.KH_ZIP_INPUT_DIR)
|
||||
|
||||
errors = self.validate(files)
|
||||
if errors:
|
||||
gr.Warning(", ".join(errors))
|
||||
|
|
@ -366,19 +632,61 @@ class FileIndexPage(BasePage):
|
|||
debugs.append(response.text)
|
||||
yield "\n".join(outputs), "\n".join(debugs)
|
||||
except StopIteration as e:
|
||||
result, errors = e.value
|
||||
results, index_errors, docs = e.value
|
||||
except Exception as e:
|
||||
debugs.append(f"Error: {e}")
|
||||
yield "\n".join(outputs), "\n".join(debugs)
|
||||
return
|
||||
|
||||
n_successes = len([_ for _ in result if _])
|
||||
n_successes = len([_ for _ in results if _])
|
||||
if n_successes:
|
||||
gr.Info(f"Successfully index {n_successes} files")
|
||||
n_errors = len([_ for _ in errors if _])
|
||||
if n_errors:
|
||||
gr.Warning(f"Have errors for {n_errors} files")
|
||||
|
||||
return results
|
||||
|
||||
def index_fn_with_default_loaders(
|
||||
self, files, reindex: bool, settings, user_id
|
||||
) -> list["str"]:
|
||||
"""Function for quick upload with default loaders
|
||||
|
||||
Args:
|
||||
files: the list of files to be uploaded
|
||||
reindex: whether to reindex the files
|
||||
selected_files: the list of files already selected
|
||||
settings: the settings of the app
|
||||
"""
|
||||
print("Overriding with default loaders")
|
||||
exist_ids = []
|
||||
to_process_files = []
|
||||
for str_file_path in files:
|
||||
file_path = Path(str(str_file_path))
|
||||
exist_id = (
|
||||
self._index.get_indexing_pipeline(settings, user_id)
|
||||
.route(file_path)
|
||||
.get_id_if_exists(file_path)
|
||||
)
|
||||
if exist_id:
|
||||
exist_ids.append(exist_id)
|
||||
else:
|
||||
to_process_files.append(str_file_path)
|
||||
|
||||
returned_ids = []
|
||||
settings = deepcopy(settings)
|
||||
settings[f"index.options.{self._index.id}.reader_mode"] = "default"
|
||||
settings[f"index.options.{self._index.id}.quick_index_mode"] = True
|
||||
if to_process_files:
|
||||
_iter = self.index_fn(to_process_files, reindex, settings, user_id)
|
||||
try:
|
||||
while next(_iter):
|
||||
pass
|
||||
except StopIteration as e:
|
||||
returned_ids = e.value
|
||||
|
||||
return exist_ids + returned_ids
|
||||
|
||||
def index_files_from_dir(
|
||||
self, folder_path, reindex, settings, user_id
|
||||
) -> Generator[tuple[str, str], None, None]:
|
||||
|
|
@ -452,7 +760,19 @@ class FileIndexPage(BasePage):
|
|||
|
||||
yield from self.index_fn(files, reindex, settings, user_id)
|
||||
|
||||
def list_file(self, user_id):
|
||||
def format_size_human_readable(self, num: float | str, suffix="B"):
|
||||
try:
|
||||
num = float(num)
|
||||
except ValueError:
|
||||
return num
|
||||
|
||||
for unit in ("", "K", "M", "G", "T", "P", "E", "Z"):
|
||||
if abs(num) < 1024.0:
|
||||
return f"{num:3.0f}{unit}{suffix}"
|
||||
num /= 1024.0
|
||||
return f"{num:.0f}Yi{suffix}"
|
||||
|
||||
def list_file(self, user_id, name_pattern=""):
|
||||
if user_id is None:
|
||||
# not signed in
|
||||
return [], pd.DataFrame.from_records(
|
||||
|
|
@ -461,7 +781,8 @@ class FileIndexPage(BasePage):
|
|||
"id": "-",
|
||||
"name": "-",
|
||||
"size": "-",
|
||||
"text_length": "-",
|
||||
"tokens": "-",
|
||||
"loader": "-",
|
||||
"date_created": "-",
|
||||
}
|
||||
]
|
||||
|
|
@ -472,12 +793,17 @@ class FileIndexPage(BasePage):
|
|||
statement = select(Source)
|
||||
if self._index.config.get("private", False):
|
||||
statement = statement.where(Source.user == user_id)
|
||||
if name_pattern:
|
||||
statement = statement.where(Source.name.ilike(f"%{name_pattern}%"))
|
||||
results = [
|
||||
{
|
||||
"id": each[0].id,
|
||||
"name": each[0].name,
|
||||
"size": each[0].size,
|
||||
"text_length": each[0].text_length,
|
||||
"size": self.format_size_human_readable(each[0].size),
|
||||
"tokens": self.format_size_human_readable(
|
||||
each[0].note.get("tokens", "-"), suffix=""
|
||||
),
|
||||
"loader": each[0].note.get("loader", "-"),
|
||||
"date_created": each[0].date_created.strftime("%Y-%m-%d %H:%M:%S"),
|
||||
}
|
||||
for each in session.execute(statement).all()
|
||||
|
|
@ -492,12 +818,14 @@ class FileIndexPage(BasePage):
|
|||
"id": "-",
|
||||
"name": "-",
|
||||
"size": "-",
|
||||
"text_length": "-",
|
||||
"tokens": "-",
|
||||
"loader": "-",
|
||||
"date_created": "-",
|
||||
}
|
||||
]
|
||||
)
|
||||
|
||||
print(f"{len(results)=}, {len(file_list)=}")
|
||||
return results, file_list
|
||||
|
||||
def interact_file_list(self, list_files, ev: gr.SelectData):
|
||||
|
|
@ -561,9 +889,8 @@ class FileSelector(BasePage):
|
|||
self.mode = gr.Radio(
|
||||
value=default_mode,
|
||||
choices=[
|
||||
("Disabled", "disabled"),
|
||||
("Search All", "all"),
|
||||
("Select", "select"),
|
||||
("Search In File(s)", "select"),
|
||||
],
|
||||
container=False,
|
||||
)
|
||||
|
|
|
|||
|
|
@ -122,9 +122,12 @@ class IndexManager:
|
|||
"please restart to reflect the changes."
|
||||
)
|
||||
|
||||
try:
|
||||
try:
|
||||
# clean up
|
||||
index.on_delete()
|
||||
except Exception as e:
|
||||
print(f"Error while deleting index {index.name}: {e}")
|
||||
|
||||
# remove from database
|
||||
with Session(engine) as sess:
|
||||
|
|
|
|||
|
|
@ -7,6 +7,21 @@ from ktem.utils.file import YAMLNoDateSafeLoader
|
|||
from .manager import IndexManager
|
||||
|
||||
|
||||
# UGLY way to restart gradio server by updating atime
|
||||
def update_current_module_atime():
|
||||
import os
|
||||
import time
|
||||
|
||||
# Define the file path
|
||||
file_path = __file__
|
||||
print("Updating atime for", file_path)
|
||||
|
||||
# Get the current time
|
||||
current_time = time.time()
|
||||
# Set the modified time (and access time) to the current time
|
||||
os.utime(file_path, (current_time, current_time))
|
||||
|
||||
|
||||
def format_description(cls):
|
||||
user_settings = cls.get_admin_settings()
|
||||
params_lines = ["| Name | Default | Description |", "| --- | --- | --- |"]
|
||||
|
|
@ -29,7 +44,7 @@ class IndexManagement(BasePage):
|
|||
def on_building_ui(self):
|
||||
with gr.Tab(label="View"):
|
||||
self.index_list = gr.DataFrame(
|
||||
headers=["ID", "Name", "Index Type"],
|
||||
headers=["id", "name", "index type"],
|
||||
interactive=False,
|
||||
)
|
||||
|
||||
|
|
@ -95,7 +110,7 @@ class IndexManagement(BasePage):
|
|||
"""Called when the app is created"""
|
||||
self._app.app.load(
|
||||
self.list_indices,
|
||||
inputs=None,
|
||||
inputs=[],
|
||||
outputs=[self.index_list],
|
||||
)
|
||||
self._app.app.load(
|
||||
|
|
@ -117,7 +132,7 @@ class IndexManagement(BasePage):
|
|||
self.create_index,
|
||||
inputs=[self.name, self.index_type, self.spec],
|
||||
outputs=None,
|
||||
).success(self.list_indices, inputs=None, outputs=[self.index_list]).success(
|
||||
).success(self.list_indices, inputs=[], outputs=[self.index_list]).success(
|
||||
lambda: ("", None, "", self.spec_desc_default),
|
||||
outputs=[
|
||||
self.name,
|
||||
|
|
@ -125,6 +140,8 @@ class IndexManagement(BasePage):
|
|||
self.spec,
|
||||
self.spec_desc,
|
||||
],
|
||||
).success(
|
||||
update_current_module_atime
|
||||
)
|
||||
self.index_list.select(
|
||||
self.select_index,
|
||||
|
|
@ -152,7 +169,7 @@ class IndexManagement(BasePage):
|
|||
gr.update(visible=False),
|
||||
gr.update(visible=True),
|
||||
),
|
||||
inputs=None,
|
||||
inputs=[],
|
||||
outputs=[
|
||||
self.btn_edit_save,
|
||||
self.btn_delete,
|
||||
|
|
@ -166,10 +183,8 @@ class IndexManagement(BasePage):
|
|||
inputs=[self.selected_index_id],
|
||||
outputs=[self.selected_index_id],
|
||||
show_progress="hidden",
|
||||
).then(
|
||||
self.list_indices,
|
||||
inputs=None,
|
||||
outputs=[self.index_list],
|
||||
).then(self.list_indices, inputs=[], outputs=[self.index_list],).success(
|
||||
update_current_module_atime
|
||||
)
|
||||
self.btn_delete_no.click(
|
||||
lambda: (
|
||||
|
|
@ -178,7 +193,7 @@ class IndexManagement(BasePage):
|
|||
gr.update(visible=True),
|
||||
gr.update(visible=False),
|
||||
),
|
||||
inputs=None,
|
||||
inputs=[],
|
||||
outputs=[
|
||||
self.btn_edit_save,
|
||||
self.btn_delete,
|
||||
|
|
@ -197,7 +212,7 @@ class IndexManagement(BasePage):
|
|||
show_progress="hidden",
|
||||
).then(
|
||||
self.list_indices,
|
||||
inputs=None,
|
||||
inputs=[],
|
||||
outputs=[self.index_list],
|
||||
)
|
||||
self.btn_close.click(
|
||||
|
|
@ -245,16 +260,16 @@ class IndexManagement(BasePage):
|
|||
items = []
|
||||
for item in self.manager.indices:
|
||||
record = {}
|
||||
record["ID"] = item.id
|
||||
record["Name"] = item.name
|
||||
record["Index Type"] = item.__class__.__name__
|
||||
record["id"] = item.id
|
||||
record["name"] = item.name
|
||||
record["index type"] = item.__class__.__name__
|
||||
items.append(record)
|
||||
|
||||
if items:
|
||||
indices_list = pd.DataFrame.from_records(items)
|
||||
else:
|
||||
indices_list = pd.DataFrame.from_records(
|
||||
[{"ID": "-", "Name": "-", "Index Type": "-"}]
|
||||
[{"id": "-", "name": "-", "index type": "-"}]
|
||||
)
|
||||
|
||||
return indices_list
|
||||
|
|
@ -268,7 +283,7 @@ class IndexManagement(BasePage):
|
|||
if not ev.selected:
|
||||
return -1
|
||||
|
||||
return int(index_list["ID"][ev.index[0]])
|
||||
return int(index_list["id"][ev.index[0]])
|
||||
|
||||
def on_selected_index_change(self, selected_index_id: int):
|
||||
"""Show the relevant index as user selects it on the UI
|
||||
|
|
|
|||
|
|
@ -3,7 +3,7 @@ from typing import Optional, Type, overload
|
|||
from sqlalchemy import select
|
||||
from sqlalchemy.orm import Session
|
||||
from theflow.settings import settings as flowsettings
|
||||
from theflow.utils.modules import deserialize
|
||||
from theflow.utils.modules import deserialize, import_dotted_string
|
||||
|
||||
from kotaemon.llms import ChatLLM
|
||||
|
||||
|
|
@ -38,7 +38,7 @@ class LLMManager:
|
|||
|
||||
def load(self):
|
||||
"""Load the model pool from database"""
|
||||
self._models, self._info, self._defaut = {}, {}, ""
|
||||
self._models, self._info, self._default = {}, {}, ""
|
||||
with Session(engine) as session:
|
||||
stmt = select(LLMTable)
|
||||
items = session.execute(stmt)
|
||||
|
|
@ -54,14 +54,12 @@ class LLMManager:
|
|||
self._default = item.name
|
||||
|
||||
def load_vendors(self):
|
||||
from kotaemon.llms import (
|
||||
AzureChatOpenAI,
|
||||
ChatOpenAI,
|
||||
EndpointChatLLM,
|
||||
LlamaCppChat,
|
||||
)
|
||||
from kotaemon.llms import AzureChatOpenAI, ChatOpenAI, LlamaCppChat
|
||||
|
||||
self._vendors = [ChatOpenAI, AzureChatOpenAI, LlamaCppChat, EndpointChatLLM]
|
||||
self._vendors = [ChatOpenAI, AzureChatOpenAI, LlamaCppChat]
|
||||
|
||||
for extra_vendor in getattr(flowsettings, "KH_LLM_EXTRA_VENDORS", []):
|
||||
self._vendors.append(import_dotted_string(extra_vendor, safe=False))
|
||||
|
||||
def __getitem__(self, key: str) -> ChatLLM:
|
||||
"""Get model by name"""
|
||||
|
|
|
|||
|
|
@ -112,7 +112,7 @@ class LLMManagement(BasePage):
|
|||
"""Called when the app is created"""
|
||||
self._app.app.load(
|
||||
self.list_llms,
|
||||
inputs=None,
|
||||
inputs=[],
|
||||
outputs=[self.llm_list],
|
||||
)
|
||||
self._app.app.load(
|
||||
|
|
@ -140,8 +140,8 @@ class LLMManagement(BasePage):
|
|||
self.btn_new.click(
|
||||
self.create_llm,
|
||||
inputs=[self.name, self.llm_choices, self.spec, self.default],
|
||||
outputs=None,
|
||||
).success(self.list_llms, inputs=None, outputs=[self.llm_list]).success(
|
||||
outputs=[],
|
||||
).success(self.list_llms, inputs=[], outputs=[self.llm_list]).success(
|
||||
lambda: ("", None, "", False, self.spec_desc_default),
|
||||
outputs=[
|
||||
self.name,
|
||||
|
|
@ -176,7 +176,7 @@ class LLMManagement(BasePage):
|
|||
)
|
||||
self.btn_delete.click(
|
||||
self.on_btn_delete_click,
|
||||
inputs=None,
|
||||
inputs=[],
|
||||
outputs=[self.btn_delete, self.btn_delete_yes, self.btn_delete_no],
|
||||
show_progress="hidden",
|
||||
)
|
||||
|
|
@ -187,7 +187,7 @@ class LLMManagement(BasePage):
|
|||
show_progress="hidden",
|
||||
).then(
|
||||
self.list_llms,
|
||||
inputs=None,
|
||||
inputs=[],
|
||||
outputs=[self.llm_list],
|
||||
)
|
||||
self.btn_delete_no.click(
|
||||
|
|
@ -196,7 +196,7 @@ class LLMManagement(BasePage):
|
|||
gr.update(visible=False),
|
||||
gr.update(visible=False),
|
||||
),
|
||||
inputs=None,
|
||||
inputs=[],
|
||||
outputs=[self.btn_delete, self.btn_delete_yes, self.btn_delete_no],
|
||||
show_progress="hidden",
|
||||
)
|
||||
|
|
@ -210,7 +210,7 @@ class LLMManagement(BasePage):
|
|||
show_progress="hidden",
|
||||
).then(
|
||||
self.list_llms,
|
||||
inputs=None,
|
||||
inputs=[],
|
||||
outputs=[self.llm_list],
|
||||
)
|
||||
self.btn_close.click(
|
||||
|
|
|
|||
|
|
@ -44,7 +44,7 @@ class App(BaseApp):
|
|||
if len(self.index_manager.indices) == 1:
|
||||
for index in self.index_manager.indices:
|
||||
with gr.Tab(
|
||||
f"{index.name} Index",
|
||||
f"{index.name}",
|
||||
elem_id="indices-tab",
|
||||
elem_classes=[
|
||||
"fill-main-area-height",
|
||||
|
|
@ -58,7 +58,7 @@ class App(BaseApp):
|
|||
setattr(self, f"_index_{index.id}", page)
|
||||
elif len(self.index_manager.indices) > 1:
|
||||
with gr.Tab(
|
||||
"Indices",
|
||||
"Files",
|
||||
elem_id="indices-tab",
|
||||
elem_classes=["fill-main-area-height", "scrollable", "indices-tab"],
|
||||
id="indices-tab",
|
||||
|
|
@ -66,7 +66,7 @@ class App(BaseApp):
|
|||
) as self._tabs["indices-tab"]:
|
||||
for index in self.index_manager.indices:
|
||||
with gr.Tab(
|
||||
f"{index.name}",
|
||||
f"{index.name} Collection",
|
||||
elem_id=f"{index.id}-tab",
|
||||
) as self._tabs[f"{index.id}-tab"]:
|
||||
page = index.get_index_page_ui()
|
||||
|
|
|
|||
|
|
@ -1,15 +1,25 @@
|
|||
import asyncio
|
||||
import csv
|
||||
from copy import deepcopy
|
||||
from datetime import datetime
|
||||
from pathlib import Path
|
||||
from typing import Optional
|
||||
|
||||
import gradio as gr
|
||||
from filelock import FileLock
|
||||
from ktem.app import BasePage
|
||||
from ktem.components import reasonings
|
||||
from ktem.db.models import Conversation, engine
|
||||
from ktem.index.file.ui import File
|
||||
from ktem.reasoning.prompt_optimization.suggest_conversation_name import (
|
||||
SuggestConvNamePipeline,
|
||||
)
|
||||
from plotly.io import from_json
|
||||
from sqlmodel import Session, select
|
||||
from theflow.settings import settings as flowsettings
|
||||
|
||||
from kotaemon.base import Document
|
||||
from kotaemon.indices.ingests.files import KH_DEFAULT_FILE_EXTRACTORS
|
||||
|
||||
from .chat_panel import ChatPanel
|
||||
from .chat_suggestion import ChatSuggestion
|
||||
|
|
@ -17,23 +27,49 @@ from .common import STATE
|
|||
from .control import ConversationControl
|
||||
from .report import ReportIssue
|
||||
|
||||
DEFAULT_SETTING = "(default)"
|
||||
INFO_PANEL_SCALES = {True: 8, False: 4}
|
||||
|
||||
|
||||
pdfview_js = """
|
||||
function() {
|
||||
// Get all links and attach click event
|
||||
var links = document.getElementsByClassName("pdf-link");
|
||||
for (var i = 0; i < links.length; i++) {
|
||||
links[i].onclick = openModal;
|
||||
}
|
||||
}
|
||||
"""
|
||||
|
||||
|
||||
class ChatPage(BasePage):
|
||||
def __init__(self, app):
|
||||
self._app = app
|
||||
self._indices_input = []
|
||||
|
||||
self.on_building_ui()
|
||||
self._reasoning_type = gr.State(value=None)
|
||||
self._llm_type = gr.State(value=None)
|
||||
self._conversation_renamed = gr.State(value=False)
|
||||
self.info_panel_expanded = gr.State(value=True)
|
||||
|
||||
def on_building_ui(self):
|
||||
with gr.Row():
|
||||
self.chat_state = gr.State(STATE)
|
||||
with gr.Column(scale=1, elem_id="conv-settings-panel"):
|
||||
self.state_chat = gr.State(STATE)
|
||||
self.state_retrieval_history = gr.State([])
|
||||
self.state_chat_history = gr.State([])
|
||||
self.state_plot_history = gr.State([])
|
||||
self.state_settings = gr.State({})
|
||||
self.state_info_panel = gr.State("")
|
||||
self.state_plot_panel = gr.State(None)
|
||||
|
||||
with gr.Column(scale=1, elem_id="conv-settings-panel") as self.conv_column:
|
||||
self.chat_control = ConversationControl(self._app)
|
||||
|
||||
if getattr(flowsettings, "KH_FEATURE_CHAT_SUGGESTION", False):
|
||||
self.chat_suggestion = ChatSuggestion(self._app)
|
||||
|
||||
for index in self._app.index_manager.indices:
|
||||
for index_id, index in enumerate(self._app.index_manager.indices):
|
||||
index.selector = None
|
||||
index_ui = index.get_selector_component_ui()
|
||||
if not index_ui:
|
||||
|
|
@ -41,7 +77,9 @@ class ChatPage(BasePage):
|
|||
continue
|
||||
|
||||
index_ui.unrender() # need to rerender later within Accordion
|
||||
with gr.Accordion(label=f"{index.name} Index", open=True):
|
||||
with gr.Accordion(
|
||||
label=f"{index.name} Collection", open=index_id < 1
|
||||
):
|
||||
index_ui.render()
|
||||
gr_index = index_ui.as_gradio_component()
|
||||
if gr_index:
|
||||
|
|
@ -60,14 +98,66 @@ class ChatPage(BasePage):
|
|||
self._indices_input.append(gr_index)
|
||||
setattr(self, f"_index_{index.id}", index_ui)
|
||||
|
||||
if len(self._app.index_manager.indices) > 0:
|
||||
with gr.Accordion(label="Quick Upload") as _:
|
||||
self.quick_file_upload = File(
|
||||
file_types=list(KH_DEFAULT_FILE_EXTRACTORS.keys()),
|
||||
file_count="multiple",
|
||||
container=True,
|
||||
show_label=False,
|
||||
)
|
||||
self.quick_file_upload_status = gr.Markdown()
|
||||
|
||||
self.report_issue = ReportIssue(self._app)
|
||||
|
||||
with gr.Column(scale=6, elem_id="chat-area"):
|
||||
self.chat_panel = ChatPanel(self._app)
|
||||
|
||||
with gr.Column(scale=3, elem_id="chat-info-panel"):
|
||||
with gr.Row():
|
||||
with gr.Accordion(label="Chat settings", open=False):
|
||||
# a quick switch for reasoning type option
|
||||
with gr.Row():
|
||||
gr.HTML("Reasoning method")
|
||||
gr.HTML("Model")
|
||||
|
||||
with gr.Row():
|
||||
reasoning_type_values = [
|
||||
(DEFAULT_SETTING, DEFAULT_SETTING)
|
||||
] + self._app.default_settings.reasoning.settings[
|
||||
"use"
|
||||
].choices
|
||||
self.reasoning_types = gr.Dropdown(
|
||||
choices=reasoning_type_values,
|
||||
value=DEFAULT_SETTING,
|
||||
container=False,
|
||||
show_label=False,
|
||||
)
|
||||
self.model_types = gr.Dropdown(
|
||||
choices=self._app.default_settings.reasoning.options[
|
||||
"simple"
|
||||
]
|
||||
.settings["llm"]
|
||||
.choices,
|
||||
value="",
|
||||
container=False,
|
||||
show_label=False,
|
||||
)
|
||||
|
||||
with gr.Column(
|
||||
scale=INFO_PANEL_SCALES[False], elem_id="chat-info-panel"
|
||||
) as self.info_column:
|
||||
with gr.Accordion(label="Information panel", open=True):
|
||||
self.info_panel = gr.HTML()
|
||||
self.modal = gr.HTML("<div id='pdf-modal'></div>")
|
||||
self.plot_panel = gr.Plot(visible=False)
|
||||
self.info_panel = gr.HTML(elem_id="html-info-panel")
|
||||
|
||||
def _json_to_plot(self, json_dict: dict | None):
|
||||
if json_dict:
|
||||
plot = from_json(json_dict)
|
||||
plot = gr.update(visible=True, value=plot)
|
||||
else:
|
||||
plot = gr.update(visible=False)
|
||||
return plot
|
||||
|
||||
def on_register_events(self):
|
||||
gr.on(
|
||||
|
|
@ -98,27 +188,75 @@ class ChatPage(BasePage):
|
|||
self.chat_control.conversation_id,
|
||||
self.chat_panel.chatbot,
|
||||
self._app.settings_state,
|
||||
self.chat_state,
|
||||
self._reasoning_type,
|
||||
self._llm_type,
|
||||
self.state_chat,
|
||||
self._app.user_id,
|
||||
]
|
||||
+ self._indices_input,
|
||||
outputs=[
|
||||
self.chat_panel.chatbot,
|
||||
self.info_panel,
|
||||
self.chat_state,
|
||||
self.plot_panel,
|
||||
self.state_plot_panel,
|
||||
self.state_chat,
|
||||
],
|
||||
concurrency_limit=20,
|
||||
show_progress="minimal",
|
||||
).success(
|
||||
fn=self.backup_original_info,
|
||||
inputs=[
|
||||
self.chat_panel.chatbot,
|
||||
self._app.settings_state,
|
||||
self.info_panel,
|
||||
self.state_chat_history,
|
||||
],
|
||||
outputs=[
|
||||
self.state_chat_history,
|
||||
self.state_settings,
|
||||
self.state_info_panel,
|
||||
],
|
||||
).then(
|
||||
fn=self.update_data_source,
|
||||
fn=self.persist_data_source,
|
||||
inputs=[
|
||||
self.chat_control.conversation_id,
|
||||
self._app.user_id,
|
||||
self.info_panel,
|
||||
self.state_plot_panel,
|
||||
self.state_retrieval_history,
|
||||
self.state_plot_history,
|
||||
self.chat_panel.chatbot,
|
||||
self.chat_state,
|
||||
self.state_chat,
|
||||
]
|
||||
+ self._indices_input,
|
||||
outputs=None,
|
||||
outputs=[
|
||||
self.state_retrieval_history,
|
||||
self.state_plot_history,
|
||||
],
|
||||
concurrency_limit=20,
|
||||
).success(
|
||||
fn=self.check_and_suggest_name_conv,
|
||||
inputs=self.chat_panel.chatbot,
|
||||
outputs=[
|
||||
self.chat_control.conversation_rn,
|
||||
self._conversation_renamed,
|
||||
],
|
||||
).success(
|
||||
self.chat_control.rename_conv,
|
||||
inputs=[
|
||||
self.chat_control.conversation_id,
|
||||
self.chat_control.conversation_rn,
|
||||
self._conversation_renamed,
|
||||
self._app.user_id,
|
||||
],
|
||||
outputs=[
|
||||
self.chat_control.conversation,
|
||||
self.chat_control.conversation,
|
||||
self.chat_control.conversation_rn,
|
||||
],
|
||||
show_progress="hidden",
|
||||
).then(
|
||||
fn=None, inputs=None, outputs=None, js=pdfview_js
|
||||
)
|
||||
|
||||
self.chat_panel.regen_btn.click(
|
||||
|
|
@ -127,33 +265,90 @@ class ChatPage(BasePage):
|
|||
self.chat_control.conversation_id,
|
||||
self.chat_panel.chatbot,
|
||||
self._app.settings_state,
|
||||
self.chat_state,
|
||||
self._reasoning_type,
|
||||
self._llm_type,
|
||||
self.state_chat,
|
||||
self._app.user_id,
|
||||
]
|
||||
+ self._indices_input,
|
||||
outputs=[
|
||||
self.chat_panel.chatbot,
|
||||
self.info_panel,
|
||||
self.chat_state,
|
||||
self.plot_panel,
|
||||
self.state_plot_panel,
|
||||
self.state_chat,
|
||||
],
|
||||
concurrency_limit=20,
|
||||
show_progress="minimal",
|
||||
).then(
|
||||
fn=self.update_data_source,
|
||||
fn=self.persist_data_source,
|
||||
inputs=[
|
||||
self.chat_control.conversation_id,
|
||||
self._app.user_id,
|
||||
self.info_panel,
|
||||
self.state_plot_panel,
|
||||
self.state_retrieval_history,
|
||||
self.state_plot_history,
|
||||
self.chat_panel.chatbot,
|
||||
self.chat_state,
|
||||
self.state_chat,
|
||||
]
|
||||
+ self._indices_input,
|
||||
outputs=None,
|
||||
outputs=[
|
||||
self.state_retrieval_history,
|
||||
self.state_plot_history,
|
||||
],
|
||||
concurrency_limit=20,
|
||||
).success(
|
||||
fn=self.check_and_suggest_name_conv,
|
||||
inputs=self.chat_panel.chatbot,
|
||||
outputs=[
|
||||
self.chat_control.conversation_rn,
|
||||
self._conversation_renamed,
|
||||
],
|
||||
).success(
|
||||
self.chat_control.rename_conv,
|
||||
inputs=[
|
||||
self.chat_control.conversation_id,
|
||||
self.chat_control.conversation_rn,
|
||||
self._conversation_renamed,
|
||||
self._app.user_id,
|
||||
],
|
||||
outputs=[
|
||||
self.chat_control.conversation,
|
||||
self.chat_control.conversation,
|
||||
self.chat_control.conversation_rn,
|
||||
],
|
||||
show_progress="hidden",
|
||||
).then(
|
||||
fn=None, inputs=None, outputs=None, js=pdfview_js
|
||||
)
|
||||
|
||||
self.chat_control.btn_info_expand.click(
|
||||
fn=lambda is_expanded: (
|
||||
gr.update(scale=INFO_PANEL_SCALES[is_expanded]),
|
||||
not is_expanded,
|
||||
),
|
||||
inputs=self.info_panel_expanded,
|
||||
outputs=[self.info_column, self.info_panel_expanded],
|
||||
)
|
||||
|
||||
self.chat_panel.chatbot.like(
|
||||
fn=self.is_liked,
|
||||
inputs=[self.chat_control.conversation_id],
|
||||
outputs=None,
|
||||
).success(
|
||||
self.save_log,
|
||||
inputs=[
|
||||
self.chat_control.conversation_id,
|
||||
self.chat_panel.chatbot,
|
||||
self._app.settings_state,
|
||||
self.info_panel,
|
||||
self.state_chat_history,
|
||||
self.state_settings,
|
||||
self.state_info_panel,
|
||||
gr.State(getattr(flowsettings, "KH_APP_DATA_DIR", "logs")),
|
||||
],
|
||||
outputs=None,
|
||||
)
|
||||
|
||||
self.chat_control.btn_new.click(
|
||||
|
|
@ -163,17 +358,25 @@ class ChatPage(BasePage):
|
|||
show_progress="hidden",
|
||||
).then(
|
||||
self.chat_control.select_conv,
|
||||
inputs=[self.chat_control.conversation],
|
||||
inputs=[self.chat_control.conversation, self._app.user_id],
|
||||
outputs=[
|
||||
self.chat_control.conversation_id,
|
||||
self.chat_control.conversation,
|
||||
self.chat_control.conversation_rn,
|
||||
self.chat_panel.chatbot,
|
||||
self.info_panel,
|
||||
self.chat_state,
|
||||
self.state_plot_panel,
|
||||
self.state_retrieval_history,
|
||||
self.state_plot_history,
|
||||
self.chat_control.cb_is_public,
|
||||
self.state_chat,
|
||||
]
|
||||
+ self._indices_input,
|
||||
show_progress="hidden",
|
||||
).then(
|
||||
fn=self._json_to_plot,
|
||||
inputs=self.state_plot_panel,
|
||||
outputs=self.plot_panel,
|
||||
)
|
||||
|
||||
self.chat_control.btn_del.click(
|
||||
|
|
@ -188,17 +391,25 @@ class ChatPage(BasePage):
|
|||
show_progress="hidden",
|
||||
).then(
|
||||
self.chat_control.select_conv,
|
||||
inputs=[self.chat_control.conversation],
|
||||
inputs=[self.chat_control.conversation, self._app.user_id],
|
||||
outputs=[
|
||||
self.chat_control.conversation_id,
|
||||
self.chat_control.conversation,
|
||||
self.chat_control.conversation_rn,
|
||||
self.chat_panel.chatbot,
|
||||
self.info_panel,
|
||||
self.chat_state,
|
||||
self.state_plot_panel,
|
||||
self.state_retrieval_history,
|
||||
self.state_plot_history,
|
||||
self.chat_control.cb_is_public,
|
||||
self.state_chat,
|
||||
]
|
||||
+ self._indices_input,
|
||||
show_progress="hidden",
|
||||
).then(
|
||||
fn=self._json_to_plot,
|
||||
inputs=self.state_plot_panel,
|
||||
outputs=self.plot_panel,
|
||||
).then(
|
||||
lambda: self.toggle_delete(""),
|
||||
outputs=[self.chat_control._new_delete, self.chat_control._delete_confirm],
|
||||
|
|
@ -207,33 +418,80 @@ class ChatPage(BasePage):
|
|||
lambda: self.toggle_delete(""),
|
||||
outputs=[self.chat_control._new_delete, self.chat_control._delete_confirm],
|
||||
)
|
||||
self.chat_control.conversation_rn_btn.click(
|
||||
self.chat_control.btn_conversation_rn.click(
|
||||
lambda: gr.update(visible=True),
|
||||
outputs=[
|
||||
self.chat_control.conversation_rn,
|
||||
],
|
||||
)
|
||||
self.chat_control.conversation_rn.submit(
|
||||
self.chat_control.rename_conv,
|
||||
inputs=[
|
||||
self.chat_control.conversation_id,
|
||||
self.chat_control.conversation_rn,
|
||||
gr.State(value=True),
|
||||
self._app.user_id,
|
||||
],
|
||||
outputs=[self.chat_control.conversation, self.chat_control.conversation],
|
||||
outputs=[
|
||||
self.chat_control.conversation,
|
||||
self.chat_control.conversation,
|
||||
self.chat_control.conversation_rn,
|
||||
],
|
||||
show_progress="hidden",
|
||||
)
|
||||
|
||||
self.chat_control.conversation.select(
|
||||
self.chat_control.select_conv,
|
||||
inputs=[self.chat_control.conversation],
|
||||
inputs=[self.chat_control.conversation, self._app.user_id],
|
||||
outputs=[
|
||||
self.chat_control.conversation_id,
|
||||
self.chat_control.conversation,
|
||||
self.chat_control.conversation_rn,
|
||||
self.chat_panel.chatbot,
|
||||
self.info_panel,
|
||||
self.chat_state,
|
||||
self.state_plot_panel,
|
||||
self.state_retrieval_history,
|
||||
self.state_plot_history,
|
||||
self.chat_control.cb_is_public,
|
||||
self.state_chat,
|
||||
]
|
||||
+ self._indices_input,
|
||||
show_progress="hidden",
|
||||
).then(
|
||||
fn=self._json_to_plot,
|
||||
inputs=self.state_plot_panel,
|
||||
outputs=self.plot_panel,
|
||||
).then(
|
||||
lambda: self.toggle_delete(""),
|
||||
outputs=[self.chat_control._new_delete, self.chat_control._delete_confirm],
|
||||
).then(
|
||||
fn=None, inputs=None, outputs=None, js=pdfview_js
|
||||
)
|
||||
|
||||
# evidence display on message selection
|
||||
self.chat_panel.chatbot.select(
|
||||
self.message_selected,
|
||||
inputs=[
|
||||
self.state_retrieval_history,
|
||||
self.state_plot_history,
|
||||
],
|
||||
outputs=[
|
||||
self.info_panel,
|
||||
self.state_plot_panel,
|
||||
],
|
||||
).then(
|
||||
fn=self._json_to_plot,
|
||||
inputs=self.state_plot_panel,
|
||||
outputs=self.plot_panel,
|
||||
).then(
|
||||
fn=None, inputs=None, outputs=None, js=pdfview_js
|
||||
)
|
||||
|
||||
self.chat_control.cb_is_public.change(
|
||||
self.on_set_public_conversation,
|
||||
inputs=[self.chat_control.cb_is_public, self.chat_control.conversation],
|
||||
outputs=None,
|
||||
show_progress="hidden",
|
||||
)
|
||||
|
||||
self.report_issue.report_btn.click(
|
||||
|
|
@ -247,11 +505,26 @@ class ChatPage(BasePage):
|
|||
self._app.settings_state,
|
||||
self._app.user_id,
|
||||
self.info_panel,
|
||||
self.chat_state,
|
||||
self.state_chat,
|
||||
]
|
||||
+ self._indices_input,
|
||||
outputs=None,
|
||||
)
|
||||
self.reasoning_types.change(
|
||||
self.reasoning_changed,
|
||||
inputs=[self.reasoning_types],
|
||||
outputs=[self._reasoning_type],
|
||||
)
|
||||
self.model_types.change(
|
||||
lambda x: x,
|
||||
inputs=[self.model_types],
|
||||
outputs=[self._llm_type],
|
||||
)
|
||||
self.chat_control.conversation_id.change(
|
||||
lambda: gr.update(visible=False),
|
||||
outputs=self.plot_panel,
|
||||
)
|
||||
|
||||
if getattr(flowsettings, "KH_FEATURE_CHAT_SUGGESTION", False):
|
||||
self.chat_suggestion.example.select(
|
||||
self.chat_suggestion.select_example,
|
||||
|
|
@ -291,6 +564,28 @@ class ChatPage(BasePage):
|
|||
else:
|
||||
return gr.update(visible=True), gr.update(visible=False)
|
||||
|
||||
def on_set_public_conversation(self, is_public, convo_id):
|
||||
if not convo_id:
|
||||
gr.Warning("No conversation selected")
|
||||
return
|
||||
|
||||
with Session(engine) as session:
|
||||
statement = select(Conversation).where(Conversation.id == convo_id)
|
||||
|
||||
result = session.exec(statement).one()
|
||||
name = result.name
|
||||
|
||||
if result.is_public != is_public:
|
||||
# Only trigger updating when user
|
||||
# select different value from the current
|
||||
result.is_public = is_public
|
||||
session.add(result)
|
||||
session.commit()
|
||||
|
||||
gr.Info(
|
||||
f"Conversation: {name} is {'public' if is_public else 'private'}."
|
||||
)
|
||||
|
||||
def on_subscribe_public_events(self):
|
||||
if self._app.f_user_management:
|
||||
self._app.subscribe_event(
|
||||
|
|
@ -306,25 +601,53 @@ class ChatPage(BasePage):
|
|||
self._app.subscribe_event(
|
||||
name="onSignOut",
|
||||
definition={
|
||||
"fn": lambda: self.chat_control.select_conv(""),
|
||||
"fn": lambda: self.chat_control.select_conv("", None),
|
||||
"outputs": [
|
||||
self.chat_control.conversation_id,
|
||||
self.chat_control.conversation,
|
||||
self.chat_control.conversation_rn,
|
||||
self.chat_panel.chatbot,
|
||||
self.info_panel,
|
||||
self.state_plot_panel,
|
||||
self.state_retrieval_history,
|
||||
self.state_plot_history,
|
||||
self.chat_control.cb_is_public,
|
||||
]
|
||||
+ self._indices_input,
|
||||
"show_progress": "hidden",
|
||||
},
|
||||
)
|
||||
|
||||
def update_data_source(self, convo_id, messages, state, *selecteds):
|
||||
def persist_data_source(
|
||||
self,
|
||||
convo_id,
|
||||
user_id,
|
||||
retrieval_msg,
|
||||
plot_data,
|
||||
retrival_history,
|
||||
plot_history,
|
||||
messages,
|
||||
state,
|
||||
*selecteds,
|
||||
):
|
||||
"""Update the data source"""
|
||||
if not convo_id:
|
||||
gr.Warning("No conversation selected")
|
||||
return
|
||||
|
||||
# if not regen, then append the new message
|
||||
if not state["app"].get("regen", False):
|
||||
retrival_history = retrival_history + [retrieval_msg]
|
||||
plot_history = plot_history + [plot_data]
|
||||
else:
|
||||
if retrival_history:
|
||||
print("Updating retrieval history (regen=True)")
|
||||
retrival_history[-1] = retrieval_msg
|
||||
plot_history[-1] = plot_data
|
||||
|
||||
# reset regen state
|
||||
state["app"]["regen"] = False
|
||||
|
||||
selecteds_ = {}
|
||||
for index in self._app.index_manager.indices:
|
||||
if index.selector is None:
|
||||
|
|
@ -339,15 +662,29 @@ class ChatPage(BasePage):
|
|||
result = session.exec(statement).one()
|
||||
|
||||
data_source = result.data_source
|
||||
old_selecteds = data_source.get("selected", {})
|
||||
is_owner = result.user == user_id
|
||||
|
||||
# Write down to db
|
||||
result.data_source = {
|
||||
"selected": selecteds_,
|
||||
"selected": selecteds_ if is_owner else old_selecteds,
|
||||
"messages": messages,
|
||||
"retrieval_messages": retrival_history,
|
||||
"plot_history": plot_history,
|
||||
"state": state,
|
||||
"likes": deepcopy(data_source.get("likes", [])),
|
||||
}
|
||||
session.add(result)
|
||||
session.commit()
|
||||
|
||||
return retrival_history, plot_history
|
||||
|
||||
def reasoning_changed(self, reasoning_type):
|
||||
if reasoning_type != DEFAULT_SETTING:
|
||||
# override app settings state (temporary)
|
||||
gr.Info("Reasoning type changed to `{}`".format(reasoning_type))
|
||||
return reasoning_type
|
||||
|
||||
def is_liked(self, convo_id, liked: gr.LikeData):
|
||||
with Session(engine) as session:
|
||||
statement = select(Conversation).where(Conversation.id == convo_id)
|
||||
|
|
@ -362,7 +699,19 @@ class ChatPage(BasePage):
|
|||
session.add(result)
|
||||
session.commit()
|
||||
|
||||
def create_pipeline(self, settings: dict, state: dict, user_id: int, *selecteds):
|
||||
def message_selected(self, retrieval_history, plot_history, msg: gr.SelectData):
|
||||
index = msg.index[0]
|
||||
return retrieval_history[index], plot_history[index]
|
||||
|
||||
def create_pipeline(
|
||||
self,
|
||||
settings: dict,
|
||||
session_reasoning_type: str,
|
||||
session_llm: str,
|
||||
state: dict,
|
||||
user_id: int,
|
||||
*selecteds,
|
||||
):
|
||||
"""Create the pipeline from settings
|
||||
|
||||
Args:
|
||||
|
|
@ -374,10 +723,23 @@ class ChatPage(BasePage):
|
|||
Returns:
|
||||
- the pipeline objects
|
||||
"""
|
||||
reasoning_mode = settings["reasoning.use"]
|
||||
# override reasoning_mode by temporary chat page state
|
||||
print("Session reasoning type", session_reasoning_type)
|
||||
print("Session LLM", session_llm)
|
||||
reasoning_mode = (
|
||||
settings["reasoning.use"]
|
||||
if session_reasoning_type in (DEFAULT_SETTING, None)
|
||||
else session_reasoning_type
|
||||
)
|
||||
reasoning_cls = reasonings[reasoning_mode]
|
||||
print("Reasoning class", reasoning_cls)
|
||||
reasoning_id = reasoning_cls.get_info()["id"]
|
||||
|
||||
settings = deepcopy(settings)
|
||||
llm_setting_key = f"reasoning.options.{reasoning_id}.llm"
|
||||
if llm_setting_key in settings and session_llm not in (DEFAULT_SETTING, None):
|
||||
settings[llm_setting_key] = session_llm
|
||||
|
||||
# get retrievers
|
||||
retrievers = []
|
||||
for index in self._app.index_manager.indices:
|
||||
|
|
@ -403,7 +765,15 @@ class ChatPage(BasePage):
|
|||
return pipeline, reasoning_state
|
||||
|
||||
def chat_fn(
|
||||
self, conversation_id, chat_history, settings, state, user_id, *selecteds
|
||||
self,
|
||||
conversation_id,
|
||||
chat_history,
|
||||
settings,
|
||||
reasoning_type,
|
||||
llm_type,
|
||||
state,
|
||||
user_id,
|
||||
*selecteds,
|
||||
):
|
||||
"""Chat function"""
|
||||
chat_input = chat_history[-1][0]
|
||||
|
|
@ -413,18 +783,23 @@ class ChatPage(BasePage):
|
|||
|
||||
# construct the pipeline
|
||||
pipeline, reasoning_state = self.create_pipeline(
|
||||
settings, state, user_id, *selecteds
|
||||
settings, reasoning_type, llm_type, state, user_id, *selecteds
|
||||
)
|
||||
print("Reasoning state", reasoning_state)
|
||||
pipeline.set_output_queue(queue)
|
||||
|
||||
text, refs = "", ""
|
||||
text, refs, plot, plot_gr = "", "", None, gr.update(visible=False)
|
||||
msg_placeholder = getattr(
|
||||
flowsettings, "KH_CHAT_MSG_PLACEHOLDER", "Thinking ..."
|
||||
)
|
||||
print(msg_placeholder)
|
||||
yield chat_history + [(chat_input, text or msg_placeholder)], refs, state
|
||||
|
||||
len_ref = -1 # for logging purpose
|
||||
yield (
|
||||
chat_history + [(chat_input, text or msg_placeholder)],
|
||||
refs,
|
||||
plot_gr,
|
||||
plot,
|
||||
state,
|
||||
)
|
||||
|
||||
for response in pipeline.stream(chat_input, conversation_id, chat_history):
|
||||
|
||||
|
|
@ -446,22 +821,42 @@ class ChatPage(BasePage):
|
|||
else:
|
||||
refs += response.content
|
||||
|
||||
if len(refs) > len_ref:
|
||||
print(f"Len refs: {len(refs)}")
|
||||
len_ref = len(refs)
|
||||
if response.channel == "plot":
|
||||
plot = response.content
|
||||
plot_gr = self._json_to_plot(plot)
|
||||
|
||||
state[pipeline.get_info()["id"]] = reasoning_state["pipeline"]
|
||||
yield chat_history + [(chat_input, text or msg_placeholder)], refs, state
|
||||
yield (
|
||||
chat_history + [(chat_input, text or msg_placeholder)],
|
||||
refs,
|
||||
plot_gr,
|
||||
plot,
|
||||
state,
|
||||
)
|
||||
|
||||
if not text:
|
||||
empty_msg = getattr(
|
||||
flowsettings, "KH_CHAT_EMPTY_MSG_PLACEHOLDER", "(Sorry, I don't know)"
|
||||
)
|
||||
print(f"Generate nothing: {empty_msg}")
|
||||
yield chat_history + [(chat_input, text or empty_msg)], refs, state
|
||||
yield (
|
||||
chat_history + [(chat_input, text or empty_msg)],
|
||||
refs,
|
||||
plot_gr,
|
||||
plot,
|
||||
state,
|
||||
)
|
||||
|
||||
def regen_fn(
|
||||
self, conversation_id, chat_history, settings, state, user_id, *selecteds
|
||||
self,
|
||||
conversation_id,
|
||||
chat_history,
|
||||
settings,
|
||||
reasoning_type,
|
||||
llm_type,
|
||||
state,
|
||||
user_id,
|
||||
*selecteds,
|
||||
):
|
||||
"""Regen function"""
|
||||
if not chat_history:
|
||||
|
|
@ -470,11 +865,119 @@ class ChatPage(BasePage):
|
|||
return
|
||||
|
||||
state["app"]["regen"] = True
|
||||
for chat, refs, state in self.chat_fn(
|
||||
conversation_id, chat_history, settings, state, user_id, *selecteds
|
||||
):
|
||||
new_state = deepcopy(state)
|
||||
new_state["app"]["regen"] = False
|
||||
yield chat, refs, new_state
|
||||
yield from self.chat_fn(
|
||||
conversation_id,
|
||||
chat_history,
|
||||
settings,
|
||||
reasoning_type,
|
||||
llm_type,
|
||||
state,
|
||||
user_id,
|
||||
*selecteds,
|
||||
)
|
||||
|
||||
state["app"]["regen"] = False
|
||||
def check_and_suggest_name_conv(self, chat_history):
|
||||
suggest_pipeline = SuggestConvNamePipeline()
|
||||
new_name = gr.update()
|
||||
renamed = False
|
||||
|
||||
# check if this is a newly created conversation
|
||||
if len(chat_history) == 1:
|
||||
suggested_name = suggest_pipeline(chat_history).text[:40]
|
||||
new_name = gr.update(value=suggested_name)
|
||||
renamed = True
|
||||
|
||||
return new_name, renamed
|
||||
|
||||
def backup_original_info(
|
||||
self, chat_history, settings, info_pannel, original_chat_history
|
||||
):
|
||||
original_chat_history.append(chat_history[-1])
|
||||
return original_chat_history, settings, info_pannel
|
||||
|
||||
def save_log(
|
||||
self,
|
||||
conversation_id,
|
||||
chat_history,
|
||||
settings,
|
||||
info_panel,
|
||||
original_chat_history,
|
||||
original_settings,
|
||||
original_info_panel,
|
||||
log_dir,
|
||||
):
|
||||
if not Path(log_dir).exists():
|
||||
Path(log_dir).mkdir(parents=True)
|
||||
|
||||
lock = FileLock(Path(log_dir) / ".lock")
|
||||
# get current date
|
||||
today = datetime.now()
|
||||
formatted_date = today.strftime("%d%m%Y_%H")
|
||||
|
||||
with Session(engine) as session:
|
||||
statement = select(Conversation).where(Conversation.id == conversation_id)
|
||||
result = session.exec(statement).one()
|
||||
|
||||
data_source = deepcopy(result.data_source)
|
||||
likes = data_source.get("likes", [])
|
||||
if not likes:
|
||||
return
|
||||
|
||||
feedback = likes[-1][-1]
|
||||
message_index = likes[-1][0]
|
||||
|
||||
current_message = chat_history[message_index[0]]
|
||||
original_message = original_chat_history[message_index[0]]
|
||||
is_original = all(
|
||||
[
|
||||
current_item == original_item
|
||||
for current_item, original_item in zip(
|
||||
current_message, original_message
|
||||
)
|
||||
]
|
||||
)
|
||||
|
||||
dataframe = [
|
||||
[
|
||||
conversation_id,
|
||||
message_index,
|
||||
current_message[0],
|
||||
current_message[1],
|
||||
chat_history,
|
||||
settings,
|
||||
info_panel,
|
||||
feedback,
|
||||
is_original,
|
||||
original_message[1],
|
||||
original_chat_history,
|
||||
original_settings,
|
||||
original_info_panel,
|
||||
]
|
||||
]
|
||||
|
||||
with lock:
|
||||
log_file = Path(log_dir) / f"{formatted_date}_log.csv"
|
||||
is_log_file_exist = log_file.is_file()
|
||||
with open(log_file, "a") as f:
|
||||
writer = csv.writer(f)
|
||||
# write headers
|
||||
if not is_log_file_exist:
|
||||
writer.writerow(
|
||||
[
|
||||
"Conversation ID",
|
||||
"Message ID",
|
||||
"Question",
|
||||
"Answer",
|
||||
"Chat History",
|
||||
"Settings",
|
||||
"Evidences",
|
||||
"Feedback",
|
||||
"Original/ Rewritten",
|
||||
"Original Answer",
|
||||
"Original Chat History",
|
||||
"Original Settings",
|
||||
"Original Evidences",
|
||||
]
|
||||
)
|
||||
|
||||
writer.writerows(dataframe)
|
||||
|
|
|
|||
|
|
@ -1,13 +1,20 @@
|
|||
import logging
|
||||
import os
|
||||
|
||||
import gradio as gr
|
||||
from ktem.app import BasePage
|
||||
from ktem.db.models import Conversation, engine
|
||||
from sqlmodel import Session, select
|
||||
from ktem.db.models import Conversation, User, engine
|
||||
from sqlmodel import Session, or_, select
|
||||
|
||||
import flowsettings
|
||||
|
||||
from ...utils.conversation import sync_retrieval_n_message
|
||||
from .common import STATE
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
ASSETS_DIR = "assets/icons"
|
||||
if not os.path.isdir(ASSETS_DIR):
|
||||
ASSETS_DIR = "libs/ktem/ktem/assets/icons"
|
||||
|
||||
|
||||
def is_conv_name_valid(name):
|
||||
|
|
@ -35,14 +42,47 @@ class ConversationControl(BasePage):
|
|||
label="Chat sessions",
|
||||
choices=[],
|
||||
container=False,
|
||||
filterable=False,
|
||||
filterable=True,
|
||||
interactive=True,
|
||||
elem_classes=["unset-overflow"],
|
||||
)
|
||||
|
||||
with gr.Row() as self._new_delete:
|
||||
self.btn_new = gr.Button(value="New", min_width=10, variant="primary")
|
||||
self.btn_del = gr.Button(value="Delete", min_width=10, variant="stop")
|
||||
self.btn_new = gr.Button(
|
||||
value="",
|
||||
icon=f"{ASSETS_DIR}/new.svg",
|
||||
min_width=2,
|
||||
scale=1,
|
||||
size="sm",
|
||||
elem_classes=["no-background", "body-text-color"],
|
||||
)
|
||||
self.btn_del = gr.Button(
|
||||
value="",
|
||||
icon=f"{ASSETS_DIR}/delete.svg",
|
||||
min_width=2,
|
||||
scale=1,
|
||||
size="sm",
|
||||
elem_classes=["no-background", "body-text-color"],
|
||||
)
|
||||
self.btn_conversation_rn = gr.Button(
|
||||
value="",
|
||||
icon=f"{ASSETS_DIR}/rename.svg",
|
||||
min_width=2,
|
||||
scale=1,
|
||||
size="sm",
|
||||
elem_classes=["no-background", "body-text-color"],
|
||||
)
|
||||
self.btn_info_expand = gr.Button(
|
||||
value="",
|
||||
icon=f"{ASSETS_DIR}/sidebar.svg",
|
||||
min_width=2,
|
||||
scale=1,
|
||||
size="sm",
|
||||
elem_classes=["no-background", "body-text-color"],
|
||||
)
|
||||
self.cb_is_public = gr.Checkbox(
|
||||
value=False, label="Shared", min_width=10, scale=4
|
||||
)
|
||||
|
||||
with gr.Row(visible=False) as self._delete_confirm:
|
||||
self.btn_del_conf = gr.Button(
|
||||
|
|
@ -54,28 +94,60 @@ class ConversationControl(BasePage):
|
|||
|
||||
with gr.Row():
|
||||
self.conversation_rn = gr.Text(
|
||||
label="(Enter) to save",
|
||||
placeholder="Conversation name",
|
||||
container=False,
|
||||
container=True,
|
||||
scale=5,
|
||||
min_width=10,
|
||||
interactive=True,
|
||||
)
|
||||
self.conversation_rn_btn = gr.Button(
|
||||
value="Rename",
|
||||
scale=1,
|
||||
min_width=10,
|
||||
elem_classes=["no-background", "body-text-color", "bold-text"],
|
||||
visible=False,
|
||||
)
|
||||
|
||||
def load_chat_history(self, user_id):
|
||||
"""Reload chat history"""
|
||||
|
||||
# In case user are admin. They can also watch the
|
||||
# public conversations
|
||||
can_see_public: bool = False
|
||||
with Session(engine) as session:
|
||||
statement = select(User).where(User.id == user_id)
|
||||
result = session.exec(statement).one_or_none()
|
||||
|
||||
if result is not None:
|
||||
if flowsettings.KH_USER_CAN_SEE_PUBLIC:
|
||||
can_see_public = (
|
||||
result.username == flowsettings.KH_USER_CAN_SEE_PUBLIC
|
||||
)
|
||||
else:
|
||||
can_see_public = True
|
||||
|
||||
print(f"User-id: {user_id}, can see public conversations: {can_see_public}")
|
||||
|
||||
options = []
|
||||
with Session(engine) as session:
|
||||
# Define condition based on admin-role:
|
||||
# - can_see: can see their conversations & public files
|
||||
# - can_not_see: only see their conversations
|
||||
if can_see_public:
|
||||
statement = (
|
||||
select(Conversation)
|
||||
.where(
|
||||
or_(
|
||||
Conversation.user == user_id,
|
||||
Conversation.is_public,
|
||||
)
|
||||
)
|
||||
.order_by(
|
||||
Conversation.is_public.desc(), Conversation.date_created.desc()
|
||||
) # type: ignore
|
||||
)
|
||||
else:
|
||||
statement = (
|
||||
select(Conversation)
|
||||
.where(Conversation.user == user_id)
|
||||
.order_by(Conversation.date_created.desc()) # type: ignore
|
||||
)
|
||||
|
||||
results = session.exec(statement).all()
|
||||
for result in results:
|
||||
options.append((result.name, result.id))
|
||||
|
|
@ -129,7 +201,7 @@ class ConversationControl(BasePage):
|
|||
else:
|
||||
return None, gr.update(value=None, choices=[])
|
||||
|
||||
def select_conv(self, conversation_id):
|
||||
def select_conv(self, conversation_id, user_id):
|
||||
"""Select the conversation"""
|
||||
with Session(engine) as session:
|
||||
statement = select(Conversation).where(Conversation.id == conversation_id)
|
||||
|
|
@ -137,18 +209,46 @@ class ConversationControl(BasePage):
|
|||
result = session.exec(statement).one()
|
||||
id_ = result.id
|
||||
name = result.name
|
||||
is_conv_public = result.is_public
|
||||
|
||||
# disable file selection ids state if
|
||||
# not the owner of the conversation
|
||||
if user_id == result.user:
|
||||
selected = result.data_source.get("selected", {})
|
||||
else:
|
||||
selected = {}
|
||||
|
||||
chats = result.data_source.get("messages", [])
|
||||
info_panel = ""
|
||||
|
||||
retrieval_history: list[str] = result.data_source.get(
|
||||
"retrieval_messages", []
|
||||
)
|
||||
plot_history: list[dict] = result.data_source.get("plot_history", [])
|
||||
|
||||
# On initialization
|
||||
# Ensure len of retrieval and messages are equal
|
||||
retrieval_history = sync_retrieval_n_message(chats, retrieval_history)
|
||||
|
||||
info_panel = (
|
||||
retrieval_history[-1]
|
||||
if retrieval_history
|
||||
else "<h5><b>No evidence found.</b></h5>"
|
||||
)
|
||||
plot_data = plot_history[-1] if plot_history else None
|
||||
state = result.data_source.get("state", STATE)
|
||||
|
||||
except Exception as e:
|
||||
logger.warning(e)
|
||||
id_ = ""
|
||||
name = ""
|
||||
selected = {}
|
||||
chats = []
|
||||
retrieval_history = []
|
||||
plot_history = []
|
||||
info_panel = ""
|
||||
plot_data = None
|
||||
state = STATE
|
||||
is_conv_public = False
|
||||
|
||||
indices = []
|
||||
for index in self._app.index_manager.indices:
|
||||
|
|
@ -160,10 +260,29 @@ class ConversationControl(BasePage):
|
|||
if isinstance(index.selector, tuple):
|
||||
indices.extend(selected.get(str(index.id), index.default_selector))
|
||||
|
||||
return id_, id_, name, chats, info_panel, state, *indices
|
||||
return (
|
||||
id_,
|
||||
id_,
|
||||
name,
|
||||
chats,
|
||||
info_panel,
|
||||
plot_data,
|
||||
retrieval_history,
|
||||
plot_history,
|
||||
is_conv_public,
|
||||
state,
|
||||
*indices,
|
||||
)
|
||||
|
||||
def rename_conv(self, conversation_id, new_name, user_id):
|
||||
def rename_conv(self, conversation_id, new_name, is_renamed, user_id):
|
||||
"""Rename the conversation"""
|
||||
if not is_renamed:
|
||||
return (
|
||||
gr.update(),
|
||||
conversation_id,
|
||||
gr.update(visible=False),
|
||||
)
|
||||
|
||||
if user_id is None:
|
||||
gr.Warning("Please sign in first (Settings → User Settings)")
|
||||
return gr.update(), ""
|
||||
|
|
@ -185,7 +304,12 @@ class ConversationControl(BasePage):
|
|||
session.commit()
|
||||
|
||||
history = self.load_chat_history(user_id)
|
||||
return gr.update(choices=history), conversation_id
|
||||
gr.Info("Conversation renamed.")
|
||||
return (
|
||||
gr.update(choices=history),
|
||||
conversation_id,
|
||||
gr.update(visible=False),
|
||||
)
|
||||
|
||||
def _on_app_created(self):
|
||||
"""Reload the conversation once the app is created"""
|
||||
|
|
|
|||
|
|
@ -12,7 +12,7 @@ class ReportIssue(BasePage):
|
|||
self.on_building_ui()
|
||||
|
||||
def on_building_ui(self):
|
||||
with gr.Accordion(label="Report", open=False):
|
||||
with gr.Accordion(label="Feedback", open=False):
|
||||
self.correctness = gr.Radio(
|
||||
choices=[
|
||||
("The answer is correct", "correct"),
|
||||
|
|
|
|||
|
|
@ -9,6 +9,7 @@ from theflow.settings import settings
|
|||
def get_remote_doc(url: str) -> str:
|
||||
try:
|
||||
res = requests.get(url)
|
||||
res.raise_for_status()
|
||||
return res.text
|
||||
except Exception as e:
|
||||
print(f"Failed to fetch document from {url}: {e}")
|
||||
|
|
|
|||