Improve manuals (#19)
* Rename Admin -> Resources * Improve ui * Update docs
@@ -1,4 +1,6 @@
|
|||||||
# Package overview
|
# Contributing
|
||||||
|
|
||||||
|
## Package overview
|
||||||
|
|
||||||
`kotaemon` library focuses on the AI building blocks to implement a RAG-based QA application. It consists of base interfaces, core components and a list of utilities:
|
`kotaemon` library focuses on the AI building blocks to implement a RAG-based QA application. It consists of base interfaces, core components and a list of utilities:
|
||||||
|
|
||||||
@@ -47,14 +49,14 @@ mindmap
|
|||||||
Documentation Support
|
Documentation Support
|
||||||
```
|
```
|
||||||
|
|
||||||
# Common conventions
|
## Common conventions
|
||||||
|
|
||||||
- PR title: One-line description (example: Feat: Declare BaseComponent and decide LLM call interface).
|
- PR title: One-line description (example: Feat: Declare BaseComponent and decide LLM call interface).
|
||||||
- [Encouraged] Provide a quick description in the PR, so that:
|
- [Encouraged] Provide a quick description in the PR, so that:
|
||||||
- Reviewers can quickly understand the direction of the PR.
|
- Reviewers can quickly understand the direction of the PR.
|
||||||
- It will be included in the commit message when the PR is merged.
|
- It will be included in the commit message when the PR is merged.
|
||||||
|
|
||||||
# Environment caching on PR
|
## Environment caching on PR
|
||||||
|
|
||||||
- To speed up CI, environments are cached based on the version specified in `__init__.py`.
|
- To speed up CI, environments are cached based on the version specified in `__init__.py`.
|
||||||
- Since dependencies versions in `setup.py` are not pinned, you need to pump the version in order to use a new environment. That environment will then be cached and used by your subsequence commits within the PR, until you pump the version again
|
- Since dependencies versions in `setup.py` are not pinned, you need to pump the version in order to use a new environment. That environment will then be cached and used by your subsequence commits within the PR, until you pump the version again
|
||||||
@@ -65,7 +67,7 @@ mindmap
|
|||||||
- When you want to run the CI, push a commit with the message containing `[ignore cache]`.
|
- When you want to run the CI, push a commit with the message containing `[ignore cache]`.
|
||||||
- Once the PR is final, pump the version in `__init__.py` and push a final commit not containing `[ignore cache]`.
|
- Once the PR is final, pump the version in `__init__.py` and push a final commit not containing `[ignore cache]`.
|
||||||
|
|
||||||
# Merge PR guideline
|
## Merge PR guideline
|
||||||
|
|
||||||
- Use squash and merge option
|
- Use squash and merge option
|
||||||
- 1st line message is the PR title.
|
- 1st line message is the PR title.
|
||||||
|
|||||||
@@ -1,10 +1,12 @@
|
|||||||
|
# Data & Data Structure Components
|
||||||
|
|
||||||
The data & data structure components include:
|
The data & data structure components include:
|
||||||
|
|
||||||
- The `Document` class.
|
- The `Document` class.
|
||||||
- The document store.
|
- The document store.
|
||||||
- The vector store.
|
- The vector store.
|
||||||
|
|
||||||
### Data Loader
|
## Data Loader
|
||||||
|
|
||||||
- PdfLoader
|
- PdfLoader
|
||||||
- Layout-aware with table parsing PdfLoader
|
- Layout-aware with table parsing PdfLoader
|
||||||
@@ -22,11 +24,11 @@ The data & data structure components include:
|
|||||||
- "page_label": page number in the original PDF document
|
- "page_label": page number in the original PDF document
|
||||||
```
|
```
|
||||||
|
|
||||||
### Document Store
|
## Document Store
|
||||||
|
|
||||||
- InMemoryDocumentStore
|
- InMemoryDocumentStore
|
||||||
|
|
||||||
### Vector Store
|
## Vector Store
|
||||||
|
|
||||||
- ChromaVectorStore
|
- ChromaVectorStore
|
||||||
- InMemoryVectorStore
|
- InMemoryVectorStore
|
||||||
|
|||||||
@@ -1,4 +1,4 @@
|
|||||||
Utilities detail can be referred in the sub-pages of this section.
|
# Utilities
|
||||||
|
|
||||||
## Prompt engineering UI
|
## Prompt engineering UI
|
||||||
|
|
||||||
@@ -36,7 +36,7 @@ done by the developers, while step 7 happens exclusively in Excel file).
|
|||||||
|
|
||||||
Command:
|
Command:
|
||||||
|
|
||||||
```
|
```shell
|
||||||
$ kotaemon promptui export <module.path.piplineclass> --output <path/to/config/file.yml>
|
$ kotaemon promptui export <module.path.piplineclass> --output <path/to/config/file.yml>
|
||||||
```
|
```
|
||||||
|
|
||||||
@@ -59,38 +59,32 @@ Declared as above, and `param1` will show up in the config YAML file, while `par
|
|||||||
|
|
||||||
developers can further edit the config file in this step to get the most suitable UI (step 4) with their tasks. The exported config will have this overall schema:
|
developers can further edit the config file in this step to get the most suitable UI (step 4) with their tasks. The exported config will have this overall schema:
|
||||||
|
|
||||||
```
|
```yml
|
||||||
<module.path.pipelineclass1>:
|
<module.path.pipelineclass1>:
|
||||||
params:
|
params: ... (Detail param information to initiate a pipeline. This corresponds to the pipeline init parameters.)
|
||||||
... (Detail param information to initiate a pipeline. This corresponds to the pipeline init parameters.)
|
inputs: ... (Detail the input of the pipeline e.g. a text prompt. This corresponds to the params of `run(...)` method.)
|
||||||
inputs:
|
outputs: ... (Detail the output of the pipeline e.g. prediction, accuracy... This is the output information we wish to see in the UI.)
|
||||||
... (Detail the input of the pipeline e.g. a text prompt. This corresponds to the params of `run(...)` method.)
|
logs: ... (Detail what information should show up in the log.)
|
||||||
outputs:
|
|
||||||
... (Detail the output of the pipeline e.g. prediction, accuracy... This is the output information we wish to see in the UI.)
|
|
||||||
logs:
|
|
||||||
... (Detail what information should show up in the log.)
|
|
||||||
```
|
```
|
||||||
|
|
||||||
##### Input and params
|
##### Input and params
|
||||||
|
|
||||||
The inputs section have the overall schema as follow:
|
The inputs section have the overall schema as follow:
|
||||||
|
|
||||||
```
|
```yml
|
||||||
inputs:
|
inputs:
|
||||||
<input-variable-name-1>:
|
<input-variable-name-1>:
|
||||||
component: <supported-UI-component>
|
component: <supported-UI-component>
|
||||||
params: # this section is optional)
|
params: # this section is optional)
|
||||||
value: <default-value>
|
value: <default-value>
|
||||||
<input-variable-name-2>:
|
<input-variable-name-2>: ... # similar to above
|
||||||
... # similar to above
|
|
||||||
params:
|
params:
|
||||||
<param-variable-name-1>:
|
<param-variable-name-1>: ... # similar to those in the inputs
|
||||||
... # similar to those in the inputs
|
|
||||||
```
|
```
|
||||||
|
|
||||||
The list of supported prompt UI and their corresponding gradio UI components:
|
The list of supported prompt UI and their corresponding gradio UI components:
|
||||||
|
|
||||||
```
|
```python
|
||||||
COMPONENTS_CLASS = {
|
COMPONENTS_CLASS = {
|
||||||
"text": gr.components.Textbox,
|
"text": gr.components.Textbox,
|
||||||
"checkbox": gr.components.CheckboxGroup,
|
"checkbox": gr.components.CheckboxGroup,
|
||||||
@@ -107,7 +101,7 @@ COMPONENTS_CLASS = {
|
|||||||
|
|
||||||
The outputs are a list of variables that we wish to show in the UI. Since in Python, the function output doesn't have variable name, so output declaration is a little bit different than input and param declaration:
|
The outputs are a list of variables that we wish to show in the UI. Since in Python, the function output doesn't have variable name, so output declaration is a little bit different than input and param declaration:
|
||||||
|
|
||||||
```
|
```yml
|
||||||
outputs:
|
outputs:
|
||||||
- component: <supported-UI-component>
|
- component: <supported-UI-component>
|
||||||
step: <name-of-pipeline-step>
|
step: <name-of-pipeline-step>
|
||||||
@@ -125,7 +119,7 @@ where:
|
|||||||
|
|
||||||
The logs show a list of sheetname and how to retrieve the desired information.
|
The logs show a list of sheetname and how to retrieve the desired information.
|
||||||
|
|
||||||
```
|
```yml
|
||||||
logs:
|
logs:
|
||||||
<logname>:
|
<logname>:
|
||||||
inputs:
|
inputs:
|
||||||
@@ -143,7 +137,7 @@ logs:
|
|||||||
|
|
||||||
Command:
|
Command:
|
||||||
|
|
||||||
```
|
```shell
|
||||||
$ kotaemon promptui run <path/to/config/file.yml>
|
$ kotaemon promptui run <path/to/config/file.yml>
|
||||||
```
|
```
|
||||||
|
|
||||||
|
|||||||
{kind=link}
|
Before Width: | Height: | Size: 19 KiB |
{kind=link}
|
Before Width: | Height: | Size: 67 KiB After Width: | Height: | Size: 52 KiB |
{kind=link}
|
Before Width: | Height: | Size: 7.9 KiB |
{kind=link}
|
Before Width: | Height: | Size: 42 KiB After Width: | Height: | Size: 65 KiB |
{kind=link}
|
Before Width: | Height: | Size: 6.0 KiB |
{kind=link}
|
Before Width: | Height: | Size: 22 KiB |
{kind=link}
|
Before Width: | Height: | Size: 17 KiB |
{kind=link}
|
Before Width: | Height: | Size: 9.9 KiB |
BIN
docs/images/resources-tab.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 236 KiB |
{kind=link}
|
Before Width: | Height: | Size: 27 KiB |
@@ -7,90 +7,6 @@ This page is intended for end users who want to use the `kotaemon` tool for Ques
|
|||||||
Download and upzip the latest version of `kotaemon` by clicking this
|
Download and upzip the latest version of `kotaemon` by clicking this
|
||||||
[link](https://github.com/Cinnamon/kotaemon/archive/refs/heads/main.zip).
|
[link](https://github.com/Cinnamon/kotaemon/archive/refs/heads/main.zip).
|
||||||
|
|
||||||
## Choose what model to use
|
|
||||||
|
|
||||||
The tool uses Large Language Model (LLMs) to perform various tasks in a QA pipeline. So
|
|
||||||
prior to running, you need to provide the application with access to the LLMs you want
|
|
||||||
to use.
|
|
||||||
|
|
||||||
Please edit the `.env` file with the information needed to connect to the LLMs. You only
|
|
||||||
need to provide at least one. However, tt is recommended that you include all the LLMs
|
|
||||||
that you have access to, you will be able to switch between them while using the
|
|
||||||
application.
|
|
||||||
|
|
||||||
Currently, the following providers are supported:
|
|
||||||
|
|
||||||
### OpenAI
|
|
||||||
|
|
||||||
In the `.env` file, set the `OPENAI_API_KEY` variable with your OpenAI API key in order
|
|
||||||
to enable access to OpenAI's models. There are other variables that can be modified,
|
|
||||||
please feel free to edit them to fit your case. Otherwise, the default parameter should
|
|
||||||
work for most people.
|
|
||||||
|
|
||||||
```shell
|
|
||||||
OPENAI_API_BASE=https://api.openai.com/v1
|
|
||||||
OPENAI_API_KEY=<your OpenAI API key here>
|
|
||||||
OPENAI_CHAT_MODEL=gpt-3.5-turbo
|
|
||||||
OPENAI_EMBEDDINGS_MODEL=text-embedding-ada-002
|
|
||||||
```
|
|
||||||
|
|
||||||
### Azure OpenAI
|
|
||||||
|
|
||||||
For OpenAI models via Azure platform, you need to provide your Azure endpoint and API
|
|
||||||
key. Your might also need to provide your developments' name for the chat model and the
|
|
||||||
embedding model depending on how you set up Azure development.
|
|
||||||
|
|
||||||
```shell
|
|
||||||
AZURE_OPENAI_ENDPOINT=
|
|
||||||
AZURE_OPENAI_API_KEY=
|
|
||||||
OPENAI_API_VERSION=2024-02-15-preview
|
|
||||||
AZURE_OPENAI_CHAT_DEPLOYMENT=gpt-35-turbo
|
|
||||||
AZURE_OPENAI_EMBEDDINGS_DEPLOYMENT=text-embedding-ada-002
|
|
||||||
```
|
|
||||||
|
|
||||||
### Local models
|
|
||||||
|
|
||||||
- Pros:
|
|
||||||
- Privacy. Your documents will be stored and process locally.
|
|
||||||
- Choices. There are a wide range of LLMs in terms of size, domain, language to choose
|
|
||||||
from.
|
|
||||||
- Cost. It's free.
|
|
||||||
- Cons:
|
|
||||||
- Quality. Local models are much smaller and thus have lower generative quality than
|
|
||||||
paid APIs.
|
|
||||||
- Speed. Local models are deployed using your machine so the processing speed is
|
|
||||||
limited by your hardware.
|
|
||||||
|
|
||||||
#### Find and download a LLM
|
|
||||||
|
|
||||||
You can search and download a LLM to be ran locally from the [Hugging Face
|
|
||||||
Hub](https://huggingface.co/models). Currently, these model formats are supported:
|
|
||||||
|
|
||||||
- GGUF
|
|
||||||
|
|
||||||
You should choose a model whose size is less than your device's memory and should leave
|
|
||||||
about 2 GB. For example, if you have 16 GB of RAM in total, of which 12 GB is available,
|
|
||||||
then you should choose a model that take up at most 10 GB of RAM. Bigger models tend to
|
|
||||||
give better generation but also take more processing time.
|
|
||||||
|
|
||||||
Here are some recommendations and their size in memory:
|
|
||||||
|
|
||||||
- [Qwen1.5-1.8B-Chat-GGUF](https://huggingface.co/Qwen/Qwen1.5-1.8B-Chat-GGUF/resolve/main/qwen1_5-1_8b-chat-q8_0.gguf?download=true):
|
|
||||||
around 2 GB
|
|
||||||
|
|
||||||
#### Enable local models
|
|
||||||
|
|
||||||
To add a local model to the model pool, set the `LOCAL_MODEL` variable in the `.env`
|
|
||||||
file to the path of the model file.
|
|
||||||
|
|
||||||
```shell
|
|
||||||
LOCAL_MODEL=<full path to your model file>
|
|
||||||
```
|
|
||||||
|
|
||||||
Here is how to get the full path of your model file:
|
|
||||||
|
|
||||||
- On Windows 11: right click the file and select `Copy as Path`.
|
|
||||||
|
|
||||||
## Installation
|
## Installation
|
||||||
|
|
||||||
1. Navigate to the `scripts` folder and start an installer that matches your OS:
|
1. Navigate to the `scripts` folder and start an installer that matches your OS:
|
||||||
@@ -103,7 +19,7 @@ Here is how to get the full path of your model file:
|
|||||||
- Linux: `run_linux.sh`. If you are using Linux, you would know how to run a bash
|
- Linux: `run_linux.sh`. If you are using Linux, you would know how to run a bash
|
||||||
script, right ?
|
script, right ?
|
||||||
2. After the installation, the installer will ask to launch the ktem's UI, answer to continue.
|
2. After the installation, the installer will ask to launch the ktem's UI, answer to continue.
|
||||||
3. If launched, the application will be available at `http://localhost:7860/`.
|
3. If launched, the application will be open automatically in your browser.
|
||||||
|
|
||||||
## Launch
|
## Launch
|
||||||
|
|
||||||
@@ -111,11 +27,12 @@ To launch the app after initial setup or any changes, simply run the `run_*` scr
|
|||||||
|
|
||||||
A browser window will be opened and greet you with this screen:
|
A browser window will be opened and greet you with this screen:
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
## Usage
|
## Usage
|
||||||
|
|
||||||
For how to use the application, see [Usage](/usage). Have fun !
|
For how to use the application, see [Usage](/usage). This page will also be available to
|
||||||
|
you within the application.
|
||||||
|
|
||||||
## Feedback
|
## Feedback
|
||||||
|
|
||||||
|
|||||||
142
docs/usage.md
@@ -1,59 +1,137 @@
|
|||||||
# Basic Usage
|
# Basic Usage
|
||||||
|
|
||||||
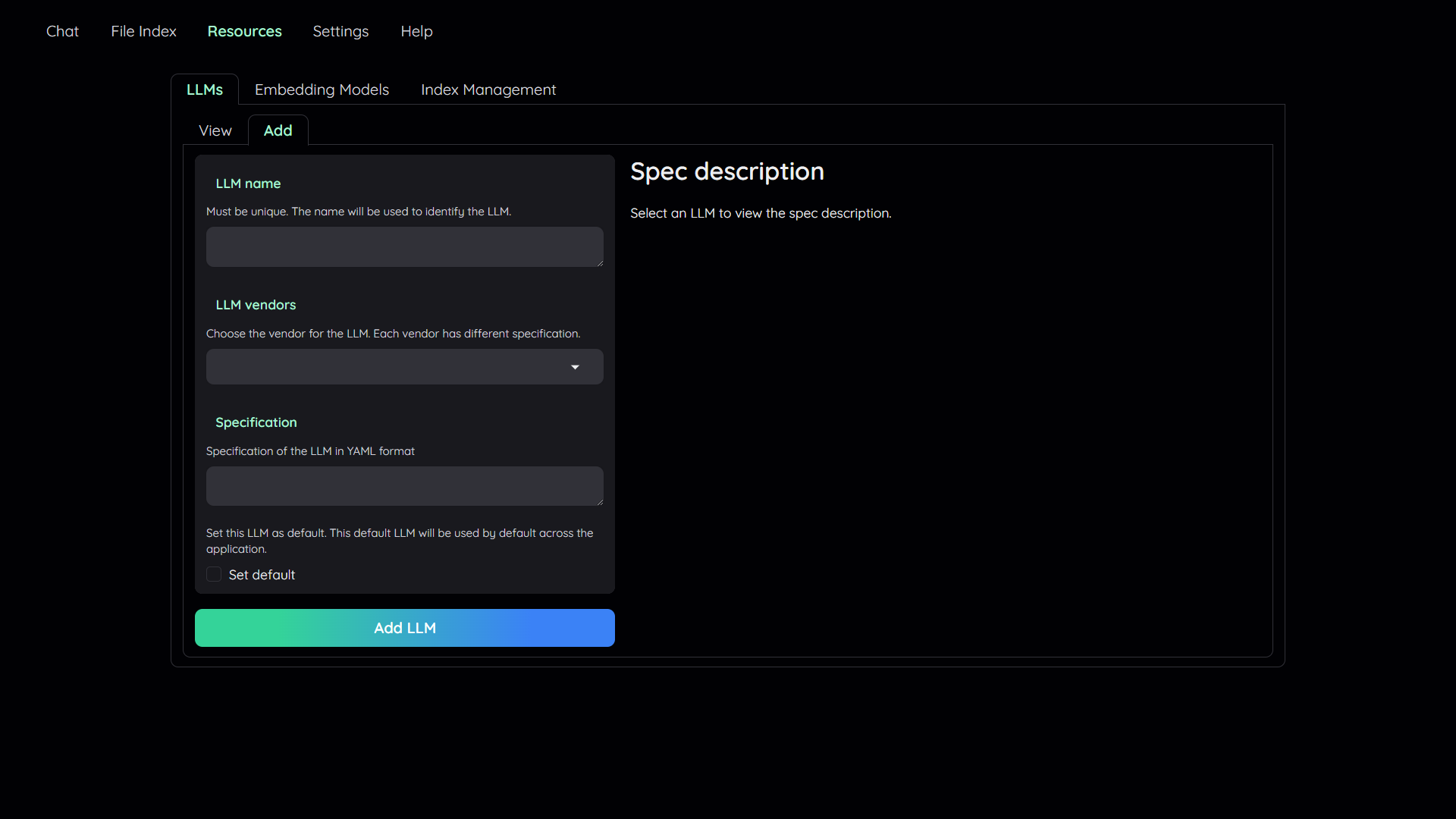
## Chat tab
|
## 1. Add your AI models
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
The chat tab is divided into 3 columns:
|
- The tool uses Large Language Model (LLMs) to perform various tasks in a QA pipeline.
|
||||||
|
So, you need to provide the application with access to the LLMs you want
|
||||||
|
to use.
|
||||||
|
- You only need to provide at least one. However, tt is recommended that you include all the LLMs
|
||||||
|
that you have access to, you will be able to switch between them while using the
|
||||||
|
application.
|
||||||
|
|
||||||
- Left: Conversation settings
|
To add a model:
|
||||||
- Middle: Chat interface
|
|
||||||
- Right: Information panel
|
|
||||||
|
|
||||||
### Conversation settings
|
1. Navigate to the `Resources` tab.
|
||||||
|
2. Select `LLM Management`.
|
||||||
|
3. Select `Add`.
|
||||||
|
4. Config the model to add:
|
||||||
|
- Give it a name.
|
||||||
|
- Pick a vendor/provider (e.g. `ChatOpenAI`).
|
||||||
|
- Provide the specifications.
|
||||||
|
- Optionally, set the model as default.
|
||||||
|
5. Click `Add LLM`.
|
||||||
|
|
||||||
#### Conversation control
|
<details close>
|
||||||
|
|
||||||
Create, rename, and delete conversations.
|
<summary>Configures model via the .env file</summary>
|
||||||
|
|
||||||

|
Alternatively, you can configure the models via the `.env` file with the information needed to connect to the LLMs. This file is located in
|
||||||
|
the folder of the application. If you don't see it, you can create one.
|
||||||
|
|
||||||
#### File index
|
Currently, the following providers are supported:
|
||||||
|
|
||||||
Choose which files to retrieve references from. If no file is selected, all files will be used.
|
### OpenAI
|
||||||
|
|
||||||

|
In the `.env` file, set the `OPENAI_API_KEY` variable with your OpenAI API key in order
|
||||||
|
to enable access to OpenAI's models. There are other variables that can be modified,
|
||||||
|
please feel free to edit them to fit your case. Otherwise, the default parameter should
|
||||||
|
work for most people.
|
||||||
|
|
||||||
### Chat interface
|
```shell
|
||||||
|
OPENAI_API_BASE=https://api.openai.com/v1
|
||||||
|
OPENAI_API_KEY=<your OpenAI API key here>
|
||||||
|
OPENAI_CHAT_MODEL=gpt-3.5-turbo
|
||||||
|
OPENAI_EMBEDDINGS_MODEL=text-embedding-ada-002
|
||||||
|
```
|
||||||
|
|
||||||
Interact with the chatbot.
|
### Azure OpenAI
|
||||||
|
|
||||||

|
For OpenAI models via Azure platform, you need to provide your Azure endpoint and API
|
||||||
|
key. Your might also need to provide your developments' name for the chat model and the
|
||||||
|
embedding model depending on how you set up Azure development.
|
||||||
|
|
||||||
### Information panel
|
```shell
|
||||||
|
AZURE_OPENAI_ENDPOINT=
|
||||||
|
AZURE_OPENAI_API_KEY=
|
||||||
|
OPENAI_API_VERSION=2024-02-15-preview
|
||||||
|
AZURE_OPENAI_CHAT_DEPLOYMENT=gpt-35-turbo
|
||||||
|
AZURE_OPENAI_EMBEDDINGS_DEPLOYMENT=text-embedding-ada-002
|
||||||
|
```
|
||||||
|
|
||||||
Supporting information such as the retrieved evidence and reference will be displayed
|
### Local models
|
||||||
here.
|
|
||||||
|
|
||||||

|
- Pros:
|
||||||
|
- Privacy. Your documents will be stored and process locally.
|
||||||
|
- Choices. There are a wide range of LLMs in terms of size, domain, language to choose
|
||||||
|
from.
|
||||||
|
- Cost. It's free.
|
||||||
|
- Cons:
|
||||||
|
- Quality. Local models are much smaller and thus have lower generative quality than
|
||||||
|
paid APIs.
|
||||||
|
- Speed. Local models are deployed using your machine so the processing speed is
|
||||||
|
limited by your hardware.
|
||||||
|
|
||||||
## File index tab
|
#### Find and download a LLM
|
||||||
|
|
||||||

|
You can search and download a LLM to be ran locally from the [Hugging Face
|
||||||
|
Hub](https://huggingface.co/models). Currently, these model formats are supported:
|
||||||
|
|
||||||
### File upload
|
- GGUF
|
||||||
|
|
||||||
In order for a file to be used as an index for retrieval, it must be processed by the
|
You should choose a model whose size is less than your device's memory and should leave
|
||||||
application first. Do this uploading your file to the UI and then select `Upload and Index`.
|
about 2 GB. For example, if you have 16 GB of RAM in total, of which 12 GB is available,
|
||||||
|
then you should choose a model that take up at most 10 GB of RAM. Bigger models tend to
|
||||||
|
give better generation but also take more processing time.
|
||||||
|
|
||||||

|
Here are some recommendations and their size in memory:
|
||||||
|
|
||||||
The application will take some time to process the file and show a message once it is
|
- [Qwen1.5-1.8B-Chat-GGUF](https://huggingface.co/Qwen/Qwen1.5-1.8B-Chat-GGUF/resolve/main/qwen1_5-1_8b-chat-q8_0.gguf?download=true):
|
||||||
done. Then you will be able to select it in the [File index section](#file-index) of the [Chat tab](#chat-tab).
|
around 2 GB
|
||||||
|
|
||||||
### File list
|
#### Enable local models
|
||||||
|
|
||||||
This section shows the list of files that have been uploaded to the application and
|
To add a local model to the model pool, set the `LOCAL_MODEL` variable in the `.env`
|
||||||
allows users to delete them.
|
file to the path of the model file.
|
||||||
|
|
||||||

|
```shell
|
||||||
|
LOCAL_MODEL=<full path to your model file>
|
||||||
|
```
|
||||||
|
|
||||||
|
Here is how to get the full path of your model file:
|
||||||
|
|
||||||
|
- On Windows 11: right click the file and select `Copy as Path`.
|
||||||
|
</details>
|
||||||
|
|
||||||
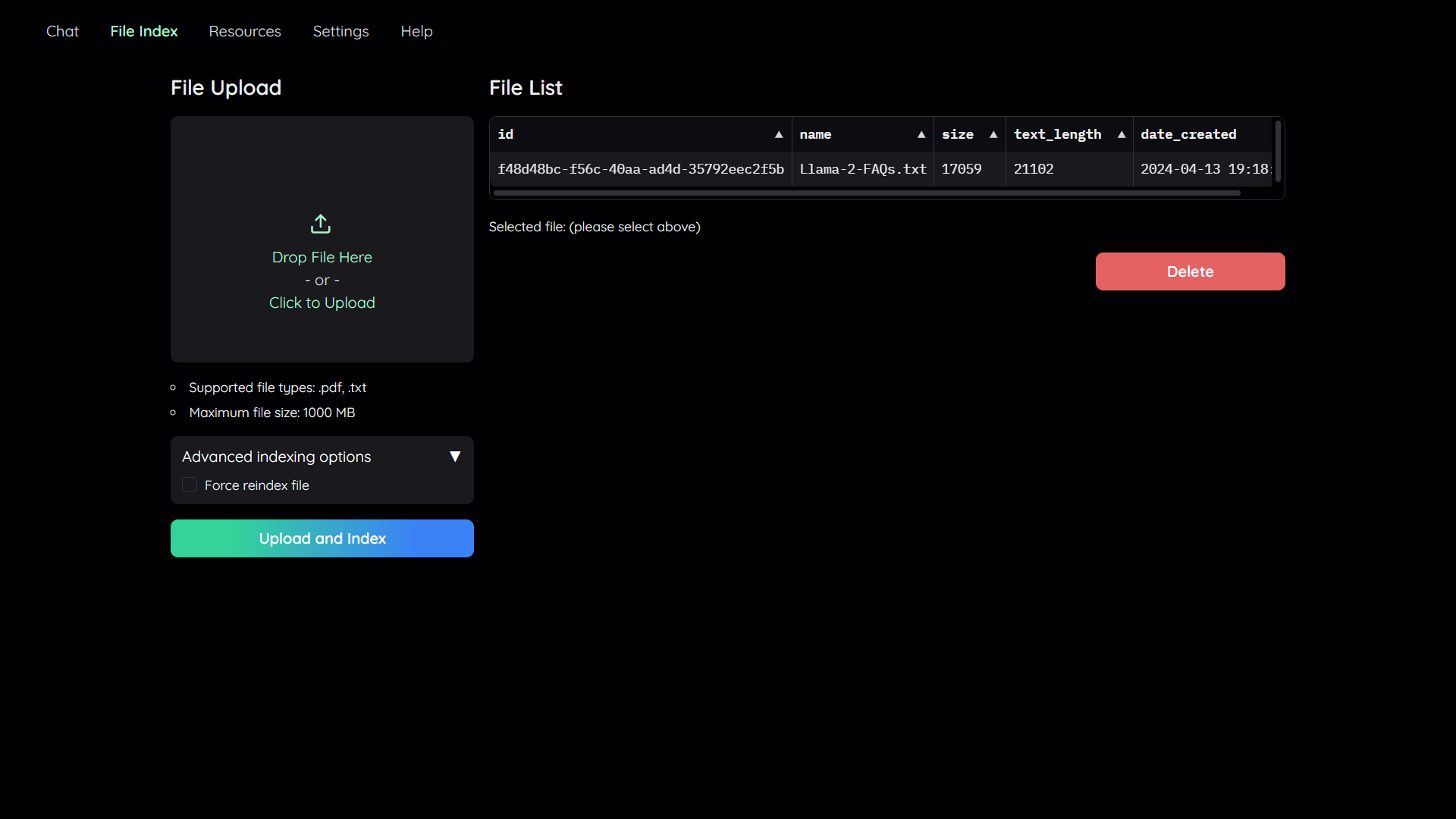
|
## Upload your documents
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
In order to do QA on your documents, you need to upload them to the application first.
|
||||||
|
Navigate to the `File Index` tab and you will see 2 sections:
|
||||||
|
|
||||||
|
1. File upload:
|
||||||
|
- Drag and drop your file to the UI or select it from your file system.
|
||||||
|
Then click `Upload and Index`.
|
||||||
|
- The application will take some time to process the file and show a message once it is done.
|
||||||
|
2. File list:
|
||||||
|
- This section shows the list of files that have been uploaded to the application and allows users to delete them.
|
||||||
|
|
||||||
|
## Chat with your documents
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
Now navigate back to the `Chat` tab. The chat tab is divided into 3 regions:
|
||||||
|
|
||||||
|
1. Conversation Settings Panel
|
||||||
|
- Here you can select, create, rename, and delete conversations.
|
||||||
|
- By default, a new conversation is created automatically if no conversation is selected.
|
||||||
|
- Below that you have the file index, where you can select which files to retrieve references from.
|
||||||
|
- These are the files you have uploaded to the application from the `File Index` tab.
|
||||||
|
- If no file is selected, all files will be used.
|
||||||
|
2. Chat Panel
|
||||||
|
- This is where you can chat with the chatbot.
|
||||||
|
3. Information panel
|
||||||
|
- Supporting information such as the retrieved evidence and reference will be
|
||||||
|
displayed here.
|
||||||
|
|||||||
@@ -1,3 +1,7 @@
|
|||||||
|
:root {
|
||||||
|
--main-area-height: calc(100vh - 110px);
|
||||||
|
}
|
||||||
|
|
||||||
/* no footer */
|
/* no footer */
|
||||||
footer {
|
footer {
|
||||||
display: none !important;
|
display: none !important;
|
||||||
@@ -14,11 +18,13 @@ footer {
|
|||||||
background-clip: content-box;
|
background-clip: content-box;
|
||||||
}
|
}
|
||||||
::-webkit-scrollbar-corner {
|
::-webkit-scrollbar-corner {
|
||||||
background: var(--border-color-primary);
|
background: var(--background-fill-primary);
|
||||||
}
|
}
|
||||||
|
|
||||||
.gradio-container {
|
.gradio-container {
|
||||||
max-width: 100% !important;
|
max-width: 100% !important;
|
||||||
|
/* overflow: scroll !important;
|
||||||
|
height: 100% !important; */
|
||||||
}
|
}
|
||||||
|
|
||||||
/* styling for header bar */
|
/* styling for header bar */
|
||||||
@@ -70,15 +76,25 @@ button.selected {
|
|||||||
}
|
}
|
||||||
|
|
||||||
#main-chat-bot {
|
#main-chat-bot {
|
||||||
/* span the chat area to occupy full height minus space for chat input */
|
flex: 1;
|
||||||
height: calc(100vh - 180px) !important;
|
}
|
||||||
|
|
||||||
|
#chat-area {
|
||||||
|
height: var(--main-area-height) !important;
|
||||||
}
|
}
|
||||||
|
|
||||||
#chat-info-panel {
|
#chat-info-panel {
|
||||||
max-height: calc(100vh - 180px) !important;
|
max-height: var(--main-area-height) !important;
|
||||||
overflow-y: scroll !important;
|
overflow-y: scroll !important;
|
||||||
}
|
}
|
||||||
|
|
||||||
|
#conv-settings-panel {
|
||||||
|
max-height: var(--main-area-height) !important;
|
||||||
|
flex-wrap: unset;
|
||||||
|
overflow-y: scroll !important;
|
||||||
|
position: sticky;
|
||||||
|
}
|
||||||
|
|
||||||
.setting-answer-mode-description {
|
.setting-answer-mode-description {
|
||||||
margin: 5px 5px 2px !important;
|
margin: 5px 5px 2px !important;
|
||||||
}
|
}
|
||||||
@@ -124,6 +140,18 @@ button.selected {
|
|||||||
}
|
}
|
||||||
|
|
||||||
/* for setting height limit for buttons */
|
/* for setting height limit for buttons */
|
||||||
.cap-height {
|
.cap-button-height {
|
||||||
max-height: 42px;
|
max-height: 42px;
|
||||||
}
|
}
|
||||||
|
|
||||||
|
.scrollable {
|
||||||
|
overflow-y: auto;
|
||||||
|
}
|
||||||
|
|
||||||
|
.fill-main-area-height {
|
||||||
|
max-height: var(--main-area-height);
|
||||||
|
}
|
||||||
|
|
||||||
|
.unset-overflow {
|
||||||
|
overflow: unset !important;
|
||||||
|
}
|
||||||
|
|||||||
@@ -101,15 +101,16 @@ class FileIndexPage(BasePage):
|
|||||||
with gr.Column(scale=1):
|
with gr.Column(scale=1):
|
||||||
gr.Markdown("## File Upload")
|
gr.Markdown("## File Upload")
|
||||||
with gr.Column() as self.upload:
|
with gr.Column() as self.upload:
|
||||||
msg = self.upload_instruction()
|
|
||||||
if msg:
|
|
||||||
gr.Markdown(msg)
|
|
||||||
|
|
||||||
self.files = File(
|
self.files = File(
|
||||||
file_types=self._supported_file_types,
|
file_types=self._supported_file_types,
|
||||||
file_count="multiple",
|
file_count="multiple",
|
||||||
container=True,
|
container=True,
|
||||||
)
|
)
|
||||||
|
|
||||||
|
msg = self.upload_instruction()
|
||||||
|
if msg:
|
||||||
|
gr.Markdown(msg)
|
||||||
|
|
||||||
with gr.Accordion("Advanced indexing options", open=True):
|
with gr.Accordion("Advanced indexing options", open=True):
|
||||||
with gr.Row():
|
with gr.Row():
|
||||||
self.reindex = gr.Checkbox(
|
self.reindex = gr.Checkbox(
|
||||||
@@ -346,7 +347,7 @@ class FileIndexPage(BasePage):
|
|||||||
# download the file
|
# download the file
|
||||||
text = "\n\n".join([each.text for each in output_nodes])
|
text = "\n\n".join([each.text for each in output_nodes])
|
||||||
handler, file_path = tempfile.mkstemp(suffix=".txt")
|
handler, file_path = tempfile.mkstemp(suffix=".txt")
|
||||||
with open(file_path, "w") as f:
|
with open(file_path, "w", encoding="utf-8") as f:
|
||||||
f.write(text)
|
f.write(text)
|
||||||
os.close(handler)
|
os.close(handler)
|
||||||
|
|
||||||
|
|||||||
@@ -1,8 +1,8 @@
|
|||||||
import gradio as gr
|
import gradio as gr
|
||||||
from ktem.app import BaseApp
|
from ktem.app import BaseApp
|
||||||
from ktem.pages.admin import AdminPage
|
|
||||||
from ktem.pages.chat import ChatPage
|
from ktem.pages.chat import ChatPage
|
||||||
from ktem.pages.help import HelpPage
|
from ktem.pages.help import HelpPage
|
||||||
|
from ktem.pages.resources import ResourcesTab
|
||||||
from ktem.pages.settings import SettingsPage
|
from ktem.pages.settings import SettingsPage
|
||||||
|
|
||||||
|
|
||||||
@@ -57,14 +57,16 @@ class App(BaseApp):
|
|||||||
elem_id="resources-tab",
|
elem_id="resources-tab",
|
||||||
id="resources-tab",
|
id="resources-tab",
|
||||||
visible=not self.f_user_management,
|
visible=not self.f_user_management,
|
||||||
|
elem_classes=["fill-main-area-height", "scrollable"],
|
||||||
) as self._tabs["resources-tab"]:
|
) as self._tabs["resources-tab"]:
|
||||||
self.admin_page = AdminPage(self)
|
self.resources_page = ResourcesTab(self)
|
||||||
|
|
||||||
with gr.Tab(
|
with gr.Tab(
|
||||||
"Settings",
|
"Settings",
|
||||||
elem_id="settings-tab",
|
elem_id="settings-tab",
|
||||||
id="settings-tab",
|
id="settings-tab",
|
||||||
visible=not self.f_user_management,
|
visible=not self.f_user_management,
|
||||||
|
elem_classes=["fill-main-area-height", "scrollable"],
|
||||||
) as self._tabs["settings-tab"]:
|
) as self._tabs["settings-tab"]:
|
||||||
self.settings_page = SettingsPage(self)
|
self.settings_page = SettingsPage(self)
|
||||||
|
|
||||||
@@ -73,6 +75,7 @@ class App(BaseApp):
|
|||||||
elem_id="help-tab",
|
elem_id="help-tab",
|
||||||
id="help-tab",
|
id="help-tab",
|
||||||
visible=not self.f_user_management,
|
visible=not self.f_user_management,
|
||||||
|
elem_classes=["fill-main-area-height", "scrollable"],
|
||||||
) as self._tabs["help-tab"]:
|
) as self._tabs["help-tab"]:
|
||||||
self.help_page = HelpPage(self)
|
self.help_page = HelpPage(self)
|
||||||
|
|
||||||
|
|||||||
@@ -27,7 +27,7 @@ class ChatPage(BasePage):
|
|||||||
def on_building_ui(self):
|
def on_building_ui(self):
|
||||||
with gr.Row():
|
with gr.Row():
|
||||||
self.chat_state = gr.State(STATE)
|
self.chat_state = gr.State(STATE)
|
||||||
with gr.Column(scale=1):
|
with gr.Column(scale=1, elem_id="conv-settings-panel"):
|
||||||
self.chat_control = ConversationControl(self._app)
|
self.chat_control = ConversationControl(self._app)
|
||||||
|
|
||||||
if getattr(flowsettings, "KH_FEATURE_CHAT_SUGGESTION", False):
|
if getattr(flowsettings, "KH_FEATURE_CHAT_SUGGESTION", False):
|
||||||
@@ -60,7 +60,7 @@ class ChatPage(BasePage):
|
|||||||
|
|
||||||
self.report_issue = ReportIssue(self._app)
|
self.report_issue = ReportIssue(self._app)
|
||||||
|
|
||||||
with gr.Column(scale=6):
|
with gr.Column(scale=6, elem_id="chat-area"):
|
||||||
self.chat_panel = ChatPanel(self._app)
|
self.chat_panel = ChatPanel(self._app)
|
||||||
|
|
||||||
with gr.Column(scale=3):
|
with gr.Column(scale=3):
|
||||||
|
|||||||
@@ -22,19 +22,20 @@ class ChatPanel(BasePage):
|
|||||||
placeholder="Chat input",
|
placeholder="Chat input",
|
||||||
scale=15,
|
scale=15,
|
||||||
container=False,
|
container=False,
|
||||||
|
max_lines=10,
|
||||||
)
|
)
|
||||||
self.submit_btn = gr.Button(
|
self.submit_btn = gr.Button(
|
||||||
value="Send",
|
value="Send",
|
||||||
scale=1,
|
scale=1,
|
||||||
min_width=10,
|
min_width=10,
|
||||||
variant="primary",
|
variant="primary",
|
||||||
elem_classes=["cap-height"],
|
elem_classes=["cap-button-height"],
|
||||||
)
|
)
|
||||||
self.regen_btn = gr.Button(
|
self.regen_btn = gr.Button(
|
||||||
value="Regen",
|
value="Regen",
|
||||||
scale=1,
|
scale=1,
|
||||||
min_width=10,
|
min_width=10,
|
||||||
elem_classes=["cap-height"],
|
elem_classes=["cap-button-height"],
|
||||||
)
|
)
|
||||||
|
|
||||||
def submit_msg(self, chat_input, chat_history):
|
def submit_msg(self, chat_input, chat_history):
|
||||||
|
|||||||
@@ -37,6 +37,7 @@ class ConversationControl(BasePage):
|
|||||||
container=False,
|
container=False,
|
||||||
filterable=False,
|
filterable=False,
|
||||||
interactive=True,
|
interactive=True,
|
||||||
|
elem_classes=["unset-overflow"],
|
||||||
)
|
)
|
||||||
|
|
||||||
with gr.Row() as self._new_delete:
|
with gr.Row() as self._new_delete:
|
||||||
|
|||||||
@@ -28,8 +28,10 @@ class ReportIssue(BasePage):
|
|||||||
label="Other issue:",
|
label="Other issue:",
|
||||||
)
|
)
|
||||||
self.more_detail = gr.Textbox(
|
self.more_detail = gr.Textbox(
|
||||||
placeholder="More detail (e.g. how wrong is it, what is the "
|
placeholder=(
|
||||||
"correct answer, etc...)",
|
"More detail (e.g. how wrong is it, what is the "
|
||||||
|
"correct answer, etc...)"
|
||||||
|
),
|
||||||
container=False,
|
container=False,
|
||||||
lines=3,
|
lines=3,
|
||||||
)
|
)
|
||||||
|
|||||||
@@ -7,18 +7,15 @@ class HelpPage:
|
|||||||
def __init__(self, app):
|
def __init__(self, app):
|
||||||
self._app = app
|
self._app = app
|
||||||
self.dir_md = Path(__file__).parent.parent / "assets" / "md"
|
self.dir_md = Path(__file__).parent.parent / "assets" / "md"
|
||||||
|
self.doc_dir = Path(__file__).parents[4] / "docs"
|
||||||
|
|
||||||
|
with gr.Accordion("User Guide"):
|
||||||
|
with (self.doc_dir / "usage.md").open(encoding="utf-8") as fi:
|
||||||
|
gr.Markdown(fi.read())
|
||||||
|
|
||||||
with gr.Accordion("Changelogs"):
|
with gr.Accordion("Changelogs"):
|
||||||
gr.Markdown(self.get_changelogs())
|
gr.Markdown(self.get_changelogs())
|
||||||
|
|
||||||
with gr.Accordion("About Kotaemon (temporary)"):
|
|
||||||
with (self.dir_md / "about_kotaemon.md").open(encoding="utf-8") as fi:
|
|
||||||
gr.Markdown(fi.read())
|
|
||||||
|
|
||||||
with gr.Accordion("About Cinnamon AI (temporary)", open=False):
|
|
||||||
with (self.dir_md / "about_cinnamon.md").open(encoding="utf-8") as fi:
|
|
||||||
gr.Markdown(fi.read())
|
|
||||||
|
|
||||||
def get_changelogs(self):
|
def get_changelogs(self):
|
||||||
with (self.dir_md / "changelogs.md").open(encoding="utf-8") as fi:
|
with (self.dir_md / "changelogs.md").open(encoding="utf-8") as fi:
|
||||||
return fi.read()
|
return fi.read()
|
||||||
|
|||||||
@@ -8,7 +8,7 @@ from sqlmodel import Session, select
|
|||||||
from .user import UserManagement
|
from .user import UserManagement
|
||||||
|
|
||||||
|
|
||||||
class AdminPage(BasePage):
|
class ResourcesTab(BasePage):
|
||||||
def __init__(self, app):
|
def __init__(self, app):
|
||||||
self._app = app
|
self._app = app
|
||||||
self.on_building_ui()
|
self.on_building_ui()
|
||||||
@@ -21,7 +21,7 @@ class AdminPage(BasePage):
|
|||||||
with gr.Tab("LLMs") as self.llm_management_tab:
|
with gr.Tab("LLMs") as self.llm_management_tab:
|
||||||
self.llm_management = LLMManagement(self._app)
|
self.llm_management = LLMManagement(self._app)
|
||||||
|
|
||||||
with gr.Tab("Embeddings") as self.llm_management_tab:
|
with gr.Tab("Embedding Models") as self.llm_management_tab:
|
||||||
self.emb_management = EmbeddingManagement(self._app)
|
self.emb_management = EmbeddingManagement(self._app)
|
||||||
|
|
||||||
def on_subscribe_public_events(self):
|
def on_subscribe_public_events(self):
|
||||||
@@ -20,6 +20,7 @@ nav:
|
|||||||
- Customize UI: pages/app/customize-ui.md
|
- Customize UI: pages/app/customize-ui.md
|
||||||
- Functional description: pages/app/functional-description.md
|
- Functional description: pages/app/functional-description.md
|
||||||
- Development:
|
- Development:
|
||||||
|
- development/index.md
|
||||||
- Contributing: development/contributing.md
|
- Contributing: development/contributing.md
|
||||||
- Data & Data Structure Components: development/data-components.md
|
- Data & Data Structure Components: development/data-components.md
|
||||||
- Creating a Component: development/create-a-component.md
|
- Creating a Component: development/create-a-component.md
|
||||||
|
|||||||