* Support hybrid vector retrieval * Enable figures and table reading in Azure DI * Retrieve with multi-modal * Fix mixing up table * Add txt loader * Add Anthropic Chat * Raising error when retrieving help file * Allow same filename for different people if private is True * Allow declaring extra LLM vendors * Show chunks on the File page * Allow elasticsearch to get more docs * Fix Cohere response (#86) * Fix Cohere response * Remove Adobe pdfservice from dependency kotaemon doesn't rely more pdfservice for its core functionality, and pdfservice uses very out-dated dependency that causes conflict. --------- Co-authored-by: trducng <trungduc1992@gmail.com> * Add confidence score (#87) * Save question answering data as a log file * Save the original information besides the rewritten info * Export Cohere relevance score as confidence score * Fix style check * Upgrade the confidence score appearance (#90) * Highlight the relevance score * Round relevance score. Get key from config instead of env * Cohere return all scores * Display relevance score for image * Remove columns and rows in Excel loader which contains all NaN (#91) * remove columns and rows which contains all NaN * back to multiple joiner options * Fix style --------- Co-authored-by: linhnguyen-cinnamon <cinmc0019@CINMC0019-LinhNguyen.local> Co-authored-by: trducng <trungduc1992@gmail.com> * Track retriever state * Bump llama-index version 0.10 * feat/save-azuredi-mhtml-to-markdown (#93) * feat/save-azuredi-mhtml-to-markdown * fix: replace os.path to pathlib change theflow.settings * refactor: base on pre-commit * chore: move the func of saving content markdown above removed_spans --------- Co-authored-by: jacky0218 <jacky0218@github.com> * fix: losing first chunk (#94) * fix: losing first chunk. * fix: update the method of preventing losing chunks --------- Co-authored-by: jacky0218 <jacky0218@github.com> * fix: adding the base64 image in markdown (#95) * feat: more chunk info on UI * fix: error when reindexing files * refactor: allow more information exception trace when using gpt4v * feat: add excel reader that treats each worksheet as a document * Persist loader information when indexing file * feat: allow hiding unneeded setting panels * feat: allow specific timezone when creating conversation * feat: add more confidence score (#96) * Allow a list of rerankers * Export llm reranking score instead of filter with boolean * Get logprobs from LLMs * Rename cohere reranking score * Call 2 rerankers at once * Run QA pipeline for each chunk to get qa_score * Display more relevance scores * Define another LLMScoring instead of editing the original one * Export logprobs instead of probs * Call LLMScoring * Get qa_score only in the final answer * feat: replace text length with token in file list * ui: show index name instead of id in the settings * feat(ai): restrict the vision temperature * fix(ui): remove the misleading message about non-retrieved evidences * feat(ui): show the reasoning name and description in the reasoning setting page * feat(ui): show version on the main windows * feat(ui): show default llm name in the setting page * fix(conf): append the result of doc in llm_scoring (#97) * fix: constraint maximum number of images * feat(ui): allow filter file by name in file list page * Fix exceeding token length error for OpenAI embeddings by chunking then averaging (#99) * Average embeddings in case the text exceeds max size * Add docstring * fix: Allow empty string when calling embedding * fix: update trulens LLM ranking score for retrieval confidence, improve citation (#98) * Round when displaying not by default * Add LLMTrulens reranking model * Use llmtrulensscoring in pipeline * fix: update UI display for trulen score --------- Co-authored-by: taprosoft <tadashi@cinnamon.is> * feat: add question decomposition & few-shot rewrite pipeline (#89) * Create few-shot query-rewriting. Run and display the result in info_panel * Fix style check * Put the functions to separate modules * Add zero-shot question decomposition * Fix fewshot rewriting * Add default few-shot examples * Fix decompose question * Fix importing rewriting pipelines * fix: update decompose logic in fullQA pipeline --------- Co-authored-by: taprosoft <tadashi@cinnamon.is> * fix: add encoding utf-8 when save temporal markdown in vectorIndex (#101) * fix: improve retrieval pipeline and relevant score display (#102) * fix: improve retrieval pipeline by extending first round top_k with multiplier * fix: minor fix * feat: improve UI default settings and add quick switch option for pipeline * fix: improve agent logics (#103) * fix: improve agent progres display * fix: update retrieval logic * fix: UI display * fix: less verbose debug log * feat: add warning message for low confidence * fix: LLM scoring enabled by default * fix: minor update logics * fix: hotfix image citation * feat: update docx loader for handle merged table cells + handle zip file upload (#104) * feat: update docx loader for handle merged table cells * feat: handle zip file * refactor: pre-commit * fix: escape text in download UI * feat: optimize vector store query db (#105) * feat: optimize vector store query db * feat: add file_id to chroma metadatas * feat: remove unnecessary logs and update migrate script * feat: iterate through file index * fix: remove unused code --------- Co-authored-by: taprosoft <tadashi@cinnamon.is> * fix: add openai embedidng exponential back-off * fix: update import download_loader * refactor: codespell * fix: update some default settings * fix: update installation instruction * fix: default chunk length in simple QA * feat: add share converstation feature and enable retrieval history (#108) * feat: add share converstation feature and enable retrieval history * fix: update share conversation UI --------- Co-authored-by: taprosoft <tadashi@cinnamon.is> * fix: allow exponential backoff for failed OCR call (#109) * fix: update default prompt when no retrieval is used * fix: create embedding for long image chunks * fix: add exception handling for additional table retriever * fix: clean conversation & file selection UI * fix: elastic search with empty doc_ids * feat: add thumbnail PDF reader for quick multimodal QA * feat: add thumbnail handling logic in indexing * fix: UI text update * fix: PDF thumb loader page number logic * feat: add quick indexing pipeline and update UI * feat: add conv name suggestion * fix: minor UI change * feat: citation in thread * fix: add conv name suggestion in regen * chore: add assets for usage doc * chore: update usage doc * feat: pdf viewer (#110) * feat: update pdfviewer * feat: update missing files * fix: update rendering logic of infor panel * fix: improve thumbnail retrieval logic * fix: update PDF evidence rendering logic * fix: remove pdfjs built dist * fix: reduce thumbnail evidence count * chore: update gitignore * fix: add js event on chat msg select * fix: update css for viewer * fix: add env var for PDFJS prebuilt * fix: move language setting to reasoning utils --------- Co-authored-by: phv2312 <kat87yb@gmail.com> Co-authored-by: trducng <trungduc1992@gmail.com> * feat: graph rag (#116) * fix: reload server when add/delete index * fix: rework indexing pipeline to be able to disable vectorstore and splitter if needed * feat: add graphRAG index with plot view * fix: update requirement for graphRAG and lighten unnecessary packages * feat: add knowledge network index (#118) * feat: add Knowledge Network index * fix: update reader mode setting for knet * fix: update init knet * fix: update collection name to index pipeline * fix: missing req --------- Co-authored-by: jeff52415 <jeff.yang@cinnamon.is> * fix: update info panel return for graphrag * fix: retriever setting graphrag * feat: local llm settings (#122) * feat: expose context length as reasoning setting to better fit local models * fix: update context length setting for agents * fix: rework threadpool llm call * fix: fix improve indexing logic * fix: fix improve UI * feat: add lancedb * fix: improve lancedb logic * feat: add lancedb vectorstore * fix: lighten requirement * fix: improve lanceDB vs * fix: improve UI * fix: openai retry * fix: update reqs * fix: update launch command * feat: update Dockerfile * feat: add plot history * fix: update default config * fix: remove verbose print * fix: update default setting * fix: update gradio plot return * fix: default gradio tmp * fix: improve lancedb docstore * fix: fix question decompose pipeline * feat: add multimodal reader in UI * fix: udpate docs * fix: update default settings & docker build * fix: update app startup * chore: update documentation * chore: update README * chore: update README --------- Co-authored-by: trducng <trungduc1992@gmail.com> * chore: update README * chore: update README --------- Co-authored-by: trducng <trungduc1992@gmail.com> Co-authored-by: cin-ace <ace@cinnamon.is> Co-authored-by: Linh Nguyen <70562198+linhnguyen-cinnamon@users.noreply.github.com> Co-authored-by: linhnguyen-cinnamon <cinmc0019@CINMC0019-LinhNguyen.local> Co-authored-by: cin-jacky <101088014+jacky0218@users.noreply.github.com> Co-authored-by: jacky0218 <jacky0218@github.com> Co-authored-by: kan_cin <kan@cinnamon.is> Co-authored-by: phv2312 <kat87yb@gmail.com> Co-authored-by: jeff52415 <jeff.yang@cinnamon.is>
9.7 KiB
kotaemon
An open-source clean & customizable RAG UI for chatting with your documents. Built with both end users and developers in mind.

User Guide | Developer Guide | Feedback
![]()
![]()
Introduction
This project serves as a functional RAG UI for both end users who want to do QA on their documents and developers who want to build their own RAG pipeline.
- For end users:
- A clean & minimalistic UI for RAG-based QA.
- Supports LLM API providers (OpenAI, AzureOpenAI, Cohere, etc) and local LLMs
(via
ollamaandllama-cpp-python). - Easy installation scripts.
- For developers:
- A framework for building your own RAG-based document QA pipeline.
- Customize and see your RAG pipeline in action with the provided UI (built with Gradio).
+----------------------------------------------------------------------------+
| End users: Those who use apps built with `kotaemon`. |
| (You use an app like the one in the demo above) |
| +----------------------------------------------------------------+ |
| | Developers: Those who built with `kotaemon`. | |
| | (You have `import kotaemon` somewhere in your project) | |
| | +----------------------------------------------------+ | |
| | | Contributors: Those who make `kotaemon` better. | | |
| | | (You make PR to this repo) | | |
| | +----------------------------------------------------+ | |
| +----------------------------------------------------------------+ |
+----------------------------------------------------------------------------+
This repository is under active development. Feedback, issues, and PRs are highly appreciated.
Key Features
-
Host your own document QA (RAG) web-UI. Support multi-user login, organize your files in private / public collections, collaborate and share your favorite chat with others.
-
Organize your LLM & Embedding models. Support both local LLMs & popular API providers (OpenAI, Azure, Ollama, Groq).
-
Hybrid RAG pipeline. Sane default RAG pipeline with hybrid (full-text & vector) retriever + re-ranking to ensure best retrieval quality.
-
Multi-modal QA support. Perform Question Answering on multiple documents with figures & tables support. Support multi-modal document parsing (selectable options on UI).
-
Advance citations with document preview. By default the system will provide detailed citations to ensure the correctness of LLM answers. View your citations (incl. relevant score) directly in the in-browser PDF viewer with highlights. Warning when retrieval pipeline return low relevant articles.
-
Support complex reasoning methods. Use question decomposition to answer your complex / multi-hop question. Support agent-based reasoning with ReAct, ReWOO and other agents.
-
Configurable settings UI. You can adjust most important aspects of retrieval & generation process on the UI (incl. prompts).
-
Extensible. Being built on Gradio, you are free to customize / add any UI elements as you like. Also, we aim to support multiple strategies for document indexing & retrieval.
GraphRAGindexing pipeline is provided as an example.

Installation
For end users
This document is intended for developers. If you just want to install and use the app as it is, please follow the non-technical User Guide (WIP).
For developers
With Docker (recommended)
- Use this command to launch the server
docker run \
-e GRADIO_SERVER_NAME=0.0.0.0 \
-e GRADIO_SERVER_PORT=7860 \
-p 7860:7860 -it --rm \
taprosoft/kotaemon:v1.0
Navigate to http://localhost:7860/ to access the web UI.
Without Docker
- Clone and install required packages on a fresh python environment.
# optional (setup env)
conda create -n kotaemon python=3.10
conda activate kotaemon
# clone this repo
git clone https://github.com/Cinnamon/kotaemon
cd kotaemon
pip install -e "libs/kotaemon[all]"
pip install -e "libs/ktem"
-
View and edit your environment variables (API keys, end-points) in
.env. -
(Optional) To enable in-browser PDF_JS viewer, download PDF_JS_DIST and extract it to
libs/ktem/ktem/assets/prebuilt
- Start the web server:
python app.py
The app will be automatically launched in your browser.
Default username / password are: admin / admin. You can setup additional users directly on the UI.

Customize your application
By default, all application data are stored in ./ktem_app_data folder. You can backup or copy this folder to move your installation to a new machine.
For advance users or specific use-cases, you can customize those files:
flowsettings.py.env
flowsettings.py
This file contains the configuration of your application. You can use the example here as the starting point.
Notable settings
# setup your preferred document store (with full-text search capabilities)
KH_DOCSTORE=(Elasticsearch | LanceDB | SimpleFileDocumentStore)
# setup your preferred vectorstore (for vector-based search)
KH_VECTORSTORE=(ChromaDB | LanceDB
# Enable / disable multimodal QA
KH_REASONINGS_USE_MULTIMODAL=True
# Setup your new reasoning pipeline or modify existing one.
KH_REASONINGS = [
"ktem.reasoning.simple.FullQAPipeline",
"ktem.reasoning.simple.FullDecomposeQAPipeline",
"ktem.reasoning.react.ReactAgentPipeline",
"ktem.reasoning.rewoo.RewooAgentPipeline",
]
)
.env
This file provides another way to configure your models and credentials.
Configure model via the .env file
Alternatively, you can configure the models via the .env file with the information needed to connect to the LLMs. This file is located in
the folder of the application. If you don't see it, you can create one.
Currently, the following providers are supported:
OpenAI
In the .env file, set the OPENAI_API_KEY variable with your OpenAI API key in order
to enable access to OpenAI's models. There are other variables that can be modified,
please feel free to edit them to fit your case. Otherwise, the default parameter should
work for most people.
OPENAI_API_BASE=https://api.openai.com/v1
OPENAI_API_KEY=<your OpenAI API key here>
OPENAI_CHAT_MODEL=gpt-3.5-turbo
OPENAI_EMBEDDINGS_MODEL=text-embedding-ada-002
Azure OpenAI
For OpenAI models via Azure platform, you need to provide your Azure endpoint and API key. Your might also need to provide your developments' name for the chat model and the embedding model depending on how you set up Azure development.
AZURE_OPENAI_ENDPOINT=
AZURE_OPENAI_API_KEY=
OPENAI_API_VERSION=2024-02-15-preview
AZURE_OPENAI_CHAT_DEPLOYMENT=gpt-35-turbo
AZURE_OPENAI_EMBEDDINGS_DEPLOYMENT=text-embedding-ada-002
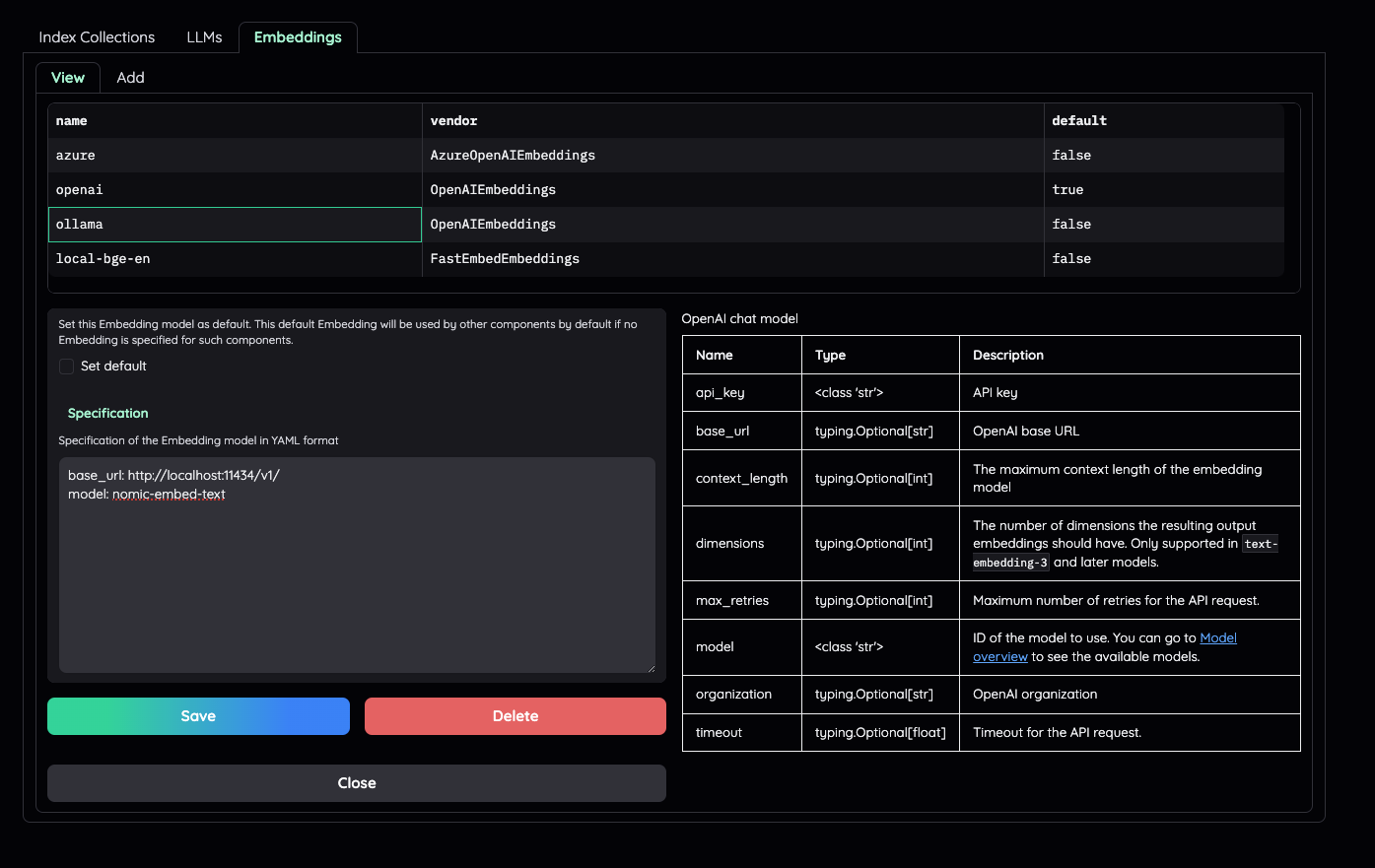
Local models
Using ollama OpenAI compatible server
Install ollama and start the application.
Pull your model (e.g):
ollama pull llama3.1:8b
ollama pull nomic-embed-text
Set the model names on web UI and make it as default.
Using GGUF with llama-cpp-python
You can search and download a LLM to be ran locally from the Hugging Face Hub. Currently, these model formats are supported:
- GGUF
You should choose a model whose size is less than your device's memory and should leave about 2 GB. For example, if you have 16 GB of RAM in total, of which 12 GB is available, then you should choose a model that takes up at most 10 GB of RAM. Bigger models tend to give better generation but also take more processing time.
Here are some recommendations and their size in memory:
- Qwen1.5-1.8B-Chat-GGUF: around 2 GB
Add a new LlamaCpp model with the provided model name on the web uI.
Adding your own RAG pipeline
Custom reasoning pipeline
First, check the default pipeline implementation in here. You can make quick adjustment to how the default QA pipeline work.
Next, if you feel comfortable adding new pipeline, add new .py implementation in libs/ktem/ktem/reasoning/ and later include it in flowssettings to enable it on the UI.
Custom indexing pipeline
Check sample implementation in libs/ktem/ktem/index/file/graph
(more instruction WIP).
Developer guide
Please refer to the Developer Guide for more details.